Créez un Discord Bot qui peut rechercher et coller des images
J'ai créé un robot qui peut rechercher des images, donc j'écrirai les connaissances à ce moment-là.
Ce que j'ai fait
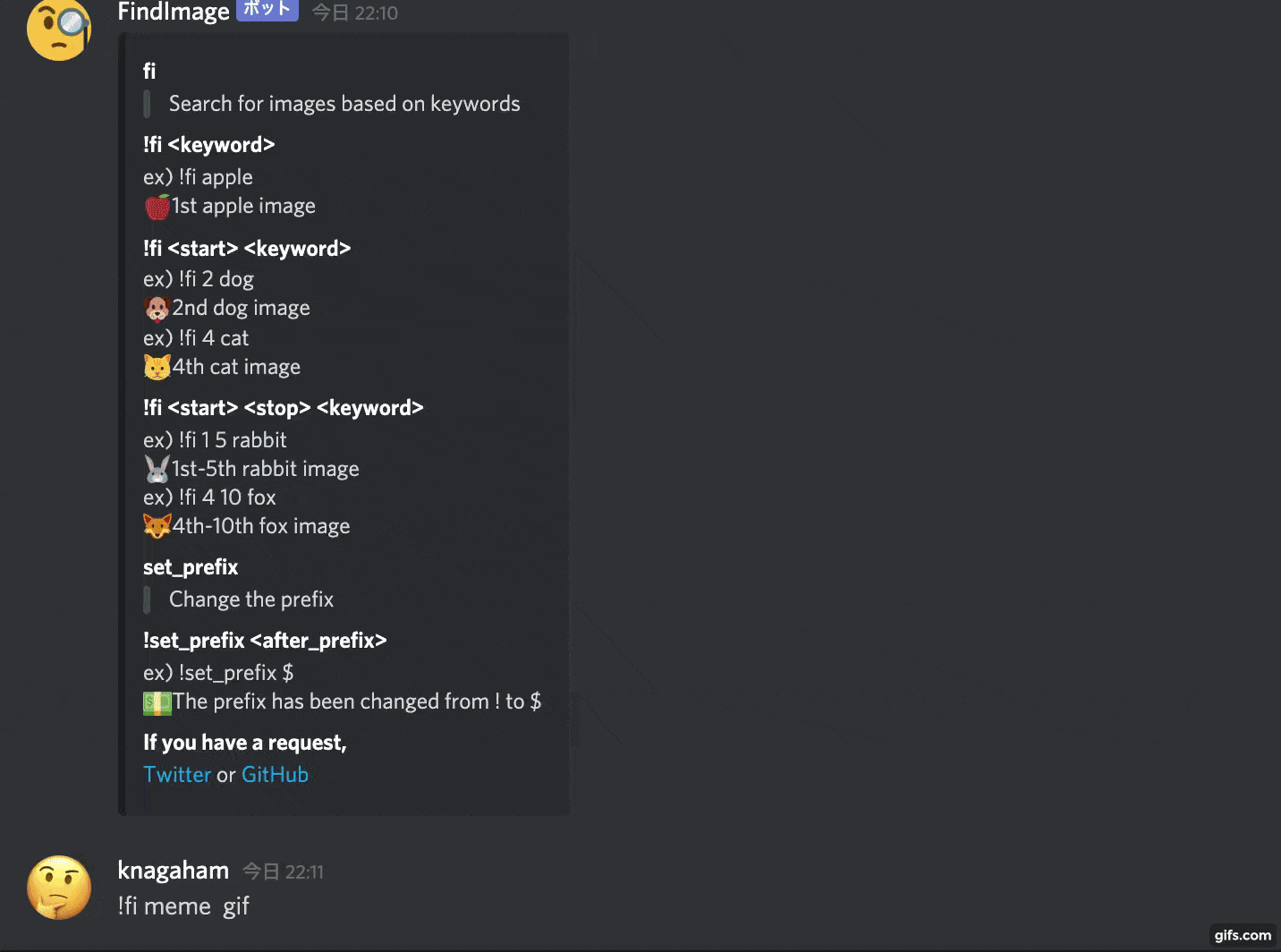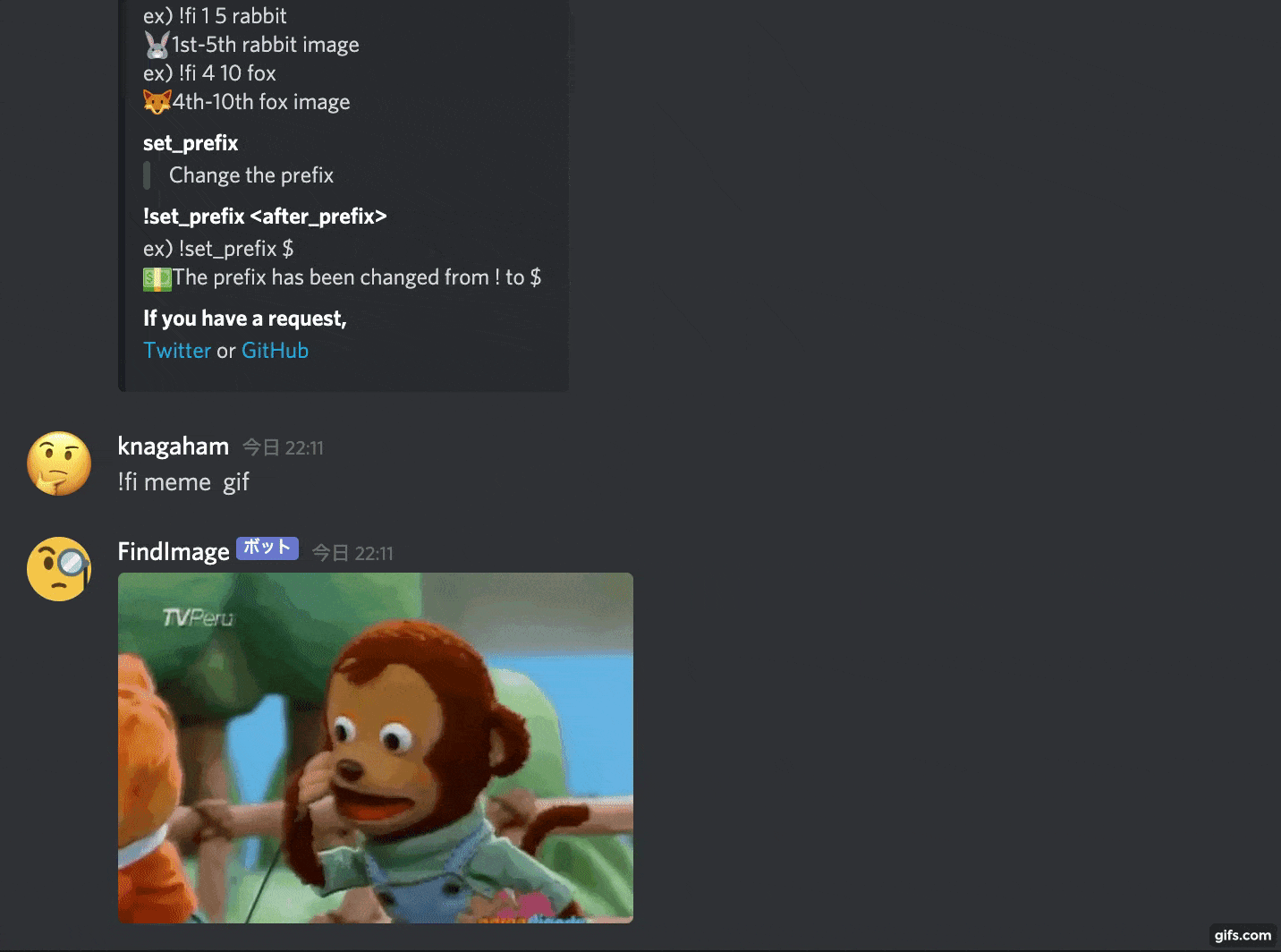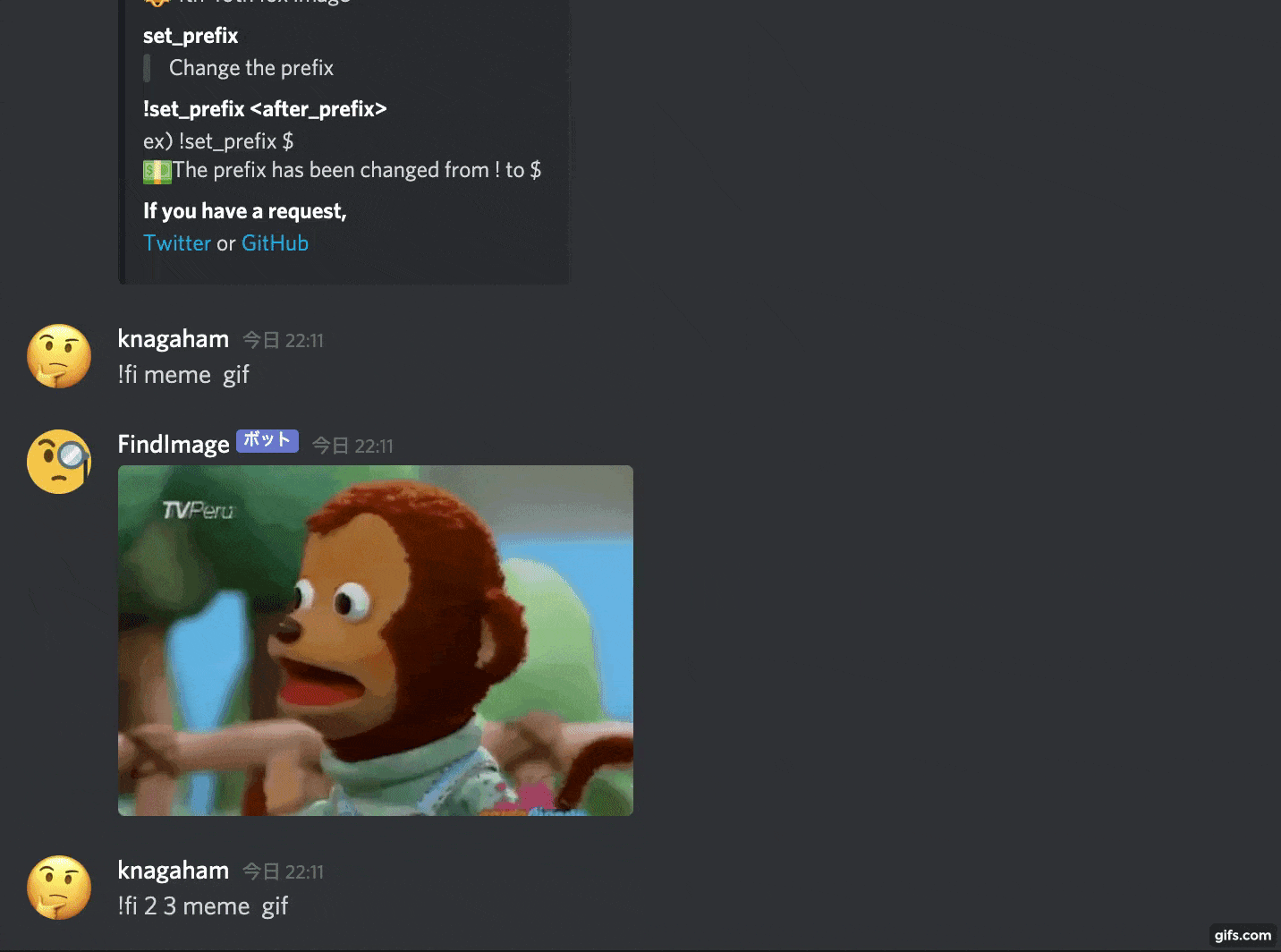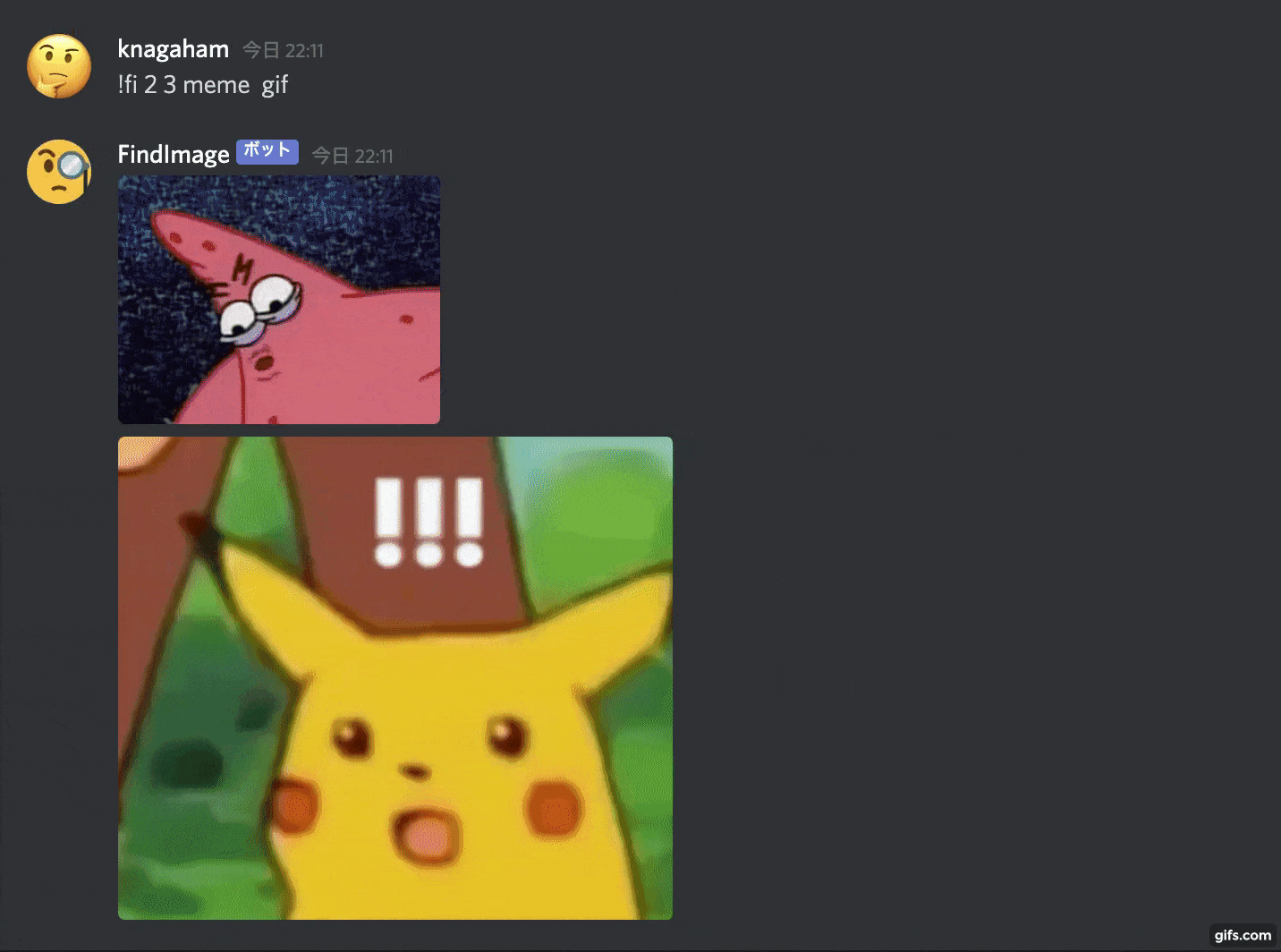
Comme ça, il recherchera une image à partir du mot-clé donné et la collera.
L'installation peut se faire depuis ici, alors n'hésitez pas à nous contacter
Code source (github)
environnement
- python 3.7.9
- discord.py 1.5.1
- bs4 0.0.1
- psycopg2 2.8.6
- urllib3 1.25.11
Comment utiliser Discord.py
Créé en référence à cet article fait. Si vous n'avez pas touché Discord.py, nous vous recommandons de lire ceci en premier.
Rechercher des images et obtenir l'URL
Obtenir des résultats de recherche d'images
Utilisez urllib pour rechercher des images et obtenir du code HTML. À ce stade, le contenu de html va changer, assurez-vous donc de spécifier User-Agent.
find_image.py
from urllib import request as req
from urllib import parse
def find_image(keyword):
urlKeyword = parse.quote(keyword)
url = 'https://www.google.com/search?hl=jp&q=' + urlKeyword + '&btnG=Google+Search&tbs=0&safe=off&tbm=isch'
headers = {"User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:47.0) Gecko/20100101 Firefox/47.0",}
request = req.Request(url=url, headers=headers)
page = req.urlopen(request)
html = page.read()
page.close()
return html
Obtenir l'URL de l'image
Normalement, lorsque vous obtenez une image en grattant, vous pouvez l'obtenir à partir de la balise img, mais dans le cas de la recherche d'images Google, vous ne pouvez obtenir qu'une image compressée. Donc, pour obtenir l'image originale, je dois cliquer pour l'obtenir comme cet article sur Selenium etc. , Je prends une autre méthode cette fois compte tenu de la charge et de la vitesse. En guise de publicité, j'ai écrit un article sur les astuces pour accélérer Beautiful Soup, alors veuillez vous référer à ici si vous le souhaitez.
Si User-Agent est spécifié dans le navigateur, l'appel de méthode est implémenté dans la balise sctipt comme indiqué ci-dessous, utilisez-le donc.
python
<script nonce>
AF_initDataCallback({
key: 'ds:1',
isError: false,
hash: '2',
data: [null, [
[
["g_1", [
["Crème fraîche", ["https://encrypted-tbn0.gstatic.com/images?q\u003dtbn%3AANd9GcR_QK2ghJ5WWcj-Tcf9znnP6_rZwe7f2MCwWUERoVqVLNRFsj4D\u0026usqp\u003dCAU", null, null, true, [null, 0], false, false], "/search?q\u003d%E3%83%97%E3%83%AA%E3%83%B3\u0026tbm\u003disch\u0026chips\u003dq:%E3%83%97%E3%83%AA%E3%83%B3,g_1:%E7%94%9F+%E3%82%AF%E3%83%AA%E3%83%BC%E3%83%A0:FuBfrMHhliU%3D", null, null, [null, null, null, null, "q:Pudding,g_1:Crème fraîche:FuBfrMHhliU\u003d"], 0],
["épicerie", ["https://encrypted-tbn0.gstatic.com/images?q\u003dtbn%3AANd9GcThveHaG9uvSFj6QwXIVDoJPs9P3KjNdnl-I35Wf0WzAKNffK_m\u0026usqp\u003dCAU", null, null, true, [null, 0], false, false], "/search?q\u003d%E3%83%97%E3%83%AA%E3%83%B3\u0026tbm\u003disch\u0026chips\u003dq:%E3%83%97%E3%83%AA%E3%83%B3,g_1:%E3%82%B3%E3%83%B3%E3%83%93%E3%83%8B:tHwRIJyFAco%3D", null, null, [null, null, null, null, "q:Pudding,g_1:épicerie:tHwRIJyFAco\u003d"], 1],
.......
Cependant, comme il s'agit d'un auteur-compositeur et que l'emplacement de la recherche diffère en fonction du mot-clé, il ne peut pas être acquis avec le sélecteur xpath ou css, il ne peut pas être réduit car aucun attribut n'est spécifié, et après avoir développé les variables Comme il est au format json de, il ne peut pas être facilement converti en données json. Alors j'ai poussé ** Gori **. Tout d'abord, récupérez toutes les balises de script, recherchez le contenu qui commence par AF_initDataCallback et formatez-le de force pour que json puisse le lire. Cependant, comme la structure n'est pas un type de dictionnaire mais un tableau, l'index est acquis de manière fixe. Pour être honnête, la méthode de Slekiping est ci-dessous, mais j'ai compromis avec cette implémentation car la vitesse est requise comme ce bot.
find_image.py
import bs4
def scrap_image_urls(html, start = 0, stop = 1)):
soup = bs4.BeautifulSoup(html, 'html.parser', from_encoding='utf8')
soup = soup.find_all('script')
data = [c for s in soup for c in s.contents if c.startswith('AF_initDataCallback')][1]
data = data[data.find('data:') + 5:data.find('sideChannel') - 2]
data = json.loads(data)
data = data[31][0][12][2]
image_urls= [x[1][3][0] for x in data if x[1]]
image_urls= [url for url in image_urls if not is_exception_url(url)][start:stop]
return image_urls
Cependant, les sites qui prennent des mesures contre le grattage comme Instagram jouent parce qu'ils ne peuvent pas obtenir l'URL.
find_image.py
exception_urls = [
'.cdninstagram.com',
'www.instagram.com'
]
def is_exception_url(str):
return any([x in str for x in exception_urls])
Modifier dynamiquement le préfixe
Implémentation de la fonction de conversion du préfixe (préfixe au début de la commande). Il existe différentes méthodes, mais cette fois j'utilise Heroku Postgres. Au début, je l'ai géré avec un fichier json, mais heroku est réinitialisé tous les jours, donc les données ont été époustouflées. .. .. Le flux de déploiement vers heroku est [Premier article introduit](https://qiita.com/1ntegrale9/items/9d570ef8175cf178468f#%E3%81%AF%E3%81%98%E3%82%81%E3% Veuillez vous référer à 81% AB) pour plus de détails. ** Vous devez installer la commande psql. ** **
Ajouter le module complémentaire Heroku Postgres
Ajoutez des modules complémentaires avec hobby-dev, un plan gratuit. Le nombre maximum de lignes d'enregistrement est de 10K.
$ heroku addons:create heroku-postgresql:hobby-dev -a [APP_NAME]
Accès à la base de données
Vérifiez d'abord le nom de la base de données créée. Voir la ligne Add-on
heroku pg:info -a discordbot-findimage
Accédez ensuite à la base de données. Veuillez utiliser le nom de la base de données que vous avez obtenu précédemment
heroku pg:psql [DATABASE_NAME] -a [APP_NAME]
Maintenant que vous pouvez exécuter SQL, créez une table.
create table guilds (
id varchar(255) not null,
prefix varchar(255) not null,
PRIMARY KEY (id)
);
Accéder à PostgreSQL depuis Python
Cette fois, j'utilise psycopg2. L'URL de la base de données est définie dans la variable d'environnement au moment de la création, utilisez-la donc.
find_image.py
import psycopg2
db_url = os.environ['DATABASE_URL']
conn = psycopg2.connect(db_url)
Appliquer dynamiquement le préfixe pour chaque serveur Discord
discord.Client peut passer une méthode dans le constructeur, alors passez-la lors de la création d'une instance. L'exemple utilise ** discord.ext.commands.Bot **, qui est une classe enfant de discord.Client.
find_image.py
from discord.ext import commands
import psycopg2
defalut_prefix = '!'
table_name = 'guilds'
async def get_prefix(bot, message):
return get_prefix_sql(str(message.guild.id))
def get_prefix_sql(key):
with conn.cursor() as cur:
cur.execute(f'SELECT * FROM {table_name} WHERE id=%s', (key, ))
d = cur.fetchone()
return d[1] if d else defalut_prefix
bot = commands.Bot(command_prefix=get_prefix)
Définir le préfixe pour chaque serveur Discord
Dans ce cas, lorsque la commande set_prefix est exécutée, la requête UPSERT est exécutée.
find_image.py
from discord.ext import commands
import psycopg2
table_name = 'guilds'
def set_prefix_sql(key, prefix):
with conn.cursor() as cur:
cur.execute(f'INSERT INTO {table_name} VALUES (%s,%s) ON CONFLICT ON CONSTRAINT guilds_pkey DO UPDATE SET prefix=%s', (key, prefix, prefix))
conn.commit()
@bot.command()
async def set_prefix(ctx, prefix):
set_prefix_sql(str(ctx.guild.id), prefix)
await ctx.send(f'The prefix has been changed from {ctx.prefix} to {prefix}')
finalement
Merci d'avoir lu jusqu'ici! J'espère que cela vous sera utile lors de la création et du scraping Discord Bot!
Recommended Posts