100 Pandas knocks for Python beginners
Introduction
We have created ** "Pandas 100 Knock for Python Beginners" ** as content to efficiently learn the Python library Pandas, so we will publish it. This content is also in line with the content of the ** Python3 engineer certification data analysis test, so performing these 100 knocks will also be a qualification measure. ** Also, at the end of the knock, there is a survival prediction problem for Titanic passengers, which is also a practice for participating in machine learning competitions such as Kaggle.

Motivation for creation
- Recently, the number of people I know who are starting Python / machine learning is increasing, and I've always wanted to create content that I can introduce to such people. I thought that if I could use Pandas, I could use it for daily data aggregation and analysis work even if I couldn't do machine learning, so I decided to make 100 Pandas knocks first.
- There are tons of reference books out there, but I thought that what you could learn by moving your hands quickly was the best content for beginners, rather than understanding it with your head, and I wanted to create something like that.
Overview of 100 Pandas knocks
- Solve 100 Pandas-related questions in the cells on the Jupyter Notebook.
- Two versions are included, a regular version and a random display version of the problem.
- Sections are Foundation (1-13), Extraction (14-32), Machining (33-58), Merge and Concatenation (59-65), Statistics (66-79), Labeling (80-81), Pandas Plot It is divided into eight parts (82-89) and Titanic Passenger Survival Prediction (90-100).
- Below is an overview video.
the issue's details
| No. | Classification | problem |
|---|---|---|
| 1 | Basics | Display the first 5 lines of data read into df |
| 2 | Basics | Display the last 5 lines of data read into df |
| 3 | Basics | Check the DataFrame size of df |
| 4 | Basics | data1 in the input folder.Read csv file, store in df2, display first 5 lines |
| 5 | Basics | Sorted and displayed in ascending order in the fare column of df |
| 6 | Basics | df_Copy df to copy to see the first 5 lines |
| 7 | Basics | ① Check the data type of each column of df ② Check the data type of the cabin column of df |
| 8 | Basics | ① Check the data type of the pclass column of df with dtype (2) Convert from numeric type to character type and check the data type with dtype |
| 9 | Basics | Number of records in df(Number of lines)confirm |
| 10 | Basics | Number of records in df(Number of lines), Check the data type of each column and the presence or absence of missing values |
| 11 | Basics | df sex,Check the elements of the cabin column |
| 12 | Basics | Display df column name list in list format |
| 13 | Basics | Display df index list in ndarray format |
| 14 | Extraction | Show only column of df name |
| 15 | Extraction | Show only df name and sex columns |
| 16 | Extraction | df index(line)の4line目までを表示 |
| 17 | Extraction | df index(line)の4line目から10line目までを表示 |
| 18 | Extraction | View entire df using loc |
| 19 | Extraction | Show all df fare columns using loc |
| 20 | Extraction | Use loc to display up to the 10th row of the df fare column |
| 21 | Extraction | Show all df name and ticket columns using loc |
| 22 | Extraction | Use loc to show all columns from df name to cabin |
| 23 | Extraction | Display df age column up to 5th row using iloc |
| 24 | Extraction | df name,age,sexの列のみExtractionしdf2に格納 Then output as a csv file to the output folder |
| 25 | Extraction | dfのage列の値が30以上のデータのみExtraction |
| 26 | Extraction | dfのsex列がfemaleのデータのみExtraction |
| 27 | Extraction | dfのsex列がfemaleでかつageが40以上のデータのみExtraction |
| 28 | Extraction | queryを用いてdfのsex列がfemaleでかつageが40以上のデータのみExtraction |
| 29 | Extraction | Display data containing the character string "Mrs" in the name column of df |
| 30 | Extraction | Show only character type columns in df |
| 31 | Extraction | Counting the number of unique elements in each column of df |
| 32 | Extraction | Check the elements of the embarked column of df and the number of occurrences |
| 33 | processing | Changed age column of df index name "3" from 30 to 40 |
| 34 | processing | Change male → 0, femlae → 1 in the sex column of df and display the first 5 rows |
| 35 | processing | Add 100 to the fare column of df to display the first 5 rows |
| 36 | processing | Multiply the fare column of df by 2 to display the first 5 rows |
| 37 | processing | Round the fare column of df after the decimal point |
| 38 | processing | Add a column with column name "test" and all 1 values to df and display the first 5 rows |
| 39 | processing | Add the cabin and embarked columns to df_Add columns joined by(Column name is "test")And display the first 5 lines |
| 40 | processing | Add the age and embarked columns to df_Add columns joined by(Column name is "test")And display the first 5 lines |
| 41 | processing | Remove the body column from df and show the first 5 rows |
| 42 | processing | Remove the line with index name "3" from df and display the first 5 lines |
| 43 | processing | The column name of df2'name', 'class', 'Biology', 'Physics', 'Chemistry'change to Show first 5 lines of df2 |
| 44 | processing | The column name of df2'English'Biology'change to Show first 5 lines of df2 |
| 45 | processing | Changed index name "1" of df2 to "10" Show first 5 lines of df2 |
| 46 | processing | Check the number of missing values in all columns of df |
| 47 | processing | Substitute 30 for the missing value in the df age column After that, check the number of missing values of age |
| 48 | processing | Delete lines with even one missing value with df After that, check the number of missing values in df |
| 49 | processing | df survived column in array format(Array)Display with |
| 50 | processing | Shuffle and display df lines |
| 51 | processing | Shuffle the df line and reindex to display |
| 52 | processing | ① Count the number of duplicate lines in df2 |
| 53 | processing | Convert the name column of df to all uppercase and display |
| 54 | processing | Convert all df name columns to lowercase and display |
| 55 | processing | The word "female" in the sex column of df Replaced with "Python" |
| 56 | processing | "Allen" in the first row of the name column of df, Miss.Elisabeth Walton " Erase "Elisabeth"(need import re) |
| 57 | processing | Make sure there are no spaces in the prefecture and city columns of df5 「_Combine with(New column name is "test2")And display the first 5 lines |
| 58 | processing | Swap rows and columns in df2 |
| 59 | Merge and concatenate | Left join df3 to df2 and store in df2 |
| 60 | Merge and concatenate | Right-join df3 to df2 and store in df2 |
| 61 | Merge and concatenate | Innerly join df3 to df2 and store in df2 |
| 62 | Merge and concatenate | Outer join df3 to df2 and store in df2 |
| 63 | Merge and concatenate | Concatenate df2 and df4 in the column direction and store in df2 |
| 64 | Merge and concatenate | df2 and df4 are connected in the column direction and overlap Delete one of the name columns and store it in df2 |
| 65 | Merge and concatenate | df2 and df2 are connected in the row direction and overlap Delete one of the name columns and store it in df2 |
| 66 | statistics | Check the average value of the age column of df |
| 67 | statistics | Check the median of the age column of df |
| 68 | statistics | ① Total score for each student of df2 (total in row direction) (2) Sum of points for each df2 subject (total in the column direction) |
| 69 | statistics | Maximum score in English for df2 |
| 70 | statistics | Minimum score in English for df2 |
| 71 | statistics | Group by class in df2 and find the maximum, minimum, and average values of the subjects for each class.(Delete the name column) |
| 72 | statistics | dfの基本statistics量を確認(describe) |
| 73 | statistics | Between each column of df(Pearson)Check the correlation coefficient |
| 74 | statistics | scikit-Use learn to standardize df2's English, Mathmatics, and History |
| 75 | statistics | scikit-Standardize the English column of df2 using learn |
| 76 | statistics | scikit-Min the English, Mathmatics, and History columns of df2 using learn-Max scale |
| 77 | statistics | Get the row name of the maximum and minimum values of the fare column of df |
| 78 | statistics | Get the 0th, 25th, 50th, 75th and 100th percentiles of the df fare column |
| 79 | statistics | ① Get the mode of the age column of df ②value_counts()Check the number of elements in the age column at, and confirm the validity of the result of ①. |
| 80 | labeling | Label encode the sex column of df and display the first 5 rows of df |
| 81 | labeling | One sex column for df-hot encode and display the first 5 lines of df |
| 82 | Pandas plot | Show histogram of all numeric columns in df |
| 83 | Pandas plot | Display the age column of df as a histogram |
| 84 | Pandas plot | Display the total score of 3 subjects for each name of df2 in a bar graph |
| 85 | Pandas plot | Display 3 subjects for each element of the name column of df2 side by side in a bar graph |
| 86 | Pandas plot | Display 3 subjects for each element in the name column of df2 as a stacked bar graph |
| 87 | Pandas plot | Show scatter plot between each column of df |
| 88 | Pandas plot | Create a scatter plot with the age and fare columns of df |
| 89 | Pandas plot | In the graph drawn in [88], "age"-fare scatter " Give a graph title |
| 90 | Titanic Survivor Prediction | df_Label encoding sex and embarked columns of copy |
| 91 | Titanic Survivor Prediction | df_Check for missing values in copy |
| 92 | Titanic Survivor Prediction | df_Complement the missing values in the age and fare columns of copy with the average value of each column |
| 93 | Titanic Survivor Prediction | df_Delete unnecessary lines that are not used in machine learning in copy |
| 94 | Titanic Survivor Prediction | ①df_Extract pclass, age, sex, fare, embarked columns of copy and convert to ndarray format ②df_Extract the survived column of copy and convert it to ndarray format |
| 95 | Titanic Survivor Prediction | Divide the features and target created in [94] into training data and test data. |
| 96 | Titanic Survivor Prediction | Training data(features、target)Perform learning in a random forest using |
| 97 | Titanic Survivor Prediction | test_X Data Predict Passenger Survival |
| 98 | Titanic Survivor Prediction | Prediction result is test_y(Answer of survival)And how much Check if it was consistent(Evaluation index is accuracy) |
| 99 | Titanic Survivor Prediction | Each column in learning(Feature value)Show importance of |
| 100 | Titanic Survivor Prediction | test_Output the prediction result of X to the output folder with csv (file name is "submission".csv」) |
How to Use
-
If you haven't installed Python yet, please install anaconda on your own PC first. In addition to Pandas, libraries such as Scikit-learn are also used in the problem.
-
After downloading the ZIP folder from GitHub, extract it to the local area of your PC.
-
Open the ipynb file stored in the "notebook" folder with Jupyter Notebook (try opening "01_Pandas_100_Knocks_for_Begginer_v1.0.ipynb" first).
-
After opening the ipynb file, execute the first cell to load the answer file and the dataset used in the question. The data set used is passenger data for the Titanic.
-
Enter the code for each question in the cell of each question.
-
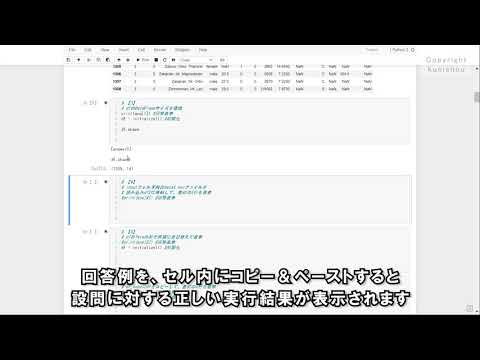
If you do not know the answer, delete the "#" from the description "#print (ans [])" in the question cell and execute it to display the answer example.
Directory structure
pandas_100_knocks_v1.0 ├ notebook /… Stores 3 ipynb files ├ input /… Contains answer files for 100 questions and datasets used for questions └ output /… Stored here when outputting a file due to a problem
- Please do not change this directory structure after extracting from the ZIP file (it will not work properly).
Aim of this content
Hopefully, Python beginners can reach level 3 and set the problem (I think you can reach level 2 if you solve it 3 times).
- ** Level 1 ** You will be able to perform basic data aggregation / analysis with Python / Pandas (data aggregation / analysis can be performed with Python as an alternative method to Excel and Access in business)
- ** Level 2 ** Not only data aggregation and analysis but also some machine learning can be done (when you look at the 03 ipynb file (Titanic) stored in the "notebook" folder, you will be able to understand what you are doing).
- ** Level 3 ** Be able to participate in machine learning competitions such as Kaggle
download
The content can be downloaded from GitHub.
https://github.com/kunishou/Pandas_100_knocks
Scope of use / Precautions
-
Range of use Anyone can use it regardless of individual or corporation (When you use it for volunteer study sessions or in-house training, please let us know and it will motivate the author. I am also happy to hear comments such as "This content helped me get the Python certification exam")
-
Notes Content cannot be redistributed or reorganized
Other (Scratchpad)
Scratchpad of nbextensions is convenient as an extension of Jupyter Notebook, so we recommend installing it. While working on 100 knocks, it is troublesome to do "Add new cell → df.head ()" to check the data contents stored in the data frame. With Scratchpad, you can call up a disposable cell area with "Ctrl + B".

Please refer to the following for the installation method.
[Python] jupyter notebook extensions ~
Finally
If you have any questions or requests regarding this content, please contact us.
Recommended Posts