Prédire l'avenir avec l'apprentissage automatique - Prédire les cours futurs des actions avec l'arbre de décision de scikit-learn
Cet article est une continuation de précédent, mais [apprentissage automatique avec scikit-learn](http://qiita.com/ynakayama/items/ Je voudrais écrire une histoire qui prédit réellement l'avenir en utilisant 9c5867b6947aa41e9229).
Quoi qu'il en soit, regardez d'abord la figure ci-dessous.

Cette fois également, nous utiliserons les données sur les cours des actions comme données à tester. La figure ci-dessus montre le cours de l'action de notre société (DTS), qui est une véritable donnée.
Comme le montre la figure, laissez l'ordinateur apprendre les informations «ce qui s'est passé à la suite du changement du cours de l'action passé» en utilisant l'apprentissage automatique, et essayez de prédire le cours futur de l'action en fonction de celui-ci.
Algorithme d'arbre de décision
Cette fois, nous utiliserons l'arbre de décision (digi tree) parmi les nombreuses méthodes de classification. Veuillez vous référer à Article précédemment écrit pour la raison du choix de la méthode.
Je pense qu'il serait rapide de lire l'explication de l'arbre de décision lui-même autour de Wikipedia. Je vais.
Vous pouvez également trouver une description de l'arbre de décision implémenté dans scikit-learn dans la documentation officielle (http://scikit-learn.org/stable/modules/tree.html).
Lorsque vous lisez le document, il semble que quelque chose de difficile soit écrit en anglais, mais en un mot, comment utiliser scikit-learn consiste à entraîner le tableau numérique (train_X) et le tableau de résultats (train_y) des données de l'enseignant. , Étant donné un tableau de nombres pour les données de test (test_X), le résultat de la prédiction (test_y) est renvoyé.
Cette fois, nous nous concentrons sur la façon de l'utiliser, alors omettons la théorie détaillée et essayons-la.
Les données sur le cours de l'action au moment de la rédaction sont les suivantes.
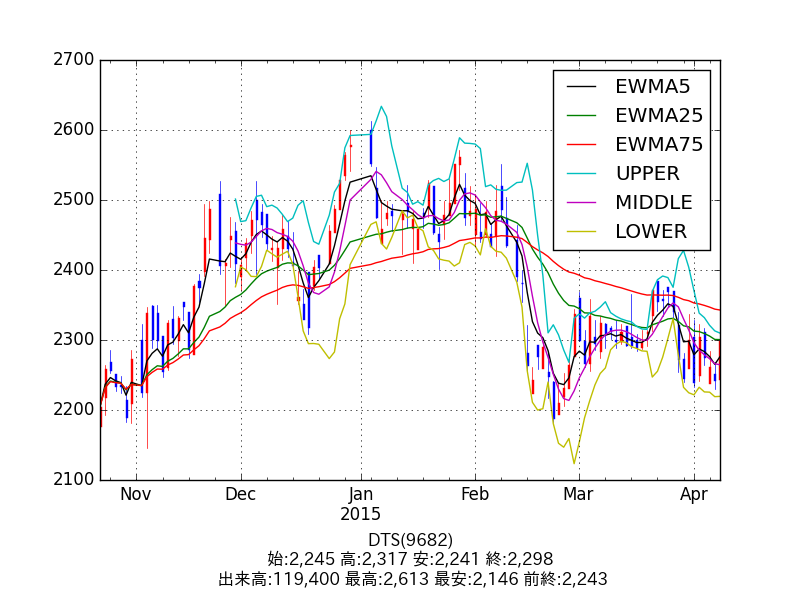
Il s'agit des données des 120 derniers jours ouvrables du 4/8 de DTS (9682) [matplotlib](http: Il est tracé sur //matplotlib.org/). Dans le graphique journalier, le rouge est la ligne positive, le bleu est la ligne négative, EWMA est la moyenne mobile de lissage exponentiel et les trois autres sont des bandes de Bollinger.
Créer des données sur les enseignants
Tout d'abord, préparez le code du cours de clôture ajusté le plus gênant du cours de l'action à la création des données de l'enseignant. Ce serait bien si vous passiez une liste de prix de clôture et qu'elle renverrait train_X et train_y.
def train_data(arr):
train_X = []
train_y = []
#Apprenez 30 jours de données et revenez un jour à la fois
for i in np.arange(-30, -15):
s = i + 14 #14 jours de changement
feature = arr.ix[i:s]
if feature[-1] < arr[s]: #Le cours de l'action a-t-il augmenté le lendemain?
train_y.append(1) #Si OUI, 1
else:
train_y.append(0) #0 pour NON
train_X.append(feature.values)
#Renvoie le résultat de la montée et de la descente et un ensemble de données de l'enseignant
return np.array(train_X), np.array(train_y)
Cela renverra train_X (un tableau de données d'enseignant) et train_y (une étiquette 1 ou 0 pour cela).
Calculer l'indice de retour
En passant, si les données brutes sur le cours des actions sont utilisées telles quelles, la fourchette de prix est complètement différente pour chaque entreprise, il est donc un peu difficile à utiliser comme données sur les enseignants. Normalisation est bien, mais voici le changement de valeur de l'élément Faisons attention à l'indice de retour qui représente. J'ai aussi écrit précédent pour la méthode de calcul, mais elle peut être calculée par pandas comme ceci.
returns = pd.Series(close).pct_change() #Trouvez le taux d'augmentation / diminution
ret_index = (1 + returns).cumprod() #Trouvez le produit cumulatif
ret_index[0] = 1 #Première valeur 1.Mettre à 0
Laissez l'arbre de décision apprendre le changement de l'indice de retour
Eh bien, voici le kimo. Les données de l'enseignant sont extraites de l'indice de retour ainsi obtenu et formées par le classificateur.
#Extraire les données de l'enseignant de l'index de retour
train_X, train_y = train_data(ret_index)
#Générer une instance de l'arbre de décision
clf = tree.DecisionTreeClassifier()
#Apprendre
clf.fit(train_X, train_y)
Après cela, le résultat de la prédiction sera renvoyé en passant les données de test à la fonction clf.predict ().
Si 1 est renvoyé, le cours de l'action «augmentera» Si 0 est renvoyé, le cours de l'action «baissera» Ce sera prédit.
Essayez le classificateur pour voir si vous avez bien appris
Essayons-le tout de suite. Tout d'abord, en tant que test, exécutons exactement les mêmes données que les données de l'enseignant en tant que données de test.
test_y = []
#Test avec les données des 30 derniers jours
for i in np.arange(-30, -15):
s = i + 14
#Classifions exactement la même période de l'indice de retour en tant que test
test_X = ret_index.ix[i:s].values
#Stocker et renvoyer les résultats
result = clf.predict(test_X)
test_y.append(result[0])
print(train_y) #La réponse à laquelle vous devez vous attendre
#=> [1 1 1 0 1 1 0 0 0 1 0 1 0 0 0]
print(np.array(test_y)) #Prédiction émise par le classifieur
#=> [1 1 1 0 1 1 0 0 0 1 0 1 0 0 0]
Oh, exactement pareil. En d'autres termes, il semble que toutes les questions soient correctes.
Prédire le cours de clôture de 4/9
Prédisons maintenant le cours de l'action le 4/9 au moment de la rédaction.
Sur la base des données de 90 jours ouvrables jusqu'à 4/8, c'est ce à quoi nous nous attendions.
[ 1.00834065 1.01492537 1.04126427 1.03424056 1.03467954 1.0403863
1.02765584 0.99780509 0.98595259 1.00965759 0.9833187 1.01141352
0.99912204 0.99297629] # 4/Indice de retour sur 14 jours jusqu'à 8
[0] #Les prédictions qui en découlent
La réponse est 0, ce qui signifie que le cours de l'action va baisser.
En passant, si vous regardez la page Yahoo! Finance après la fermeture du marché le 4/9, comme prévu.
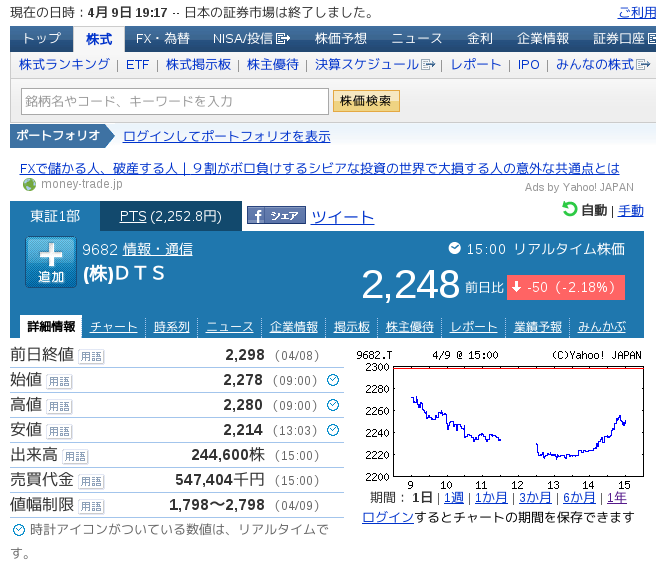
Le cours de l'action a chuté de 50 yens, comme prévu par l'arbre de décision. Est la bonne réponse.
Prédisez le cours de clôture de 4/10
Enfin, contestons la prédiction de l'avenir. Prédisez le cours de clôture de 4/10.
Cela semble persistant, mais cet article a été écrit le 4/9. Veuillez confirmer.
[ 1.01492537 1.04126427 1.03424056 1.03467954 1.0403863 1.02765584
0.99780509 0.98595259 1.00965759 0.9833187 1.01141352 0.99912204
0.99297629 0.98463565] # 4/Indice de rendement sur 14 jours jusqu'à 9
[1] #L'arbre de décision devrait être 1
La réponse est 1, ce qui signifie que les cours des actions devraient augmenter demain.
Résumé
Qu'as-tu pensé. Je pense que j'ai pu faire des prédictions intéressantes.
S'il s'agit d'un taux de réussite sur 100, vous pouvez réaliser un profit en achetant aujourd'hui et en vendant demain. Peut-être que la prédiction était fausse, et je me demande peut-être si j'ai écrit un article décevant à cette heure demain.
Je pense que les investisseurs regardent désespérément le graphique boursier et prédisent s'il augmentera ou baissera demain. Ce que j'ai écrit cette fois, c'est d'utiliser un arbre de décision, qui est une méthode d'apprentissage automatique, et d'essayer de laisser un ordinateur le faire. Soi-disant intelligence artificielle.
Bien entendu, en se référant à ce qui est écrit ici, nous ne garantissons pas même si vous effectuez réellement une transaction authentique, et l'auteur n'assumera aucune responsabilité même en cas de dommage. Veuillez noter ce point.
Recommended Posts