4. Création d'un programme structuré
4.1 Back to the Basics Assignment
L'affectation est l'un des concepts les plus importants d'un programme. Mais il y a des choses incroyables à ce sujet! !!
>>> foo = 'Monty'
>>> bar = foo # (1)
>>> foo = 'Python' # (2)
>>> bar
'Monty'
Dans le code ci-dessus, si vous écrivez bar = foo, la valeur de foo (chaîne de caractères'Monty ') dans (1) sera affectée à bar. En d'autres termes, bar est une copie de foo, donc l'écrasement de foo avec la nouvelle chaîne "Python" sur la ligne (2) n'affecte pas la valeur de bar.
L'affectation copie la valeur d'une expression, mais la valeur n'est pas toujours celle que vous attendez! !! !! En particulier, les valeurs des objets structurés comme les listes ne sont en réalité que des références aux objets! Dans l'exemple suivant, (1) assigne une référence à foo à la barre de variables. Si vous modifiez l'intérieur de foo dans la ligne suivante, la valeur de bar est également modifiée
>>> foo = ['Monty', 'Python']
>>> bar = foo # (1)
>>> foo[1] = 'Bodkin' # (2)
>>> bar
['Monty', 'Bodkin']
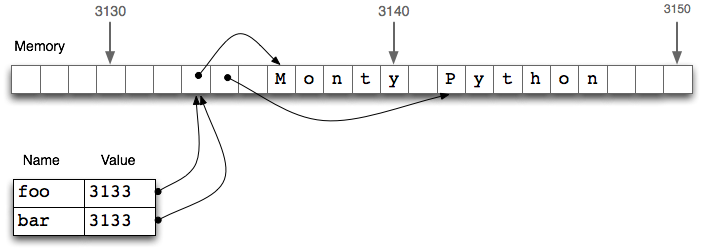
bar = foo ne copie pas le contenu de la variable, seulement sa ** référence d'objet **! !! Il s'agit d'une référence à l'objet stocké à la position 3133 dans foo. Si vous assignez bar = foo, seule la référence d'objet 3133 sera copiée, donc la mise à jour de foo changera également bar!
Créons une variable vide contenant une liste vide et utilisons-la trois fois dans la ligne suivante pour une expérimentation plus approfondie.
>>> empty = []
>>> nested = [empty, empty, empty]
>>> nested
[[], [], []]
>>> nested[1].append('Python')
>>> nested
[['Python'], ['Python'], ['Python']]
Lorsque j'ai changé l'un des éléments de la liste, ils ont tous changé! !! ?? ?? Vous pouvez voir que chacun des trois éléments n'est en fait qu'une référence à une seule et même liste en mémoire! !!
Notez que si vous attribuez une nouvelle valeur à l'un des éléments de la liste, elle ne sera pas reflétée dans les autres éléments!
>>> nested = [[]] * 3
>>> nested[1].append('Python')
>>> nested[1] = ['Monty']
>>> nested
[['Python'], ['Monty'], ['Python']]
La troisième ligne a modifié l'une des trois références d'objet de la liste. Cependant, l'objet "Python" n'a pas changé. C'est parce que vous modifiez l'objet via la référence d'objet, sans écraser la référence d'objet!
Equality Python a deux façons de s'assurer que la paire d'éléments est la même. Teste l'opérateur pour l'identification des objets. Cela peut être utilisé pour valider les observations précédentes sur l'objet.
>>> size = 5
>>> python = ['Python']
>>> snake_nest = [python] * size
>>> snake_nest[0] == snake_nest[1] == snake_nest[2] == snake_nest[3] == snake_nest[4]
True
>>> snake_nest[0] is snake_nest[1] is snake_nest[2] is snake_nest[3] is snake_nest[4]
True
Créez une liste contenant plusieurs copies du même objet et montrez qu'elles ne sont pas seulement identiques selon ==, mais aussi un seul et même objet.
>>> import random
>>> position = random.choice(range(size))
>>> snake_nest[position] = ['Python']
>>> snake_nest
[['Python'], ['Python'], ['Python'], ['Python'], ['Python']]
>>> snake_nest[0] == snake_nest[1] == snake_nest[2] == snake_nest[3] == snake_nest[4]
True
>>> snake_nest[0] is snake_nest[1] is snake_nest[2] is snake_nest[3] is snake_nest[4]
False
La fonction id () facilite la détection!
>>> [id(snake) for snake in snake_nest]
[513528, 533168, 513528, 513528, 513528]
Cela nous indique que le deuxième élément de la liste contient un identifiant séparé!
Conditionals Dans la partie conditionnelle de l'instruction if, une chaîne ou une liste non vide est évaluée à true, et une chaîne ou une liste vide prend la valeur false.
>>> mixed = ['cat', '', ['dog'], []]
>>> for element in mixed:
... if element:
... print element
...
cat
['dog']
En d'autres termes, il n'est pas nécessaire de faire si len (élément)> 0: sous la condition.
>>> animals = ['cat', 'dog']
>>> if 'cat' in animals:
... print 1
... elif 'dog' in animals:
... print 2
...
1
Si elif est remplacé par if, 1 et 2 sont affichés. Par conséquent, la clause elif peut contenir plus d'informations que la clause if.
4.2 Sequences Cette séquence, appelée tuple, est formée par l'opérateur virgule et est placée entre parenthèses. En outre, vous pouvez voir la partie spécifiée en ajoutant un index de la même manière qu'une chaîne de caractères.
>>> t = 'walk', 'fem', 3
>>> t
('walk', 'fem', 3)
>>> t[0]
'walk'
>>> t[1:]
('fem', 3)
>>> len(t)
3
J'ai comparé directement des chaînes, des listes et des taples, et j'ai essayé les opérations d'indexation, de découpage et de longueur pour chaque type!
>>> raw = 'I turned off the spectroroute'
>>> text = ['I', 'turned', 'off', 'the', 'spectroroute']
>>> pair = (6, 'turned')
>>> raw[2], text[3], pair[1]
('t', 'the', 'turned')
>>> raw[-3:], text[-3:], pair[-3:]
('ute', ['off', 'the', 'spectroroute'], (6, 'turned'))
>>> len(raw), len(text), len(pair)
(29, 5, 2)
Operating on Sequence Types
Différentes façons d'itérer une séquence

Utilisez inverse (trié (ensemble (s))) pour trier les éléments uniques de s dans l'ordre inverse. Vous pouvez utiliser random.shuffle (s) pour randomiser le contenu de la liste avant l'itération.
FreqDist peut être converti en séquences!
>>> raw = 'Red lorry, yellow lorry, red lorry, yellow lorry.'
>>> text = word_tokenize(raw)
>>> fdist = nltk.FreqDist(text)
>>> sorted(fdist)
[',', '.', 'Red', 'lorry', 'red', 'yellow']
>>> for key in fdist:
... print(key + ':', fdist[key], end='; ')
...
lorry: 4; red: 1; .: 1; ,: 3; Red: 1; yellow: 2
Réorganisez le contenu de la liste à l'aide de tapples !!
>>> words = ['I', 'turned', 'off', 'the', 'spectroroute']
>>> words[2], words[3], words[4] = words[3], words[4], words[2]
>>> words
['I', 'turned', 'the', 'spectroroute', 'off']
zip () prend deux ou plusieurs séquences d'éléments et les "compresse" ensemble en une seule liste de tuples! Étant donné la séquence s, enumerate (s) renvoie une paire composée de l'index et des éléments de cet index.
>>> words = ['I', 'turned', 'off', 'the', 'spectroroute']
>>> tags = ['noun', 'verb', 'prep', 'det', 'noun']
>>> zip(words, tags)
<zip object at ...>
>>> list(zip(words, tags))
[('I', 'noun'), ('turned', 'verb'), ('off', 'prep'),
('the', 'det'), ('spectroroute', 'noun')]
>>> list(enumerate(words))
[(0, 'I'), (1, 'turned'), (2, 'off'), (3, 'the'), (4, 'spectroroute')]
Combining Different Sequence Types
>>> words = 'I turned off the spectroroute'.split() # (1)
>>> wordlens = [(len(word), word) for word in words] # (2)
>>> wordlens.sort() # (3)
>>> ' '.join(w for (_, w) in wordlens) # (4)
'I off the turned spectroroute'
Une chaîne est en fait un objet dans lequel des méthodes telles que split () sont définies. Créez une liste de taples en utilisant la notation d'inclusion de liste dans (2). Chaque taple se compose d'un nombre (longueur de mot) et d'un mot (par exemple (3, «le»)). Utilisez la méthode sort () pour trier la liste (3) à la volée! Enfin, dans (4), les informations de longueur sont ignorées et les mots sont à nouveau combinés en une chaîne de caractères.
** En Python, les listes sont variables et les taples sont immuables. Autrement dit, vous pouvez changer la liste, mais pas le tapple !!! **
Generator Expressions
>>> text = '''"When I use a word," Humpty Dumpty said in rather a scornful tone,
... "it means just what I choose it to mean - neither more nor less."'''
>>> [w.lower() for w in word_tokenize(text)]
['``', 'when', 'i', 'use', 'a', 'word', ',', "''", 'humpty', 'dumpty', 'said', ...]
Je veux traiter ces mots plus loin.
>>> max([w.lower() for w in word_tokenize(text)]) # (1)
'word'
>>> max(w.lower() for w in word_tokenize(text)) # (2)
'word'
Recommended Posts