Représentation vectorielle de mots simples: word2vec, GloVe
J'ai regardé la vidéo et les diapositives d'un cours appelé "Deep Learning for Natural Language Processing" à l'Université de Stanford récemment, mais je viens de le regarder. J'ai décidé de publier le mémo de cours tout en résumant le contenu car il semble qu'il ne restera pas dans mon corps.
Cette fois, c'est la deuxième "Représentations vectorielles de mots simples: word2vec, GloVe". La première fois était une intro donc je l'ai sauté.
Comment exprimer le sens de chaque mot et ses problèmes
Si vous voulez que votre ordinateur reconnaisse la signification d'un mot, vous pouvez utiliser une table de classification faite à la main telle que WordNet. Cependant, il y a un problème avec de telles expressions.
-Il n'exprime pas de fines nuances (différences de synonymes tels que adepte, expert, bon, pratiqué, compétent, habile) --Je ne peux pas gérer de nouveaux mots --Subjectif --L'humain doit faire de son mieux
- Difficile de calculer la similitude exacte des mots
C'est pourquoi essayer d'exprimer le sens de chaque mot ne fonctionne pas très bien.
Focus sur la similarité de distribution: matrice de cooccurrence de mots
La similitude des mots peut être considérée par la distribution des mots apparaissant dans l'ensemble de documents, et non par la signification linguistique des mots. C'est l'une des idées les plus réussies de la PNL statistique moderne.
Par exemple, si vous avez deux phrases dans lesquelles le mot "banque" apparaît

Je pense que le mot peint en orange représente «banque».
Pour que ce modèle fonctionne sur un ordinateur, la cooccurrence entre les mots doit être représentée par une matrice. Il existe une option pour faire de la taille de la partie orange le document entier ou jusqu'à N caractères avant et après (cette plage est appelée une fenêtre), et en fournissant une fenêtre, le mot peut être dans le document On peut dire que la position et la signification de l'apparence peuvent être prises en considération. La taille de la fenêtre est généralement de 5 à 10. Vous pouvez modifier le poids à gauche et à droite du mot, et vous pouvez également pondérer le mot en fonction de sa distance.
Exemple de matrice de cooccurrence de mots
- I like deep learning.
- I like NLP.
- I enjoy flying.
La matrice de cooccurrence est la suivante lorsque le document est un corpus, la taille de la fenêtre est 1 et les poids sont les mêmes à gauche et à droite du mot:

Problèmes avec la matrice de cooccurrence de mots
―― Puisque le nombre de dimensions augmente en fonction des mots qui apparaissent, plus le corpus est grand, plus la matrice devient grande et clairsemée. ――Si le nombre de dimensions augmente, une grande capacité de stockage peut être nécessaire à moins qu'elle ne soit conçue.
Bref, il manque de robustesse.
L'idée de base de ces problèmes est de les rendre plus petits et plus denses en extrayant uniquement les informations importantes, plutôt que de tout aligner. En général, je veux le compresser à environ 25 à 1000 dimensions. Alors, comment faites-vous cela?
Rendre le mot matrice de cooccurrence dense
Plusieurs méthodes ont été proposées. Ici, SVD, word2vec et GloVe sont repris.
SVD
La première méthode consiste à effectuer une décomposition de singularité (SVD) de la matrice. SVD est implémenté dans numpy afin que vous puissiez l'essayer.
import numpy as np
la = np.linalg
words = ["I", "like", "enjoy", "deep",
"learning", "NLP", "flying", "."]
#↑ Matrice de cooccurrence de mots saisie manuellement
X = np.array([
[0,2,1,0,0,0,0,0],
[2,0,0,1,0,1,0,0],
[1,0,0,0,0,0,1,0],
[0,1,0,0,1,0,0,0],
[0,0,0,1,0,0,0,1],
[0,1,0,0,0,0,0,1],
[0,0,1,0,0,0,0,1],
[0,0,0,0,1,1,1,0]
])
# SVD
U, s, Vh = la.svd(X, full_matrices=False)
Cela rend le vecteur de cooccurrence de mots initialement épars plus dense. Par exemple, pour le mot "profond"
>>> print(X[3])
[0 1 0 0 1 0 0 0]
C'était
>>> print(U[3])
[ -2.56274005e-01 2.74017533e-01 1.59810848e-01 -2.77555756e-16
-5.78984617e-01 6.36550929e-01 8.88178420e-16 -3.05414877e-01]
devenir. Cela ressemble à quelque chose avec cela seul, mais lorsque je ne prends que les dimensions 0 et 1 et que je trace chaque mot dans un espace 2D, en quelque sorte «profond» et «PNL» sont proches, ou «appréciez» Il semble que "et" apprendre "sont similaires.
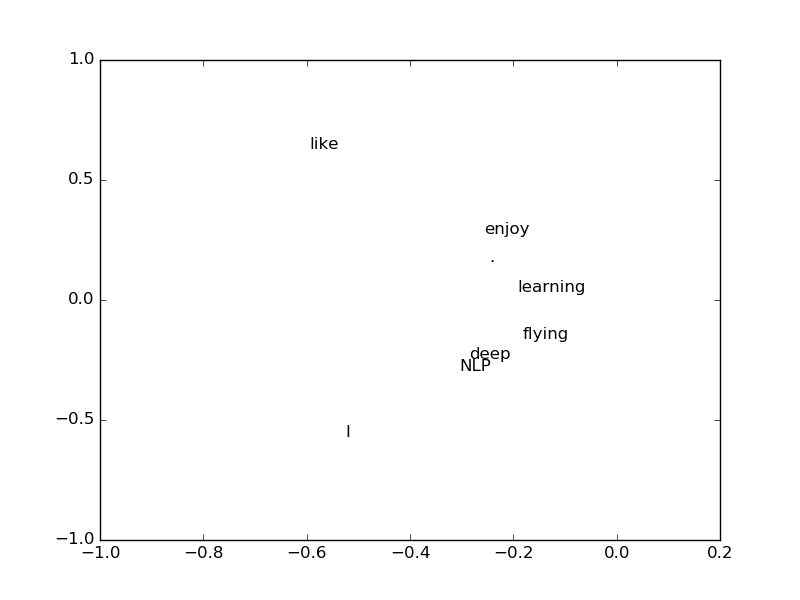
Contenu de SVD
En passant, je pense que la validité de l'utilisation de SVD n'a pas été mentionnée dans la conférence. Puisque j'ai mentionné "l'analyse sémantique latente", il se peut que vous deviez y regarder.
En utilisant SVD, la matrice $ n \ fois n $ $ X $ de rang $ r $ est la matrice orthogonale de colonne $ U $ et $ V $ de $ n \ fois r $, et l'élément diagonal de $ D $. Il peut être décomposé comme suit en utilisant la matrice $ r \ times r $ $ S $ dans laquelle les valeurs singulières sont arrangées.
X = U S V^T
À ce stade, si vous mettez $ S V ^ T $ comme $ W $
X = U W
devenir. On peut dire que $ X $ est une sorte de matrice $ W $ convertie par $ U $. Au fait, puisque $ U $ est une matrice orthogonale de colonne, les vecteurs de colonne sont indépendants les uns des autres. En d'autres termes, c'est la base d'un espace, mais en réalité c'est un espace de mots, et chaque vecteur de colonne peut être considéré comme représentant une signification potentielle.
Problèmes avec SVD
SVD peut également être généralisé et appliqué à des matrices $ n \ times m $. Si $ n <m $, le coût de calcul pour calculer à partir d'une telle matrice est $ O (mn ^ 2) $, donc la taille énorme ne peut pas être appliquée à la matrice. C'est pourquoi il est difficile d'incorporer de nouveaux mots lorsqu'ils sortent.
word2vec
Diverses méthodes ont été proposées, mais le word2vec proposé par Mikolov et al de Google en 2013 attire l'attention.
L'idée de word2vec est de "traiter de manière probabiliste les mots qui apparaissent dans la zone environnante, plutôt que de traiter directement le nombre de cooccurrences". Il est plus rapide et plus facile d'ajouter de nouveaux mots.
word2vec est aussi langage C, Java, [Python](http: // radimrehurek. Il existe une implémentation dans com / gensim /) pour que vous puissiez l'essayer.
théorie
Considérez une fenêtre de taille c avant et après chaque mot, considérez la probabilité qu'elle y apparaisse pour chaque mot de la fenêtre, et utilisez la somme de celles-ci comme fonction objective pour estimer la plus probable. Le journal est utilisé pour faciliter le calcul ultérieur.
J(\theta) = \frac{1}{T} \sum_{t=1}^T \sum_{-c \leq j \leq c,j \neq 0} \log p(w_{t+j} | w_t)
Relation de vecteur
Les mots sont représentés sous forme de vecteurs en utilisant word2vec. A ce moment, on sait qu'un résultat intéressant peut être obtenu à partir de la différence entre les vecteurs de mots.
Par exemple, soustraire Man de King et ajouter Woman le rend très proche du vecteur de Queen. On peut penser que le vecteur formé en soustrayant l'homme du roi représente un concept puissant.
X_{king} - X_{man} + X_{woman} \approx X_{queen}
Il semble y avoir une histoire selon laquelle si vous analysez le corpus japonais avec mecab et faites la même chose, vous retirez Yahoo de Google et ajoutez Toyota pour devenir Nissan.
- https://plus.google.com/107334123935896432800/posts/JvXrjzmLVW4
la vitesse
word2vec peut apprendre à grande vitesse même pour un énorme corpus. Il semble qu'il ait pu apprendre un corpus d'environ 2 Go, qui est un document Wikipedia japonais compressé en bz2, en 30 minutes environ.
J'avais l'habitude d'essayer LDA sur Wikipedia japonais en utilisant GenSim, mais je me souviens que cela prenait une demi-journée à ce moment-là. Même s'il est implémenté en langage C et que les spécifications de la machine sont supérieures à celles de l'époque, il ne fait aucun doute que word2vec est extrêmement plus rapide.
GloVe
Nous avons vu qu'il existe des méthodes basées sur le nombre d'occurrences de mots de type SVD et des approches qui les traitent de manière probabiliste comme word2vec, mais chacune présente des avantages et des inconvénients.
--Méthode basée sur le nombre d'apparitions ―― Un petit corpus peut être appris à grande vitesse, mais un grand corpus prend du temps. ――Il est utilisé pour mesurer la similitude des mots, mais les mots qui apparaissent moins fréquemment peuvent gagner une importance disproportionnée.
- Méthode basée sur la probabilité
- Vous devez avoir un gros corpus.
- Des modèles complexes autres que la similitude des mots peuvent également être mesurés.
Il existe une méthode appelée GloVe qui combine les deux mondes ensemble ([Richard Socher](http: // www) qui est en charge de cette conférence. Proposé par un groupe de .socher.org /) et al.
--Apprentissage rapide -Peut gérer de grands corpus --Petit corpus, les performances des petits vecteurs sont bonnes
Recommended Posts