Introduction à la méthode Monte Carlo
introduction
De nos jours, l'approche bayésienne n'est plus la norme, et comment collecter des données d'entraînement et les mettre en Deep Learning est populaire, mais il est parfois possible de faire de tels calculs classiques.
J'avais l'intention d'expliquer MCMC, mais ce n'était pas facile d'expliquer la simulation simple, donc je vais expliquer une fois la simulation simple. Je souhaite personnellement écrire sur MCMC dans un proche avenir.
Cet article est largement basé sur le chapitre 11 de PRML.
Méthode de Monte Carlo
Lorsque vous êtes impliqué dans l'apprentissage automatique, vous entendrez souvent le mot simulation de Monte Carlo ou méthode de Monte Carlo. Avant d'écrire cet article, je pensais vaguement, "Ah, MCMC, n'est-ce pas?", Mais quand j'ai essayé de l'expliquer concrètement, je suis resté coincé dans la réponse. Dans un tel cas, si vous demandez à Wikipédia, vous pouvez comprendre l'idée générale, je voudrais donc jeter un œil à l'article de Wikipédia pour le moment.
Méthode de Monte Carlo (méthode de Monte Carlo, (anglais):La méthode de Monte Carlo (MC) est un terme général pour les méthodes qui effectuent des simulations et des calculs numériques à l'aide de nombres aléatoires.
Nommé d'après Monte Carlo, l'un des quatre quartiers (Culti) de la Principauté de Monaco, célèbre pour ses casinos.
Monte Carlo n'était qu'un nom de lieu. Quand j'ai entendu le mot casino, je me suis demandé si les gens qui essayaient de gagner au casino l'avaient créé pour faire une simulation.
Dans le domaine de la théorie computationnelle, la méthode de Monte Carlo est définie comme un algorithme aléatoire qui donne une borne supérieure sur la probabilité de se tromper.[1]。
En d'autres termes, la plupart des choses peuvent être appelées simulation de Monte Carlo ou méthode de Monte Carlo en utilisant des nombres aléatoires. En fait, l'article déclare que la «méthode de jugement des nombres premiers Mirror-Rabin», qui est un algorithme pour déterminer de manière probabiliste si un nombre premier est ou non un nombre premier, est également la méthode de Monte Carlo. Cependant, cette fois, je me concentre sur l'apprentissage automatique et je n'ai pas le temps d'oublier la méthode de jugement des nombres premiers.
Par conséquent, je voudrais limiter ma réflexion à ce qui suit.
Considérons un algorithme qui génère un nombre aléatoire X qui suit la distribution de P lorsqu'une certaine distribution de probabilité P est déterminée.
Si vous pouvez générer le nombre aléatoire $ X $ qui apparaît dans le paramètre de problème ci-dessus, vous pouvez l'appliquer à diverses simulations et calculs numériques.
table des matières
--Méthode de conversion variable
- Distribution exponentielle
- distribution normale
- Distribution de Cauchy --Méthode d'échantillonnage par rejet
- Distribution Gamma
Supposons qu'il soit possible de générer un nombre aléatoire uniformément distribué $ U $ de $ [0, 1] $ partout. A partir de ce $ U $, un nombre aléatoire qui suit la fameuse distribution de probabilité
Méthode de conversion variable
Soit $ P $ la distribution de probabilité que vous souhaitez générer.
Une méthode de conversion de variable pour trouver une fonction $ F_ {P} $ telle que "$ Y = F_ {P} (U) $ suit la distribution de $ P $" pour un nombre aléatoire uniformément distribué $ U
Puisque $ u et y $ apparaissent en même temps, j'ai l'impression de ne pas comprendre. Cependant, comme il existe une relation de $ Y = F_ {P} (U) $, en utilisant la fonction inverse $ F_ {p} ^ {-1} $ de $ F_ {p} $, $ U = F_ {p Vous pouvez écrire} ^ {-1} (Y) $. En utilisant cette formule, nous pouvons voir que nous pouvons écrire $ p (y) = du / dy = d (F_ {p} ^ {-1} (y)) / dy $. En fait, je pense que cette transformation de formule est assez délicate. C'est difficile à comprendre, du moins à première vue. Vous vous demandez peut-être pourquoi la fonction inverse apparaît, mais habituons-nous petit à petit en regardant l'exemple ci-dessous.
Exemple: distribution exponentielle
La fonction de densité de probabilité de distribution exponentielle $ p $ est exprimée par la formule suivante.
Définissez $ G (x) = \ int_ {0} ^ {x} p (x) dx $. La différenciation de la fonction intégrée la renvoie à la fonction d'origine, donc $ dG / dx = p (x) $ est valable. Je voulais trouver une fonction qui satisfasse $ p (y) = d (F_ {p} ^ {-1} (y)) / dy $, donc je sens que la fonction inverse de $ G $ est $ F $. (En fait, oui).
Si vous calculez concrètement $ G
import numpy as np
import matplotlib.pyplot as plt
Lambda = 0.1
N = 100000
u = np.random.rand(N)
y = - Lambda * np.log(1 - u)
plt.hist(y, bins=200)
plt.show()
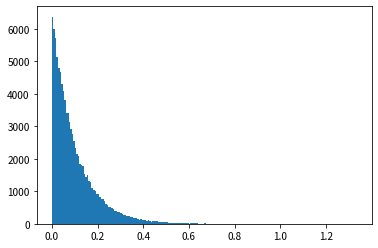
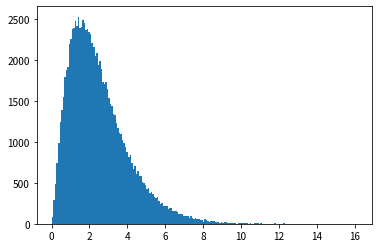
En regardant les résultats de l'histogramme, nous pouvons voir qu'il a une forme similaire à la fonction de densité de probabilité de la distribution exponentielle, et que des nombres aléatoires qui suivent la distribution exponentielle peuvent être générés.
Exemple: distribution normale
Ensuite, je présenterai "l'algorithme de Box-Muller", qui est un algorithme célèbre pour créer des nombres aléatoires avec une distribution normale standard. À partir d'une distribution uniforme $ (z_1, z_2) $ sur un disque de rayon 1
J'ai donné la formule de manière descendante parce que j'ai renoncé à dériver cette formule. ..
J'ai en fait écrit un script Python qui génère des nombres aléatoires en utilisant cette fonction $ F $.
import numpy as np
import matplotlib.pyplot as plt
N = 100000
z = np.random.rand(N * 2, 2) * 2 - 1
z = z[z[:, 0] ** 2 + z[:, 1] ** 2 < 1]
z = z[:N]
r = z[:, 0] ** 2 + z[:, 1] ** 2
y = z[:, 0] / (r ** 0.5) * ((-2 * np.log(r)) ** 0.5)
plt.hist(y, bins=200)
plt.show()
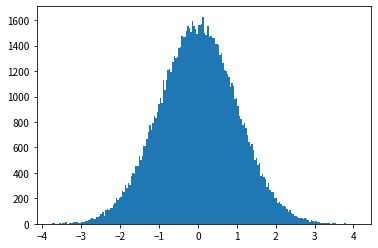
Distribution de Cauchy
Enfin, générons un nombre aléatoire qui suit la distribution de Cauchy. Les distributions de Cauchy sont rarement utilisées statistiquement par rapport aux distributions exponentielles et normales. Cependant, dans la section suivante, la section de distribution gamma utilise des nombres aléatoires qui suivent la distribution de Cauchy, nous allons donc les introduire ici. La fonction de densité de probabilité de la distribution de Cauchy est exprimée par la formule suivante.
p(x; c) = \frac{1}{1 + (x - c)^2}
La fonction de distribution cumulative $ G $ de la distribution de Cauchy peut être facilement écrite comme suit en utilisant la fonction inverse de la fonction $ \ tan $ appelée $ \ arctan $.
u = G(x) = \int_{-\infty}^{x} p(x; c) = \frac{1}{\pi} \arctan (x - c) + \frac{1}{2}
Par conséquent, la fonction inverse $ F $ de $ G $ peut s'écrire comme suit.
F(u) = \tan \bigg(\pi \bigg(u - \frac{1}{2} \bigg)\bigg) + c
Autrement dit,
Voyons le résultat de la génération réelle d'un nombre aléatoire en utilisant cette fonction $ F $.
cauchy_F = lambda x: np.tan(x * (np.pi / 2 + np.arctan(c)) - np.arctan(c)) + c
N = 100000
u = np.random.rand(N)
y = cauchy_F(u)
y = y[y < 10]
plt.hist(y[y < 10], bins=200)
plt.show()
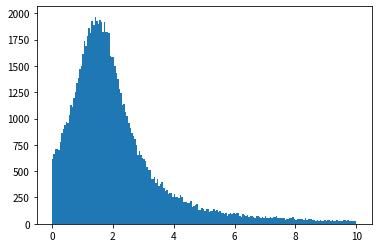
En regardant les résultats de l'histogramme, nous pouvons voir qu'il a une forme similaire à la fonction de densité de probabilité de la distribution exponentielle, et que des nombres aléatoires qui suivent la distribution exponentielle peuvent être générés.
Cependant, si vous regardez de plus près le script, vous trouverez une ligne qui vous intéresse: y = y [y <10].
Si vous supprimez cette ligne et l'exécutez, ce sera ridicule.
Cela signifie que des valeurs aberrantes ridiculement importantes peuvent être générées. Ce résultat est assez convaincant, rappelant le fait que la valeur moyenne de la distribution de Cauchy diverge.

Si je limite la valeur du nombre aléatoire à 10 ou moins, je pense que la valeur moyenne est d'environ 2, mais comme des valeurs extrêmement élevées se produisent rarement, la valeur moyenne a été poussée vers le haut. Je me souviens de l'histoire selon laquelle les revenus moyens et médians sont différents.
Points de méthode de conversion variable
Vous devez vous familiariser avec les caractéristiques de la distribution. Dans la plupart des cas, vous devez être capable d'écrire la fonction de distribution cumulative sous une forme simple. Je pense que ce serait beaucoup de travail de le demander d'une autre manière. De plus, si F n'est pas une fonction qui peut être facilement calculée, cela n'a aucun sens après tout.
Méthode d'échantillonnage de rejet
Exemple: distribution gamma
La fonction de densité de probabilité de la distribution gamma est exprimée par la formule suivante.
p(x; a, b) = b^{a} z^{a-1} \exp(-bz) / \Gamma(a)
Comme il est difficile de trouver la valeur de la fonction $ \ Gamma $, nous utiliserons $ \ tilde {p} $, en ignorant la partie $ \ Gamma $.
\tilde{p}(x; a) = z^{a-1} \exp(-z)
Trouvons maintenant k qui dépasse la distribution de Cauchy. Il était difficile de calculer à la main, donc je me suis appuyé sur le script cette fois.
gamma_p_tilda = lambda x: (x ** (a - 1)) * np.exp(-x)
cauchy_p = lambda x: 1 / (1 + ((x - c) ** 2)) / (np.pi / 2 + np.arctan(c))
z = np.arange(0, 100, 0.01)
gammas = gamma_p_tilda(z)
cauchys = cauchy_p(z)
k = np.max(gammas / cauchys)
cauchys *= k
plt.plot(z, gammas, label='gamma')
plt.plot(z, cauchys, label='cauchy')
plt.legend()
plt.show()
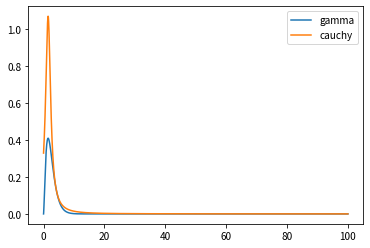
La valeur de $ k $ stockée dans le script ci-dessus était de 2,732761944808582 $.
N = 100000
u = np.random.rand(N * 3)
y = cauchy_F(u)
u0 = np.random.rand(N * 3)
u0 *= k * cauchy_p(y)
y = y[u0 < gamma_p_tilda(y)]
y = y[:N]
plt.hist(y, bins=200)
plt.show()
Conditions applicables pour l'échantillonnage de rejet
Nous avons besoin d'une proposition de distribution $ Q $ qui puisse facilement générer des nombres aléatoires. Vous devez également calculer $ k $ qui satisfait $ kq \ geq p $. Si vous augmentez trop par inadvertance la valeur de $ k $, vous devrez rejeter les nombres aléatoires générés, donc nous voulons rendre $ k $ aussi petit que possible. Cependant, dans ce cas, il est nécessaire de le dériver de la forme concrète de la fonction ou de calculer la valeur avec précision, ce qui est un problème décent. De plus, lors de la détermination de la valeur de $ k $ ou du calcul de son rejet, la valeur de la fonction de densité de probabilité est utilisée à la fois pour $ P $ et $ Q $, de sorte que la fonction de densité de probabilité elle-même doit être facile à calculer. Par conséquent, cette méthode ne peut pas être appliquée lorsque le calcul de la fonction de densité de probabilité elle-même est difficile, comme dans un modèle dans lequel plusieurs variables sont intimement liées.
Vers MCMC
Jusqu'à présent, nous avons donné un aperçu des techniques standard de génération de nombres aléatoires. Si vous l'examinez, vous pouvez voir que la distribution de probabilité d'origine doit être sous une forme facile à gérer dans une certaine mesure.
Il a été constaté que des nombres aléatoires statistiquement importants tels que la distribution normale, la distribution exponentielle et la distribution gamma peuvent être générés à partir d'une distribution uniforme. Je pense que cela seul peut faire beaucoup de choses, mais il existe des modèles plus complexes qui utilisent l'approche bayésienne. Cette méthode de génération à elle seule ne dispose pas de suffisamment d'armes pour contrer le modèle bayésien complexe.
Par conséquent, un algorithme qui peut générer des nombres aléatoires pour un modèle plus compliqué appelé MCMC sort. La prochaine fois, j'aimerais expliquer le modèle graphique, qui est le principal domaine d'application de MCMC, et la méthode concrète de MCMC.
Recommended Posts