SVM du noyau (make_circles)
■ Présentation
Cette fois, je résumerai l'implémentation d'un simple noyau SVM.
[Lecteurs cibles]
・ Ceux qui veulent apprendre le code simple du noyau SVM
・ Ceux qui ne comprennent pas la théorie mais veulent voir l'implémentation et donner une image, etc.
■ Procédure SVM du noyau
Passez aux 7 étapes suivantes.
- Préparation du module
- Préparation des données
- Visualisation des données
- Créez un modèle
- Diagramme du modèle
- Sortie de la valeur prévue
- Évaluation du modèle
1. Préparation du module
Tout d'abord, importez les modules requis.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import make_circles
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import roc_curve, roc_auc_score
from sklearn.metrics import accuracy_score, f1_score
from sklearn.metrics import confusion_matrix, classification_report
## 2. Préparation des données Cette fois, nous utiliserons l'ensemble de données appelé make_circles fourni par sklearn.
Commencez par récupérer les données, normalisez-les, puis divisez-les.
X , y = make_circles(n_samples=100, factor = 0.5, noise = 0.05)
std = StandardScaler()
X = std.fit_transform(X)
En normalisation, par exemple, lorsqu'il y a des quantités de caractéristiques à 2 et 4 chiffres (variables explicatives), l'influence de ces dernières devient grande. L'échelle est alignée en ajustant pour que la moyenne soit de 0 et la variance de 1 pour toutes les quantités d'entités.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state=123)
print(X.shape)
print(y.shape)
# (100, 2)
# (100,)
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
# (70, 2)
# (70,)
# (30, 2)
# (30,)
3. Visualisation des données
Jetons un coup d'œil au graphique des données avant la binarisation dans le noyau SVM.
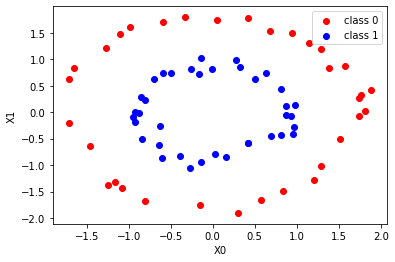
fig, ax = plt.subplots()
ax.scatter(X_train[y_train == 0, 0], X_train[y_train == 0, 1], c = "red", label = 'class 0' )
ax.scatter(X_train[y_train == 1, 0], X_train[y_train == 1, 1], c = "blue", label = 'class 1')
ax.set_xlabel('X0')
ax.set_ylabel('X1')
ax.legend(loc = 'best')
plt.show()
Quantité de caractéristiques correspondant à la classe 0 (y_train == 0) (X0 est l'axe horizontal, X1 est l'axe vertical): Rouge
Quantité de caractéristiques correspondant à la classe 1 (y_train == 1) (X0 est l'axe horizontal, X1 est l'axe vertical): Bleu
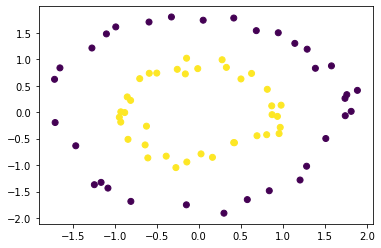
 Ce qui précède est un code un peu fastidieux, mais il peut être concis et court.
Ce qui précède est un code un peu fastidieux, mais il peut être concis et court.
plt.scatter(X_train[:, 0], X_train[:, 1], c = y_train)
plt.show()
4. Créez un modèle
Créez une instance du noyau SVM et entraînez-la.
svc = SVC(kernel = 'rbf', C = 1e3, probability=True)
svc.fit(X_train, y_train)
Cette fois, la séparation linéaire (séparée par une ligne droite) est déjà impossible, donc kernel = 'rbf' est défini dans l'argument.
C est un hyper paramètre que vous ajustez vous-même tout en regardant les valeurs de sortie et les graphiques.
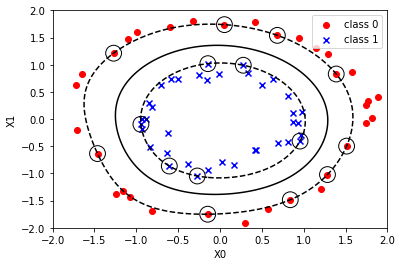
5. Diagramme du modèle
Maintenant que vous avez un modèle du noyau SVM, tracez-le et vérifiez-le.
La première moitié est exactement la même que le code du diagramme de dispersion ci-dessus. Après cela, c'est un peu difficile, mais vous pouvez tracer d'autres données simplement en les collant telles quelles. (Un ajustement fin est nécessaire)
fig, ax = plt.subplots()
ax.scatter(X_train[y_train == 0, 0], X_train[y_train == 0, 1], c='red', marker='o', label='class 0')
ax.scatter(X_train[y_train == 1, 0], X_train[y_train == 1, 1], c='blue', marker='x', label='class 1')
xmin = -2.0
xmax = 2.0
ymin = -2.0
ymax = 2.0
xx, yy = np.meshgrid(np.linspace(xmin, xmax, 100), np.linspace(ymin, ymax, 100))
xy = np.vstack([xx.ravel(), yy.ravel()]).T
p = svc.decision_function(xy).reshape(100, 100)
ax.contour(xx, yy, p, colors='k', levels=[-1, 0, 1], alpha=1, linestyles=['--', '-', '--'])
ax.scatter(svc.support_vectors_[:, 0], svc.support_vectors_[:, 1],
s=250, facecolors='none', edgecolors='black')
ax.set_xlabel('X0')
ax.set_ylabel('X1')
ax.legend(loc = 'best')
plt.show()
6. Sortie de la valeur prévue
Avec le modèle créé, nous donnerons la valeur prédite de la classification.
y_proba = svc.predict_proba(X_test)[: , 1]
y_pred = svc.predict(X_test)
print(y_proba[:5])
print(y_pred[:5])
print(y_test[:5])
# [0.99998279 0.01680679 0.98267058 0.02400808 0.82879465]
# [1 0 1 0 1]
# [1 0 1 0 1]
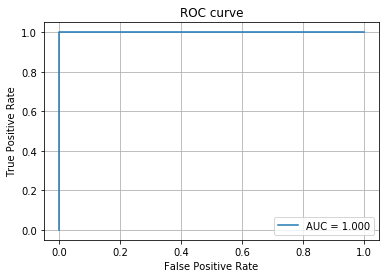
## 7. Évaluation des performances Utilisez la courbe ROC pour trouver la valeur de AUC.
fpr, tpr, thresholds = roc_curve(y_test, y_proba)
auc_score = roc_auc_score(y_test, y_proba)
plt.plot(fpr, tpr, label='AUC = %.3f' % (auc_score))
plt.legend()
plt.title('ROC curve')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.grid(True)
print('accuracy:',accuracy_score(y_test, y_pred))
print('f1_score:',f1_score(y_test, y_pred))
# accuracy: 1.0
# f1_score: 1.0
classes = [1, 0]
cm = confusion_matrix(y_test, y_pred, labels=classes)
cmdf = pd.DataFrame(cm, index=classes, columns=classes)
sns.heatmap(cmdf, annot=True)
print(classification_report(y_test, y_pred))
'''
precision recall f1-score support
0 1.00 1.00 1.00 17
1 1.00 1.00 1.00 13
accuracy 1.00 30
macro avg 1.00 1.00 1.00 30
weighted avg 1.00 1.00 1.00 30
'''

■ Enfin
Sur la base des étapes 1 à 7 ci-dessus, nous avons pu créer un modèle et évaluer les performances du noyau SVM.
Nous espérons qu'il sera utile aux débutants.