Think about specifications for collaborative filtering recommendation engine development
I want to make collaborative filtering recommendations, but there is no good library for open source, and ASP services are basically over 50,000 yen / month. I have no choice but to make it myself
What is Collaborative Filtering Recommendation?
I think the most famous implementation example is Amazon's "People who bought this product also bought this product" function. Previously, I introduced Implementation of simplified version. This article is a continuation of the simplified version of the article.
Quoted from collaborative filtering on wikipedia
Collaborative filtering (Collaborative Filtering, CF) is a methodology that accumulates preference information of many users and automatically makes inferences using information of other users who have similar preferences to one user. It is often compared to the principle of word-of-mouth, which refers to the opinions of people with similar hobbies.
 As the scrap and build of Mr. Hada, a muscle training writer who won the award at the same time as the spark, is recommended first, it is Mr. Sasuga Amazon .. The Naoki Prize-winning novel is also a good novel.
As the scrap and build of Mr. Hada, a muscle training writer who won the award at the same time as the spark, is recommended first, it is Mr. Sasuga Amazon .. The Naoki Prize-winning novel is also a good novel.
Collaborative filtering is a dead technology
If you fish the Web, there is a Japanese article as of 2005. Also, the companies that provide recommendation services are crowded, and you can find many companies by searching (although they are all expensive), so the theory that you can make is probably on the market.
Collaborative filtering seems to be generally realized by correlating with the Jaccard coefficient. The formula for calculating the Jaccard coefficient for product X and product A is as follows.
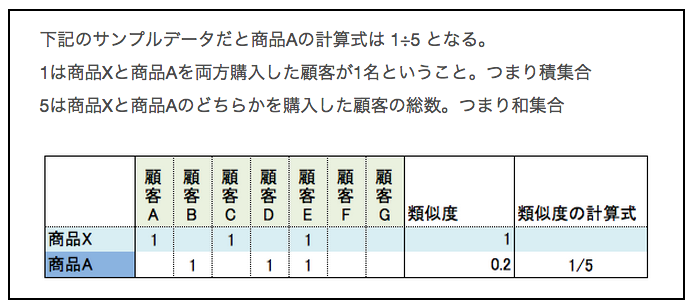
So, if there are 1 million products, it is necessary to calculate the Jaccard coefficient 1 million times to calculate the products recommended from product X. The amount of calculation is exploding. This calculation method is not realistic.
Collaborative filtering is a dead technology. The ancestors who encountered the above problems have offered several solutions. Amazon solves the problem by creating a reverse index in 2003 has been published.
Reverse index validation code
Calculation samples of Jaccard coefficient are scattered on the Web, but I can't find a sample to solve by creating a reverse index. The only concrete thing I found was [Similarity calculation in recommendations: Trends and countermeasures #DSIRNLP 4th 2013.9.1](https://speakerdeck.com/komiya_atsushi/rekomendoniokerulei-si-du-ji- Let's create a reverse index by referring to the material of suan-sofalseqing-xiang-todui-ce-number-dsirnlp-di-4hui-2013-dot-9-1).
# -*- coding: utf-8 -*-
from __future__ import absolute_import, unicode_literals
#Product ID:10 buyers
from collections import defaultdict
ITEM_10_BUY_USERS = ['A', 'C', 'E', 'G']
#Buyer's product purchase history(Reverse index)
INDEX_BASE = 'INDEX_BUY_HISTORY_USER_{}'
INDEX = {
'INDEX_BUY_HISTORY_USER_A': [10, 20, 50, 60, 90],
'INDEX_BUY_HISTORY_USER_B': [20, 20, 50, 60, 70],
'INDEX_BUY_HISTORY_USER_C': [10, 30, 50, 60, 90],
'INDEX_BUY_HISTORY_USER_D': [30, 40, 50, 60],
'INDEX_BUY_HISTORY_USER_E': [10],
'INDEX_BUY_HISTORY_USER_F': [70, 80, 90],
'INDEX_BUY_HISTORY_USER_G': [10, 70, 90],
}
#Calculate similarity using reverse index
result = defaultdict(int)
for user_id in ITEM_10_BUY_USERS:
#Get purchase history for each user from INDEX
buy_history = INDEX.get(INDEX_BASE.format(user_id))
#Aggregate the number of purchased items
for item_id in buy_history:
result[item_id] += 1
l = []
for key in result:
l.append((key, result[key]))
#Show the similarity of results
l.sort(key=lambda x: x[1], reverse=True)
print l
>>> [(10, 4), (90, 3), (50, 2), (60, 2), (70, 1), (20, 1), (30, 1)]
It was found that the products with high similarity to product 10 have the highest correlation in the order of product 90, product 50, and product: 60. With this method, the amount of calculation is smaller than the Jaccard coefficient that calculates the similarity with all products, and it seems possible to control the amount of calculation by controlling the amount of users to refer to.
The heart of the recommendation engine is the update speed
For example, we operate a sales site with 1 million products and 1 million users. "Sparks" released on March 11, 2015 became a big hit from the release date and sold 50,000 copies in one day. If there are many products, a petite festival will occur once a week, so it seems that how quickly we update the recommendations of 1 million products will directly lead to sales.
However, the amount of calculation is enormous. The world of competition is how quickly you can update. As a function required for the recommendation engine, it may be required to have a mechanism that enables parallel calculation. When the producer tells me that the update interval cannot be reduced to 1/4, I am updating with 4 units now, so if I calculate with 16 units, which is 4 times, it will be 1/4. Since one unit costs 50,000 yen a month, the monthly cost increases by 5 x 12 = 600,000 yen. It would be nice if you could reply. (The producer should leave and the engineer should be able to return on time.)
I think Redis is good for the back end
I think Redis is a good backend for the recommendation engine. It's dead, reasonably fast to read, provided on AWS, and works with a single thread, so if used properly, the data is guaranteed to be atomic and I / O is faster than RDS. It is also easy to use because there are libraries from Ruby, PHP, Node.js, and Perl. Being guaranteed to be Atomic means thread-safe. In other words, it is considered that it meets the conditions that can be used as a backend for parallel computing.
- I think the ideal implementation is a method in which the backend can be selected with data_handler.
specification
- pip install is possible
- It has a tag function and can be recommended for each tag.
- Update of recommended products can be executed in parallel
- Available from Ruby and PHP
- The product can be deleted
- The user's purchase history can be edited
- User can be deleted
Performance goals
With 1 million products, 1 million users, and an average of 50 purchases per user
- All recommendation updates can be completed within 4 hours on a single MacBook Pro
- Update of recommended products should be completed within 10 seconds with one MacBook Pro per product
I wish I could call it like this
[sample]At the time of introduction to the new system
#Register all products
for goods in goods.get_all():
Recomender.register(goods.id, tag=goods.tag)
#Register all purchase history
for user in user.get_all():
Recomender.like(user.id, user.history.goods_ids)
# sample1.Update recommendations for all products(Single thread)
Recomender.update_all()
# sample2.Update recommendations for all products(Multithreaded thread)
Recomender.update_all(proc=4)
# sample3.Update recommendations for all products(4 parallel clusters x 4 parallel)
#Parallel cluster.1 First half of all products 1/Calculate 4
Recomender.update_all(proc=4, scope=[1, 4])
#Parallel cluster.2 First half of all products 1/Calculate 4
Recomender.update_all(proc=4, scope=[2, 4])
#Parallel cluster.3 Second half of all products 1/Calculate 4
Recomender.update_all(proc=4, scope=[3, 4])
#Parallel cluster.4 Second half of all products 1/Calculate 4
Recomender.update_all(proc=4, scope=[4, 4])
sample_code
#New product addition
new_goods_id = 2100
tag = "book"
Recomender.register(new_goods_id, tag=tag)
#The person who bought this product also bought this product. Get 5
goods_id = 102
print Recomender.get(goods_id, count=5)
>>> [802, 13, 45, 505, 376]
#Update recommendations for specific products
Recomender.update(goods_id)
#Update recommendations for all products
Recomender.update_all()
#Mr. A is goods_Buy ids
user_id = "dd841cad-b7cf-473b-9006-77823ad5e006"
goods_ids = [102, 102, 103, 104]
Recomender.like(user_id, goods_ids)
recommendation_data_update
#Change product tag
new_tag = "computer"
Recomender.change_tag(goods_id, new_tag)
#Delete product
Recomender.remove(goods_id)
#Delete user
Recomender.remove_user(user_id)
All you have to do is make it ... make it ... ke .... tsu ......... ke .....
reference
- Collaborative filtering Toshiyuki Masui
- [Similarity calculation in recommendations The tendency and countermeasures #DSIRNLP 4th 2013.9.1](https://speakerdeck.com/komiya_atsushi/rekomendoniokerulei-si-du-ji-suan-sofalseqing-xiang-todui-ce- number-dsirnlp-di-4hui-2013-dot-9-1)
- Amazon.com Recommendations Item-to-Item Collaborative Filtering
It was completed
Collaborative filtering RealTime recommendation engine released I look forward to working with you.
Recommended Posts