Pandas of the beginner, by the beginner, for the beginner [Python]
Before reading this article
This is a summary of what I wrote so that I will not forget it, with a little information added. If it is difficult to read or understand, please comment as we will correct it.
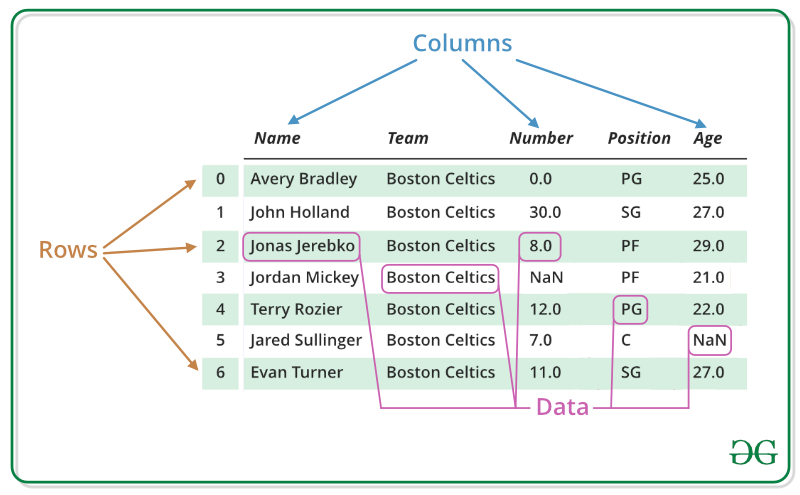 Quoted from: https://www.geeksforgeeks.org/python-pandas-dataframe/
Quoted from: https://www.geeksforgeeks.org/python-pandas-dataframe/
Development environment to use
- anaconda
- Pycharm
- Python3.7.7
Edit history -2020/04/05 -2020/04/05 --Addition: Delete data
Before starting Pandas
#Install, import
pip install pandas
import pandas as pd
Let's actually play with pandas.
Get data
If you want to do something with pandas, you need to get it. Prepare it as csv. This time, I will use a person infected with coronavirus (Hyogo prefecture).
url = "https://web.pref.hyogo.lg.jp/kk03/corona_hasseijyokyo.html"
dfs = pd.read_html(url)
print(dfs[0].head())
#Display HTML table at prompt
>>>
0 1 2 3 4 5 6
0 Number Age Gender Residence Occupation Date of Announcement Remarks
1 162 40 Male Kobe City Doctor April 1 NaN
2 161 20 Male Itami Health and Welfare Office Jurisdiction Company Employee April 1 NaN
3 160 50 Female Takarazuka City Unemployed April 1 NaN
4 159 60 Male Takarazuka City Doctor April 1 NaN
#Make the table on HTML csv.
#Text editor
import csv
tables = pd.read_html("https://web.pref.hyogo.lg.jp/kk03/corona_hasseijyokyo.html", header=0)
data = tables[0]
data.to_csv("coronaHyogo.csv", index=False) #output
Read CSV
dfs = pd.read_csv('C:/Users/Desktop/coronaHyogo.csv')
print (dfs)
#Open CSV in pandas
>>>
Number Age Gender Place of residence Occupation Date of announcement Remarks
0 169 40 Male Amagasaki City Office worker April 2 NaN
1 168 60 Male Ashiya City Office worker April 2 NaN
2 167 50 Male Itami Health and Welfare Office Jurisdiction Company Employee April 2 NaN
3 166 20 Female Itami City NaN April 2 NaN
4 165 20 Male Akashi City NaN April 2 NaN
.. ... .. .. ... ... ... ...
64 105 70 Male Itami City Unemployed March 21 NaN
65 104 80 Female Takarazuka City Unemployed March 21 Death
66 103 60 Male Amagasaki City Office worker March 21 NaN
67 102 40 Female returnees (announced by Himeji City Health Center) Unemployed March 21 NaN
68 101 20 Male Amagasaki City Student March 20 NaN
Data confirmation
dfs.shape #Check the number of rows and columns in the dataframe
>>> (69, 7)
dfs.index #Check index
>>> RangeIndex(start=0, stop=69, step=1)
dfs.columns #Check column
>>> Index(['number', 'Age', 'sex', 'residence', 'Profession', 'Announcement date', 'Remarks'], dtype='object')
dfs.dtypes #Check the data type of each column of dataframe
>>>
Number int64
Age int64
Gender object
Place of residence object
Occupation object
Announcement date object
Remarks object
dtype: object
Extraction of information
df.head(3)
#Extract from the head to the third line.
>>>
Number Age Gender Place of residence Occupation Date of announcement Remarks
0 169 40 Male Amagasaki City Office worker April 2 NaN
1 168 60 Male Ashiya City Office worker April 2 NaN
2 167 50 Male Itami Health and Welfare Office Jurisdiction Company Employee April 2 NaN
dfs.tail()
#Pull out from behind.
>>>
Number Age Gender Place of residence Occupation Date of announcement Remarks
64 105 70 Male Itami City Unemployed March 21 NaN
65 104 80 Female Takarazuka City Unemployed March 21 Death
66 103 60 Male Amagasaki City Office worker March 21 NaN
67 102 40 Female returnees (announced by Himeji City Health Center) Unemployed March 21 NaN
68 101 20 Male Amagasaki City Student March 20 NaN
dfs[["Age","sex","Announcement date"]].head()
#Specify a column and extract.
>>>
Age Gender Announcement Date
0 40 Male April 2nd
1 60 Male April 2nd
2 50 Male April 2nd
3 20 Female April 2nd
4 20 Male April 2nd
row2 = dfs.iloc[3]
print(row2)
#Only the third data from the top is displayed.
>>>
Number 166
Age 20
gender female
Place of residence Itami City
Occupation NaN
Announcement date April 2
Remarks NaN
Data shaping
dfs.rename(columns={'sex': 'sex'}, inplace=True)
dfs.head()
#Name change (gender to sex)
>>>
Number Age sex Place of residence Occupation Date of announcement Remarks
0 169 40 Male Amagasaki City Office worker April 2 NaN
1 168 60 Male Ashiya City Office worker April 2 NaN
2 167 50 Male Itami Health and Welfare Office Jurisdiction Company Employee April 2 NaN
dfs.set_index('Age', inplace=True)
dfs.head()
#
>>>
Number Gender Place of residence Occupation Date of announcement Remarks
Age
40 169 Male Amagasaki City Office worker April 2 NaN
60 168 Male Ashiya City Office worker April 2 NaN
50 167 Male Itami Health and Welfare Office Jurisdiction Company Employee April 2 NaN
dfs.index
>>>
Int64Index([40, 60, 50, 20, 20, 70, 50, 40, 20, 50, 60, 60, 60, 10, 30, 60, 10,
30, 20, 60, 60, 30, 60, 60, 20, 70, 60, 20, 20, 30, 40, 40, 30, 20,
20, 50, 30, 70, 60, 60, 70, 20, 60, 30, 50, 40, 30, 10, 50, 70, 20,
80, 20, 80, 40, 70, 30, 80, 60, 70, 40, 70, 90, 80, 70, 80, 60, 40,
20],
df.sort_values(by="Age", ascending=True).head() # ascending=True in ascending order
# 'Age'Descending columns
# df.sort_values(['Age', 'Announcement date'], ascending=False).head() #Multiple is possible
>>>
Number sex Place of residence Occupation Date of announcement Remarks
Age
10 122 Female Kobe City Student March 27 NaN
10 153 Female Amagasaki City Student April 1 NaN
10 156 Female Kawanishi City Vocational School Student April 1 NaN
20 135 Female Itami Health and Welfare Office Jurisdiction Company Employee March 30 NaN
20 117 Male Nishinomiya City Doctor March 24 NaN
#Delete data
print(df.drop(columns=['number','residence']))
Count the number of data
dfs['Age'].value_counts()
60 15
20 13
70 9
30 9
40 8
50 6
80 5
10 3
90 1
Name:Age, dtype: int64
Find statistical indicators
#average
mean = dfs['Age'].mean()
print(mean) #46.3768115942029
#total
sum = dfs['Age'].sum()
print(sum) #3200
#Median
median = dfs['Age'].median()
print(median) #50.0
#Maximum value
dfsmax = dfs['Age'].max()
print(dfsmax) #90
#minimum value
dfsmin = dfs['Age'].min()
print(dfsmin) #10
#standard deviation
std = dfs['Age'].std()
print(std) #21.418176344401118
#Distributed
var = dfs['Age'].var()
print(var) #458.73827791986366
Recommended Posts