Extraction of synonyms using Word2Vec went well, so I summarized the analysis
Introduction
Hi, my name is @To_Murakami and I'm a data scientist at Speee. I'm not an engineer, but I wanted to send an example of analysis including coding, so I participated in the company's Advent Calendar. It's almost the end of December, isn't it? Today, I would like to introduce an example of analysis using natural language processing called Word2Vec. The purpose of implementing this logic is because I wanted to make something like ** word notation fluctuation (synonym) detector **. Why can you tell the word notation fluctuation from Word2Vec? Once you have an overview of how it works (below), you can understand why.
How Word2Vec works (easily)
Word2Vec is literally ** a vector of words . Of course, numbers are included in the vectorized contents. In other words, it is possible to quantify linguistic data called words!
The mechanism of digitization is learning and dimension compression by a neural network.
 The figure above is an example of a typical model called CBOW (Continuous Bug-of-words). Each word at the input stage is called a One-hot vector, and the "flag of" yes "or" no "is expressed by" 0/1 ". Here, the vectorization of the word "cold" is calculated by learning. CBOW also captures information in several words before and after and sends it to the projection layer. Weighted learning is performed from the projection layer with a neural network, and the word vector is calculated as the output. The number of dimensions of the output vector and the number of dimensions of the input can be different. It can be specified when modeling. (You can also control how many words are put into the projection layer before and after.)
In this way, each word vector is calculated. Each number that makes up the vector indicates the meaning and characteristics of the word. The idea behind this is based on the premise that " words that have similar meanings and usages appear in a similar sequence of words **". If we accept this premise, we can hypothesize that words with similar vectors have similar meanings. Since the vectors are close to words with similar notation and synonyms with the same meaning, it can be expected that they can be extracted by a scale such as cosine similarity.
The figure above is an example of a typical model called CBOW (Continuous Bug-of-words). Each word at the input stage is called a One-hot vector, and the "flag of" yes "or" no "is expressed by" 0/1 ". Here, the vectorization of the word "cold" is calculated by learning. CBOW also captures information in several words before and after and sends it to the projection layer. Weighted learning is performed from the projection layer with a neural network, and the word vector is calculated as the output. The number of dimensions of the output vector and the number of dimensions of the input can be different. It can be specified when modeling. (You can also control how many words are put into the projection layer before and after.)
In this way, each word vector is calculated. Each number that makes up the vector indicates the meaning and characteristics of the word. The idea behind this is based on the premise that " words that have similar meanings and usages appear in a similar sequence of words **". If we accept this premise, we can hypothesize that words with similar vectors have similar meanings. Since the vectors are close to words with similar notation and synonyms with the same meaning, it can be expected that they can be extracted by a scale such as cosine similarity.
- I posted a related article about half a year ago. Please refer. http://qiita.com/To_Murakami/items/6bd5638689166ec4821c
Did you get a close word?
Is the reading in the mechanics section actually correct? I crawled 11000 beauty articles, created a corpus, and verified it. In conclusion, ** I was able to extract words that were more similar than I expected **! Below, I will give several sample examples.
<< Example 1: "Diet" >>
 "Diet method" and "diet method" are just the output for this purpose.
"Closeness" is evaluated by ** cosine similarity ** of the two-word vector ("score" above). The more similar the sequence of words, the higher the similarity.
"Diet method" has the same meaning as "diet" due to the fluctuation of notation. Words such as "thinning" and "weight loss" have the same purpose and meaning as dieting, and show a high degree of similarity.
"Diet method" and "diet method" are just the output for this purpose.
"Closeness" is evaluated by ** cosine similarity ** of the two-word vector ("score" above). The more similar the sequence of words, the higher the similarity.
"Diet method" has the same meaning as "diet" due to the fluctuation of notation. Words such as "thinning" and "weight loss" have the same purpose and meaning as dieting, and show a high degree of similarity.
<< Example 2: "Fashionable" >>
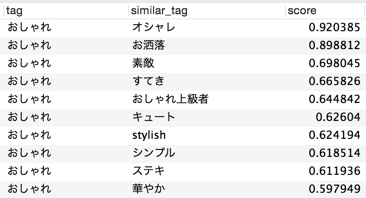 After all, "fashionable" and "fashionable", which are synonymous with notation fluctuation, show a high degree of similarity. This is followed by words that give an impression or evaluation of "fashionable".
After all, "fashionable" and "fashionable", which are synonymous with notation fluctuation, show a high degree of similarity. This is followed by words that give an impression or evaluation of "fashionable".
<< Example 3: "Makeup" >>
 For a wide range of words like make-up, the words that indicate specific make-up come first (because they are used in a similar context).
For a wide range of words like make-up, the words that indicate specific make-up come first (because they are used in a similar context).
<< Example 4: "Aoi Miyazaki" >>
 You can see how Aoi Miyazaki is seen by people in the world (^ _ ^;)
You can see how Aoi Miyazaki is seen by people in the world (^ _ ^;)
<< Example 5: "Denim" >>
 The clothes that correspond to the same bottoms are also displayed, but they also tell you the coordination of the upper body that goes well with denim.
The clothes that correspond to the same bottoms are also displayed, but they also tell you the coordination of the upper body that goes well with denim.
<< Example 6: "Fat" >>
 It's unforgiving (^ _ ^;)
It's unforgiving (^ _ ^;)
<< Example 7: "Christmas" >>
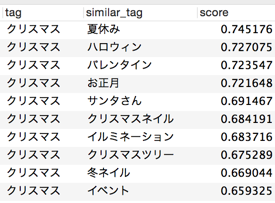 Perhaps because it is a beauty-related article, words related to events are listed. If the corpus is a specific personal blog, the output may change.
Perhaps because it is a beauty-related article, words related to events are listed. If the corpus is a specific personal blog, the output may change.
What I devised
By focusing on ** data preprocessing **, the content of the output will be much better. Preprocessing is morphological analysis. You will be able to delete unnecessary words and separate the strings to get the words you want.
① Expansion of dictionary
I learned the latest version of "mecab-ipadic-NEologd" (I think many people know this). In addition to NEologd, we have added ** an unknown word user dictionary obtained by our own logic **. Proper nouns and latest words such as product names have been added to the user dictionary.
② Stop word
Added a list of words that are not evaluated for vectorization as stop words. It will be in the form excluding single-character strings and general-purpose words.
Implementation
I used a library called ** gensim **. With gensim, you can implement it in ** practically just a few lines **. A little convenient ♪
- I / O by DB is omitted.
Python
#!/usr/bin/python
# -*- coding: utf-8 -*-
from gensim.models import word2vec
import cython
from sqlalchemy import *
import pandas as pd
# fetch taglist from DB
engine_my = create_engine('mysql+mysqldb://pass:user@IP:port/db?charset=utf8&use_unicode=0',echo=False)
connection = engine_my.connect()
cur = connection.execute("select distinct(name) from tag;")
tags = []
for row in cur:
# need to decode into python unicode because db preserves strings as utf-8
# need to treat character sets altogether in one format
tags.append(row["name"].decode('utf-8'))
connection.close()
# Import text file and make a corpus
data = word2vec.Text8Corpus('text_morpho.txt')
# Train input data by Word2Vec(in option below, take CBOW method)
# Take about 5 min when training ~11000 documents
model = word2vec.Word2Vec(data, size=100, window=5, min_count=5, workers=2)
# Save temporary files
model.save("W2V.model")
# make similar word list (dict type)
similar_words = []
for tag in tags:
try:
similar_word = model.most_similar(positive=tag)
for i in range(10):
similar = {}
similar['tag'] = tag
similar['similar_tag'] = similar_word[i][0]
similar['score'] = similar_word[i][1]
similar_words.append(similar)
except:
pass
# Conver dict into DataFrame to filter data easily
df_similar = pd.DataFrame.from_dict(similar_words)
df_similar_filtered = df_similar[df_similar['similar_tag'].isin(tags)]
df_similar = df_similar.ix[:,['tag', 'similar_tag', 'score']]
Recommended Posts