Visualisation des données par préfecture
Qu'est-ce que c'est
J'ai créé une bibliothèque (japanmap) pour ** Python3 ** qui code en couleur les cartes du Japon par préfecture, je vais donc la présenter. L'exemple d'exécution est confirmé sur le Jupyter Notebook.
Installation
Vous pouvez le faire avec pip. numpy [^ 1], OpenCV et Pillow sont également installés. xlrd est utilisé pour lire les fichiers Excel.
bash
pip install -U japanmap jupyter matplotlib pandas xlrd
Qu'est-ce qu'un code de préfecture?
Code de préfecture (ci-après abrégé en code de préfecture) est 01 pour chaque préfecture spécifiée par JIS X 0401. À partir de 47 codes. Le programme le traite comme un entier (en ignorant le 0).
Confirmation du nom de la préfecture
Vous pouvez trouver le nom de la préfecture pour chaque code de préfecture avec pref_names.
python3
from japanmap import pref_names
pref_names[1]
>>>
'Hokkaido'
Vous pouvez trouver le code de préfecture pour le nom de la préfecture avec pref_code.
python3
from japanmap import pref_code
pref_code('Kyoto'), pref_code('Kyoto府')
>>>
(26, 26)
Vous pouvez trouver le code de préfecture pour chacune des huit divisions régionales en groupes.
python3
from japanmap import groups
groups['Kanto']
>>>
[8, 9, 10, 11, 12, 13, 14]
Carte blanche
Vous pouvez obtenir une carte blanche (données raster) avec une image.
python3
%config InlineBackend.figure_formats = {'png', 'retina'}
%matplotlib inline
import matplotlib.pyplot as plt
from japanmap import picture
plt.rcParams['figure.figsize'] = 6, 6
plt.imshow(picture());

Vous pouvez également peindre la préfecture avec de la couleur.
python3
plt.imshow(picture({'Hokkaido': 'blue'}));

Enregistrer dans un fichier PNG
Vous pouvez l'enregistrer dans un fichier avec savefig.
python3
plt.imshow(picture({'Hokkaido': 'blue'}))
plt.savefig('japan.png')
Informations adjacentes
Avec is_faced2sea, vous pouvez voir si la zone comprenant l'emplacement du bureau fait face à la mer pour le code préfecture.
python3
from japanmap import is_faced2sea
for i in [11, 26]:
print(pref_names[i], is_faced2sea(i))
>>>
Préfecture de Saitama Faux
Préfecture de Kyoto Vrai
Avec is_sandwiched2sea, vous pouvez voir si la zone comprenant l'emplacement du bureau est prise en sandwich entre la mer pour le code de préfecture. (Y a-t-il deux plages non continues ou plus?)
python3
from japanmap import is_sandwiched2sea
for i in [2, 28]:
print(pref_names[i], is_sandwiched2sea(i))
>>>
Préfecture d'Aomori Faux
Préfecture de Hyogo Vrai
Adjacent montre le code de préfecture où la zone comprenant l'emplacement de l'agence est adjacente au code de préfecture.
python3
from japanmap import adjacent
for i in [2, 20]:
print(pref_names[i], ':', ' '.join([pref_names[j] for j in adjacent(i)]))
>>>
Préfecture d'Aomori:Préfecture d'Iwate Préfecture d'Akita
Préfecture de Nagano:Préfecture de Gunma Préfecture de Saitama Préfecture de Niigata Préfecture de Toyama Préfecture de Yamanashi Préfecture de Gifu Préfecture de Shizuoka Préfecture d'Aichi
Données vectorielles borderline
Vous pouvez obtenir la liste de points et la liste d'index de points de chaque préfecture avec get_data. Vous pouvez l'utiliser pour obtenir une liste des limites de préfecture (liste d'index) avec pref_points.
python3
from japanmap import get_data, pref_points
qpqo = get_data()
pnts = pref_points(qpqo)
pnts[0] #Coordonnées de la limite de Hokkaido(Longitude latitude)liste
>>>
[[140.47133887410146, 43.08302992960164],
[140.43751046098984, 43.13755540826223],
[140.3625317793531, 43.18162745988813],
...
Vous pouvez visualiser les données de bordure avec pref_map.
python3
from japanmap import pref_map
svg = pref_map(range(1,48), qpqo=qpqo, width=2.5)
svg

Enregistrer dans un fichier SVG
pref_map est au format SVG. Vous pouvez l'enregistrer dans un fichier comme suit.
python3
with open('japan.svg', 'w') as fp:
fp.write(svg.data)
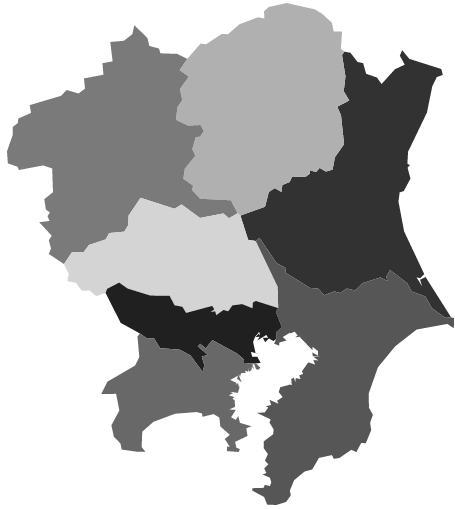
Un exemple d'échelle de gris uniquement dans Kanto.
python3
pref_map(groups['Kanto'], cols='gray', qpqo=qpqo, width=2.5)
Convertir le ratio de superficie de la préfecture en utilisant les données de la préfecture (population)
Convertissons le ratio de superficie sur la carte par le ratio de population. Données démographiques de "Je vois, Académie des statistiques" du Bureau des statistiques du Ministère de l'intérieur et des communications Appuyez sur "Source Statistics Table" au bas de l'écran en 2017 Téléchargeons le fichier (a00400.xls) de la population [^ 2] par préfecture.
python3
import pandas as pd
df = pd.read_excel('a00400.xls', usecols=[9, 12, 13, 14], skiprows=18, skipfooter=3,
names='Hommes et femmes de la préfecture total hommes et femmes'.split()).set_index('Préfectures')
df[:3]
| Total sexe | Homme | femme | |
|---|---|---|---|
| Préfectures | |||
| Hokkaido | 5320 | 2506 | 2814 |
| Préfecture d'Aomori | 1278 | 600 | 678 |
| Préfecture d'Iwate | 1255 | 604 | 651 |
Présentons-les par ordre décroissant du ratio de population. Le ratio de Tokyo à «5,09» est 5,09 fois la moyenne de la préfecture.
python3
df['rapport'] = df.Total sexe/ df.Total sexe.mean()
df.sort_values('rapport', ascending=False)[:10]
| Total sexe | Homme | femme | rapport | |
|---|---|---|---|---|
| Préfectures | ||||
| Tokyo | 13724 | 6760 | 6964 | 5.090665 |
| Préfecture de Kanagawa | 9159 | 4569 | 4590 | 3.397362 |
| Préfecture d'Osaka | 8823 | 4241 | 4583 | 3.272729 |
| Préfecture d'Aichi | 7525 | 3764 | 3761 | 2.791260 |
| Saitama | 7310 | 3648 | 3662 | 2.711510 |
| Préfecture de Chiba | 6246 | 3103 | 3143 | 2.316839 |
| Préfecture de Hyogo | 5503 | 2624 | 2879 | 2.041237 |
| Hokkaido | 5320 | 2506 | 2814 | 1.973356 |
| Préfecture de Fukuoka | 5107 | 2415 | 2692 | 1.894348 |
| Préfecture de Shizuoka | 3675 | 1810 | 1866 | 1.363174 |
Visualisons-le.
Vous pouvez convertir la superficie de la préfecture au ratio spécifié avec trans_area.
Par exemple, si le ratio de conversion pour chaque préfecture est «[2, 1, 1, 1, ...]», Hokkaido aura deux fois la superficie d'origine et les autres préfectures auront le même ratio que la zone d'origine.
Dans ce qui suit, si la population est deux fois la moyenne, la superficie sera doublée.
python3
from japanmap import trans_area
qpqo = get_data(True, True, True)
pref_map(range(1,48), qpqo=trans_area(df.Total sexe, qpqo), width=2.5)

J'ai essayé de le rendre rugueux et de réduire au maximum la distorsion, mais c'est assez grave.
Visualisez la population sur une carte blanche
En procédant comme suit, vous pouvez visualiser la préfecture avec une grande population en rouge foncé.
python3
cmap = plt.get_cmap('Reds')
norm = plt.Normalize(vmin=df.Total sexe.min(), vmax=df.Total sexe.max())
fcol = lambda x: '#' + bytes(cmap(norm(x), bytes=True)[:3]).hex()
plt.colorbar(plt.cm.ScalarMappable(norm, cmap))
plt.imshow(picture(df.Total sexe.apply(fcol)));

Problème de 4 couleurs
Résolvez le problème de 4 couleurs en utilisant les informations de contiguïté Allons-y.
Peignons tout le Japon avec 4 couleurs pour qu'une préfecture soit une couleur et les préfectures voisines soient différentes. Le problème de l'attribution de différentes couleurs aux objets adjacents de cette manière est appelé le problème de la coloration des sommets. Le problème de coloration des sommets est un problème d'affectation de couleurs aux sommets avec le nombre minimum de couleurs afin que les sommets adjacents sur le graphique aient des couleurs différentes. En tant qu'application de ceci, par exemple, il y a un problème de détermination de la fréquence pour chaque station de base d'un téléphone mobile. (Différentes couleurs → différentes fréquences → vous pouvez parler car les ondes radio n'interfèrent pas)

Résolvez le problème des 4 couleurs
Il a été prouvé mathématiquement que quelle que soit la carte du plan, les zones adjacentes sont différentes et les couleurs sont toujours dans les 4 couleurs. Cependant, il n'est pas évident de les peindre séparément. Ici, résolvons l'optimisation mathématique.
L'optimisation mathématique est utilisée pour résoudre des choses telles que la minimisation des coûts, mais elle peut également résoudre des problèmes avec des contraintes sans fonction objective. Pour le package PuLP utilisé pour l'optimisation mathématique, voir Python dans l'optimisation.
- Il y a trois choses qui doivent être décidées dans le modèle mathématique (1): la représentation des variables, la fonction objective et les conditions de contrainte.
- Représentation variable: Préparez 188 variables qui ne prennent que 0 ou 1 dans 47 préfectures x 4 couleurs. Ces variables sont appelées variables binaires. Les variables sont gérées dans une table dans le package pandas. En utilisant cette table de variables (2), vous pouvez écrire les conditions de contrainte d'une manière facile à comprendre. --Fonction objective: cette fois, nous ne la maximiserons pas, nous ne la définirons donc pas. Dans PuLP, il peut être exécuté sans définir la fonction objectif. --Restriction: Une couleur pour chaque préfecture (3). Les préfectures adjacentes doivent avoir des couleurs différentes (4). --Une fois que vous avez un modèle mathématique, vous pouvez trouver la solution simplement en exécutant le solveur (5). Solver est un logiciel qui résout des modèles mathématiques et est installé lorsque vous installez pulp.
- Le résultat peut être confirmé en appelant la valeur de la variable. Ici, une nouvelle colonne «Val» est ajoutée à la table des variables et le résultat est défini (6). En obtenant la ligne où cette nouvelle colonne est différente de zéro, vous connaissez la couleur à peindre pour la préfecture.

Pour exécuter, vous avez besoin de PuLP et ortoolpy supplémentaires (pip install pulp ortoolpy).
python3
import pandas as pd
from ortoolpy import model_min, addbinvars, addvals
from pulp import lpSum
from japanmap import pref_names, adjacent, pref_map
m = model_min() #Modèle mathématique(1)
df = pd.DataFrame([(i, pref_names[i], j) for i in range(1, 48) for j in range(4)],
columns=['Code', 'Préfecture', 'Couleur'])
addbinvars(df) #Table variable(2)
for i in range(1, 48):
m += lpSum(df[df.Code == i].Var) == 1 #1 préfecture 1 couleur(3)
for j in adjacent(i):
for k in range(4): #Différentes couleurs pour les préfectures voisines(4)
m += lpSum(df.query('Code.isin([@i, @j])et couleur== @k').Var) <= 1
m.solve() #Solution(5)
addvals(df) #Réglage des résultats(6)
Quatre couleurs= ['red', 'blue', 'green', 'yellow']
cols = df[df.Val > 0].Couleur.apply(四Couleur.__getitem__).reset_index(drop=True)
pref_map(range(1, 48), cols=cols, width=2.5)

[^ 1]: numpy est une bibliothèque d'algèbre linéaire telle que le calcul matriciel. En tant que logiciel similaire, MATLAB était souvent utilisé. Comme numpy et MATLAB sont sur la même base, il n'y a pas de grande différence de performances. Cependant, bien que MATLAB soit payant, Python et numpy ont l'avantage d'être gratuits. [^ 2]: Tableau 2 Préfectures, population par sexe et rapport de population / population totale, population japonaise (au 1er octobre 2014) (Excel: 41 Ko)
Recommended Posts