J'ai essayé de créer une méthode de super résolution / ESPCN
Aperçu
Cette fois, j'ai créé ESPCN (réseau de neurones convolutifs sous-pixels efficace), qui est l'une des méthodes de super-résolution, je vais donc le publier sous forme de résumé. Cliquez ici pour consulter l'article original → [Super-résolution d'image et vidéo unique en temps réel utilisant un réseau neuronal convolutionnel sous-pixel efficace](https://www.cv-foundation.org/openaccess/content_cvpr_2016/html/Shi_Real-Time_Single_Image_CVPR_2016_paper. html)
table des matières
1.Tout d'abord 2. Qu'est-ce que ESPCN? 3. Environnement PC 4. Description du code 5. À la fin
1.Tout d'abord
La super-résolution est une technologie qui améliore la résolution des images basse résolution et des images en mouvement, et ESPCN est une méthode proposée en 2016. (À propos, le SRCNN, qui est mentionné comme la première méthode de Deeplearning, est 2014) SRCNN était une méthode pour améliorer la résolution en la combinant avec la méthode d'agrandissement existante telle que la méthode bicubique, mais dans cet ESPCN, la phase d'agrandissement est introduite dans le modèle Deeplearning, et elle peut être agrandie à n'importe quel grossissement. Je vais. Cette fois, j'ai construit cette méthode avec python, je voudrais donc présenter le code. Le code complet est également publié sur GitHub, veuillez donc vérifier ici. https://github.com/nekononekomori/espcn_keras
2. Qu'est-ce que ESPCN?
ESPCN est une méthode pour améliorer la résolution en introduisant la convolution de sous-pixels (Pixel shuffle) dans le modèle Deeplearning. Puisque l'essentiel est de poster le code, j'omettrai l'explication détaillée, mais je posterai le site qui explique ESPCN. https://buildersbox.corp-sansan.com/entry/2019/03/20/110000 https://qiita.com/oki_uta_aiota/items/74c056718e69627859c0 https://qiita.com/jiny2001/items/e2175b52013bf655d617
3. Environnement PC
cpu : intel corei7 8th Gen gpu : NVIDIA GeForce RTX 1080ti os : ubuntu 20.04
4. Description du code
Comme vous pouvez le voir sur GitHub, il se compose principalement de trois codes. ・ Datacreate.py → Programme de génération de jeux de données ・ Model.py → Programme ESPCN ・ Main.py → Programme d'exécution J'ai créé une fonction avec datacreate.py et model.py et l'ai exécutée avec main.py.
Description de datacreate.py
datacreate.py
import cv2
import os
import random
import glob
import numpy as np
import tensorflow as tf
#Un programme qui coupe un nombre arbitraire d'images
def save_frame(path, #Chemin du fichier contenant les données
data_number, #Nombre de photos à couper à partir d'une image
cut_height, #Taille de stockage(Verticale)(Faible qualité d'image)
cut_width, #Taille de stockage(côté)(Faible qualité d'image)
mag, #Grossissement
ext='jpg'):
#Générer une liste d'ensembles de données
low_data_list = []
high_data_list = []
path = path + "/*"
files = glob.glob(path)
for img in files:
img = cv2.imread(img, cv2.IMREAD_GRAYSCALE)
H, W = img.shape
cut_height_mag = cut_height * mag
cut_width_mag = cut_width * mag
if cut_height_mag > H or cut_width_mag > W:
return
for q in range(data_number):
ram_h = random.randint(0, H - cut_height_mag)
ram_w = random.randint(0, W - cut_width_mag)
cut_img = img[ram_h : ram_h + cut_height_mag, ram_w: ram_w + cut_width_mag]
#Se rétrécit après le flou avec le filtre Usian
img1 = cv2.GaussianBlur(img, (5, 5), 0)
img2 = img1[ram_h : ram_h + cut_height_mag, ram_w: ram_w + cut_width_mag]
img3 = cv2.resize(img2, (cut_height, cut_width))
high_data_list.append(cut_img)
low_data_list.append(img3)
#numpy → tensor +Normalisation
low_data_list = tf.convert_to_tensor(low_data_list, np.float32)
high_data_list = tf.convert_to_tensor(high_data_list, np.float32)
low_data_list /= 255
high_data_list /= 255
return low_data_list, high_data_list
Ce sera le programme qui générera l'ensemble de données.
def save_frame(path, #Chemin du fichier contenant les données
data_number, #Nombre de photos à couper à partir d'une image
cut_height, #Taille de stockage(Verticale)(Basse résolution)
cut_width, #Taille de stockage(côté)(Basse résolution)
mag, #Grossissement
ext='jpg'):
Voici la définition de la fonction. Comme je l'ai écrit dans le commentaire, path est le chemin du dossier. (Par exemple, si vous avez une photo dans un dossier nommé fichier, tapez "./file".) data_number coupe plusieurs photos et transforme les données. cut_height et cut_wedth sont des tailles d'image basse résolution. Le résultat de sortie final sera la valeur multipliée par le mag de grossissement. Si (cut_height = 300, cut_width = 300, mag = 300, Le résultat est une image d'une taille de 900 * 900. )
path = path + "/*"
files = glob.glob(path)
Ceci est une liste de toutes les photos du fichier.
for img in files:
img = cv2.imread(img, cv2.IMREAD_GRAYSCALE)
H, W = img.shape
cut_height_mag = cut_height * mag
cut_width_mag = cut_width * mag
if cut_height_mag > H or cut_width_mag > W:
return
for q in range(data_number):
ram_h = random.randint(0, H - cut_height_mag)
ram_w = random.randint(0, W - cut_width_mag)
cut_img = img[ram_h : ram_h + cut_height_mag, ram_w: ram_w + cut_width_mag]
#Rétrécir après le flou avec le filtre gaussien
img1 = cv2.GaussianBlur(img, (5, 5), 0)
img2 = img1[ram_h : ram_h + cut_height_mag, ram_w: ram_w + cut_width_mag]
img3 = cv2.resize(img2, (cut_height, cut_width))
high_data_list.append(cut_img)
low_data_list.append(img3)
Ici, je prends les photos listées plus tôt une par une et j'en découpe autant que le nombre de data_number. J'utilise random.randint parce que je veux le couper au hasard. Ensuite, il est flouté avec un filtre gaussien pour générer une image basse résolution. Enfin, je l'ai ajouté à la liste avec append.
#numpy → tensor +Normalisation
low_data_list = tf.convert_to_tensor(low_data_list, np.float32)
high_data_list = tf.convert_to_tensor(high_data_list, np.float32)
low_data_list /= 255
high_data_list /= 255
return low_data_list, high_data_list
Ici, dans keras et tensorflow, il est nécessaire de convertir en tenseur au lieu de tableau numpy, donc la conversion est effectuée. En même temps, la normalisation se fait ici.
Enfin, la fonction se termine par une liste contenant des images basse résolution et une liste contenant des images haute résolution.
Description de main.py
main.py
import tensorflow as tf
from tensorflow.python.keras.models import Model
from tensorflow.python.keras.layers import Conv2D, Input, Lambda
def ESPCN(upsampling_scale):
input_shape = Input((None, None, 1))
conv2d_0 = Conv2D(filters = 64,
kernel_size = (5, 5),
padding = "same",
activation = "relu",
)(input_shape)
conv2d_1 = Conv2D(filters = 32,
kernel_size = (3, 3),
padding = "same",
activation = "relu",
)(conv2d_0)
conv2d_2 = Conv2D(filters = upsampling_scale ** 2,
kernel_size = (3, 3),
padding = "same",
)(conv2d_1)
pixel_shuffle = Lambda(lambda z: tf.nn.depth_to_space(z, upsampling_scale))(conv2d_2)
model = Model(inputs = input_shape, outputs = [pixel_shuffle])
model.summary()
return model
Comme prévu, c'est court.
En passant, quand je regarde le papier ESPCN, j'écris qu'il a une telle structure.
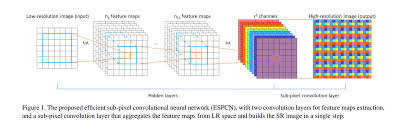 Cliquez ici pour plus de détails sur la couche Convolution → documentation keras
pixel_shuffle n'est pas installé en standard dans keras, je l'ai donc remplacé par lambda.
lambbda représente une expansion car vous pouvez incorporer n'importe quelle expression dans le modèle.
documentation lambda → https://keras.io/ja/layers/core/#lambda
documentation tensorflow → https://www.tensorflow.org/api_docs/python/tf/nn/depth_to_space
Cliquez ici pour plus de détails sur la couche Convolution → documentation keras
pixel_shuffle n'est pas installé en standard dans keras, je l'ai donc remplacé par lambda.
lambbda représente une expansion car vous pouvez incorporer n'importe quelle expression dans le modèle.
documentation lambda → https://keras.io/ja/layers/core/#lambda
documentation tensorflow → https://www.tensorflow.org/api_docs/python/tf/nn/depth_to_space
Il semble y avoir différentes façons de gérer le mélange de pixels ici.
Description de model.py
model.py
import model
import data_create
import argparse
import os
import cv2
import numpy as np
import tensorflow as tf
if __name__ == "__main__":
def psnr(y_true, y_pred):
return tf.image.psnr(y_true, y_pred, 1, name=None)
train_height = 17
train_width = 17
test_height = 200
test_width = 200
mag = 3.0
cut_traindata_num = 10
cut_testdata_num = 1
train_file_path = "../photo_data/DIV2K_train_HR" #Dossier avec photos
test_file_path = "../photo_data/DIV2K_valid_HR" #Dossier avec photos
BATSH_SIZE = 256
EPOCHS = 1000
opt = tf.keras.optimizers.Adam(learning_rate=0.0001)
parser = argparse.ArgumentParser()
parser.add_argument('--mode', type=str, default='espcn', help='espcn, evaluate')
args = parser.parse_args()
if args.mode == "espcn":
train_x, train_y = data_create.save_frame(train_file_path, #Chemin de l'image à recadrer
cut_traindata_num, #Nombre d'ensembles de données générés
train_height, #Taille de stockage
train_width,
mag) #grossissement
model = model.ESPCN(mag)
model.compile(loss = "mean_squared_error",
optimizer = opt,
metrics = [psnr])
#https://keras.io/ja/getting-started/faq/
model.fit(train_x,
train_y,
epochs = EPOCHS)
model.save("espcn_model.h5")
elif args.mode == "evaluate":
path = "espcn_model"
exp = ".h5"
new_model = tf.keras.models.load_model(path + exp, custom_objects={'psnr':psnr})
new_model.summary()
test_x, test_y = data_create.save_frame(test_file_path, #Chemin de l'image à recadrer
cut_testdata_num, #Nombre d'ensembles de données générés
test_height, #Taille de stockage
test_width,
mag) #grossissement
print(len(test_x))
pred = new_model.predict(test_x)
path = "resurt_" + path
os.makedirs(path, exist_ok = True)
path = path + "/"
for i in range(10):
ps = psnr(tf.reshape(test_y[i], [test_height, test_width, 1]), pred[i])
print("psnr:{}".format(ps))
before_res = tf.keras.preprocessing.image.array_to_img(tf.reshape(test_x[i], [int(test_height / mag), int(test_width / mag), 1]))
change_res = tf.keras.preprocessing.image.array_to_img(tf.reshape(test_y[i], [test_height, test_width, 1]))
y_pred = tf.keras.preprocessing.image.array_to_img(pred[i])
before_res.save(path + "low_" + str(i) + ".jpg ")
change_res.save(path + "high_" + str(i) + ".jpg ")
y_pred.save(path + "pred_" + str(i) + ".jpg ")
else:
raise Exception("Unknow --mode")
Le principal est assez long, mais j'ai l'impression que si je peux le raccourcir, je peux faire plus. Ci-dessous, j'expliquerai le contenu.
import model
import data_create
import argparse
import os
import cv2
import numpy as np
import tensorflow as tf
Ici, nous chargeons une fonction ou un autre fichier dans le même répertoire. datacreate.py, model.py et main.py doivent être dans le même répertoire.
def psnr(y_true, y_pred):
return tf.image.psnr(y_true, y_pred, 1, name=None)
Cette fois, j'ai utilisé psnr comme critère pour juger de la qualité de l'image générée, c'est donc la définition. psnr est appelé le rapport signal / bruit de crête et, en termes simples, cela revient à calculer la différence entre les valeurs de pixel des images que vous souhaitez comparer. Je n'expliquerai pas en détail ici, mais cet article est plutôt détaillé et plusieurs méthodes d'évaluation sont décrites.
train_height = 17
train_width = 17
test_height = 200
test_width = 200
mag = 3.0
cut_traindata_num = 10
cut_testdata_num = 1
train_file_path = "../photo_data/DIV2K_train_HR" #Dossier avec photos
test_file_path = "../photo_data/DIV2K_valid_HR" #Dossier avec photos
BATSH_SIZE = 256
EPOCHS = 1000
opt = tf.keras.optimizers.Adam(learning_rate=0.0001)
Ici, la valeur utilisée cette fois est définie. Si vous regardez github, c'est bien si vous avez un config.py séparé, mais comme ce n'est pas un programme à grande échelle, il est résumé.
En ce qui concerne la taille des données d'entraînement, les données du train ont été écrites comme 51 * 51 dans le papier, j'ai donc adopté 17 * 17, qui est la valeur divisée par le mag. Le test est juste surdimensionné pour une visualisation facile. __ Le résultat est trois fois plus grand que cela. __ Le nombre de données correspond à 10 fois le nombre d'images contenues dans le fichier. (Si 800 feuilles, le nombre de données est de 8 000)
Cette fois, j'ai utilisé DIV2K Dataset, qui est souvent utilisé pour la super-résolution. Puisque la qualité des données est bonne, on dit qu'une certaine précision peut être obtenue avec une petite quantité de données.
parser = argparse.ArgumentParser()
parser.add_argument('--mode', type=str, default='espcn', help='espcn, evaluate')
args = parser.parse_args()
Je voulais séparer l'apprentissage et l'évaluation du modèle ici, donc je l'ai fait comme ça pour que je puisse le sélectionner avec --mode. Je ne vais pas expliquer en détail, donc je publierai la documentation officielle de python. https://docs.python.org/ja/3/library/argparse.html
if args.mode == "espcn":
train_x, train_y = data_create.save_frame(train_file_path, #Chemin de l'image à recadrer
cut_traindata_num, #Nombre d'ensembles de données générés
train_height, #Taille de stockage
train_width,
mag) #grossissement
model = model.ESPCN(mag)
model.compile(loss = "mean_squared_error",
optimizer = opt,
metrics = [psnr])
#https://keras.io/ja/getting-started/faq/
model.fit(train_x,
train_y,
epochs = EPOCHS)
model.save("espcn_model.h5")
J'apprends ici. Si vous sélectionnez srcnn (la méthode sera décrite plus tard), ce programme fonctionnera.
Dans data_create.save_frame, la fonction appelée save_frame de data_create.py est lue et rendue disponible. Maintenant que les données sont dans train_x et train_y, chargez le modèle de la même manière et compilez et ajustez.
Voir documentation keras pour plus d'informations sur la compilation et plus encore. Nous utilisons les mêmes que les papiers.
Enfin, enregistrez le modèle et vous avez terminé.
elif args.mode == "evaluate":
path = "espcn_model"
exp = ".h5"
new_model = tf.keras.models.load_model(path + exp, custom_objects={'psnr':psnr})
new_model.summary()
test_x, test_y = data_create.save_frame(test_file_path, #Chemin de l'image à recadrer
cut_testdata_num, #Nombre d'ensembles de données générés
test_height, #Taille de stockage
test_width,
mag) #grossissement
print(len(test_x))
pred = new_model.predict(test_x)
path = "resurt_" + path
os.makedirs(path, exist_ok = True)
path = path + "/"
for i in range(10):
ps = psnr(tf.reshape(test_y[i], [test_height, test_width, 1]), pred[i])
print("psnr:{}".format(ps))
before_res = tf.keras.preprocessing.image.array_to_img(tf.reshape(test_x[i], [int(test_height / mag), int(test_width / mag), 1]))
change_res = tf.keras.preprocessing.image.array_to_img(tf.reshape(test_y[i], [test_height, test_width, 1]))
y_pred = tf.keras.preprocessing.image.array_to_img(pred[i])
before_res.save(path + "low_" + str(i) + ".jpg ")
change_res.save(path + "high_" + str(i) + ".jpg ")
y_pred.save(path + "pred_" + str(i) + ".jpg ")
else:
raise Exception("Unknow --mode")
C'est finalement l'explication du dernier. Tout d'abord, chargez le modèle que vous avez enregistré précédemment afin de pouvoir utiliser psnr. Ensuite, générez un ensemble de données pour le test et générez une image avec prédire.
Je voulais connaître la valeur psnr sur place, alors je l'ai calculée. Je voulais enregistrer l'image, alors je l'ai convertie du tenseur en un tableau numpy, l'ai sauvegardée, et finalement c'est fait!
La résolution a été augmentée fermement ainsi.


5. À la fin
Cette fois, j'ai essayé de construire ESPCN. Je me demande quel papier mettre en œuvre ensuite. Nous attendons toujours avec impatience vos demandes et questions. Merci pour la lecture.