expérience svm 1
1. Quel type de contenu
Un ensemble d'images à 1 canal de 3 pixels H x L est donné. Deux feuilles donnent un vecteur de caractéristiques sous forme d'ensemble et une feuille est segmentée et devient une variable objective. L'idée est de reproduire un autre canal segmenté à partir des données de deux canaux.
Comme première idée, ce serait bien si nous pouvions prédire un autre canal à partir des valeurs de pixels de 2 canaux en unités de pixels. Bien sûr, le sujet est de penser à quelque chose dans la matrice de convolution et de lire jusqu'à quelques distances de pixels autour d'elle pour faire une prédiction.
En outre, la variable objectif est classée selon que la valeur de pixel est égale ou supérieure à la valeur spécifiée, et on s'attend à ce que la valeur de pixel soit prédite par régression pour la valeur inférieure à la valeur spécifiée.
Pour l'instant, dans un premier temps, j'ai tenté ce classement.
L'environnement d'exécution de python a été séparé à l'aide de venv, et les bibliothèques nécessaires y ont été installées à l'aide de pip.
python3 -m venv ./P
source P/bin/activate
pip install --upgrade pip
pip install --upgrade scikit-image
2. Saisie et confirmation des données
2.1 Lecture / vérification des données
Deux images à 1 canal sont lues et empilées pour former une image à 2 canaux. Il doit être unidimensionnel et la classe (0 ou 1) doit être comparée à la valeur de pixel «[p1, p2]».
J'ai utilisé scicit-image pour charger l'image. Tout aurait dû être bien cette fois. Lorsque vous chargez l'image, elle devient un tableau numpy «H x W».
comme ça
>>> from skimage import io
>>> img = io.imread('train_images/train_hh_00.jpg')
>>> print(img.shape, img.dtype)
(8098, 11816) uint8
>>> print(img.max(), img.min(), img.mean(), img.std())
255 0 4.339263004581821 4.489037358487263
>>> print(img)
[[1 1 1 ... 6 7 5]
[2 2 2 ... 6 8 8]
[2 2 2 ... 7 8 9]
...
[2 2 1 ... 6 7 8]
[2 3 3 ... 8 9 8]
[2 3 3 ... 8 9 8]]
Après ça
io.imshow(img)
io.show()
Si vous le faites, vous pouvez le vérifier en tant qu'image
img *= 20
Si vous faites quelque chose comme ça, vous pouvez augmenter la valeur du pixel.
2.2 Confirmation de la distribution des valeurs de pixels des images HH, HV
Je vais classer avec ceci, donc je vais le vérifier visuellement correctement.
Créez un tableau de tableaux numpy des images d'annotation lues HH, HV et diffusez-les en 3D avec matplotlib. Quand je l'essaye, c'est aussi lent que l'enfer.
Je ne peux pas tout tracer beaucoup, donc je vais essayer de ne tracer qu'une partie en la rendant unidimensionnelle comme suit.
import matplotlib.pyplot as plt
def reshape_them(img):
rimg = list(map(lambda i: i.reshape([1, -1]), img))
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(rimg[0][0][75500000:75510000], rimg[1][0][75500000:75510000], rimg[2][0][75500000:75510000], marker='o')
ax.set_xlabel('X Label')
ax.set_ylabel('Y Label')
ax.set_zlabel('Z Label')
plt.show()
Les résultats suivants ont été obtenus.
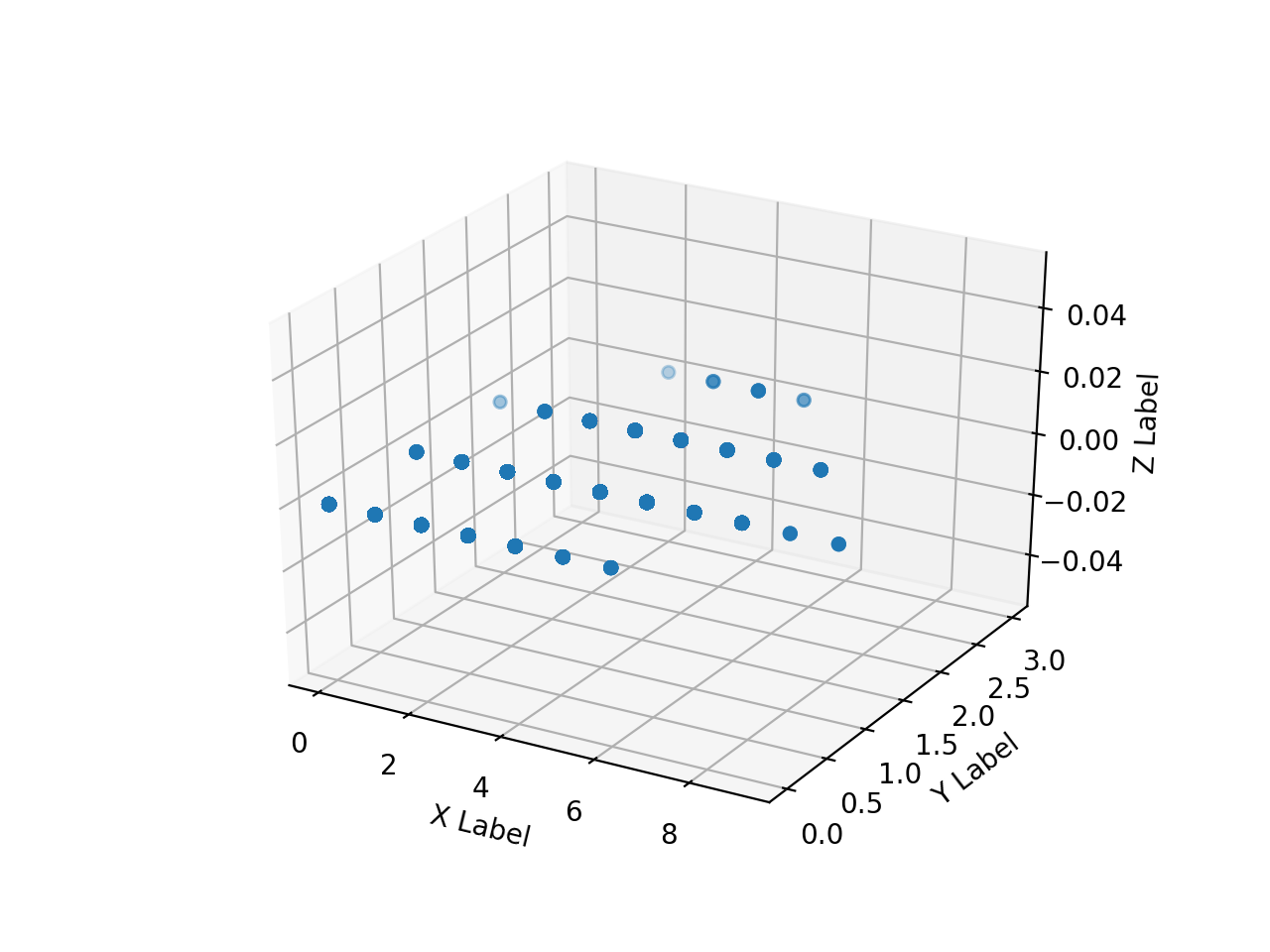
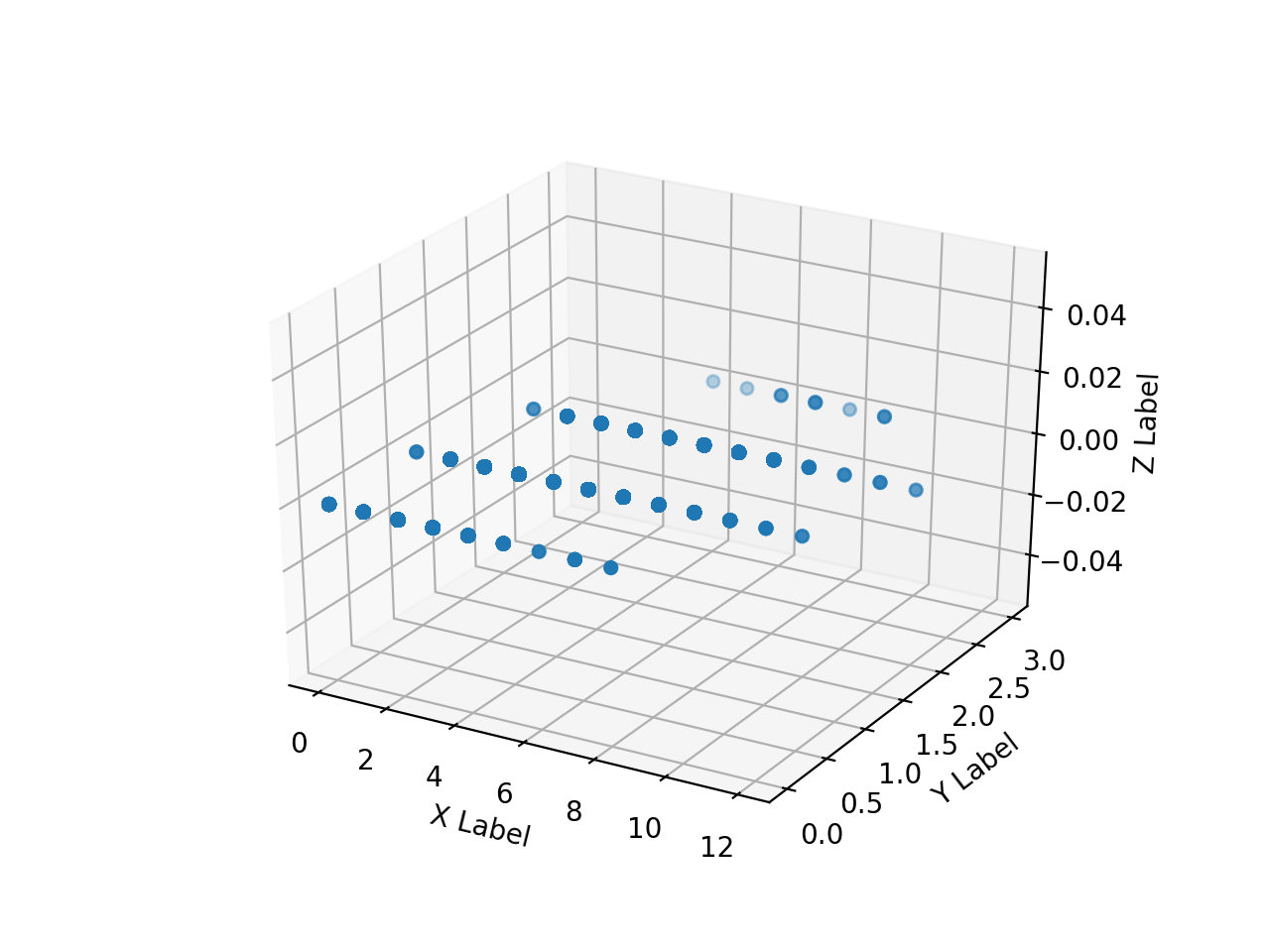
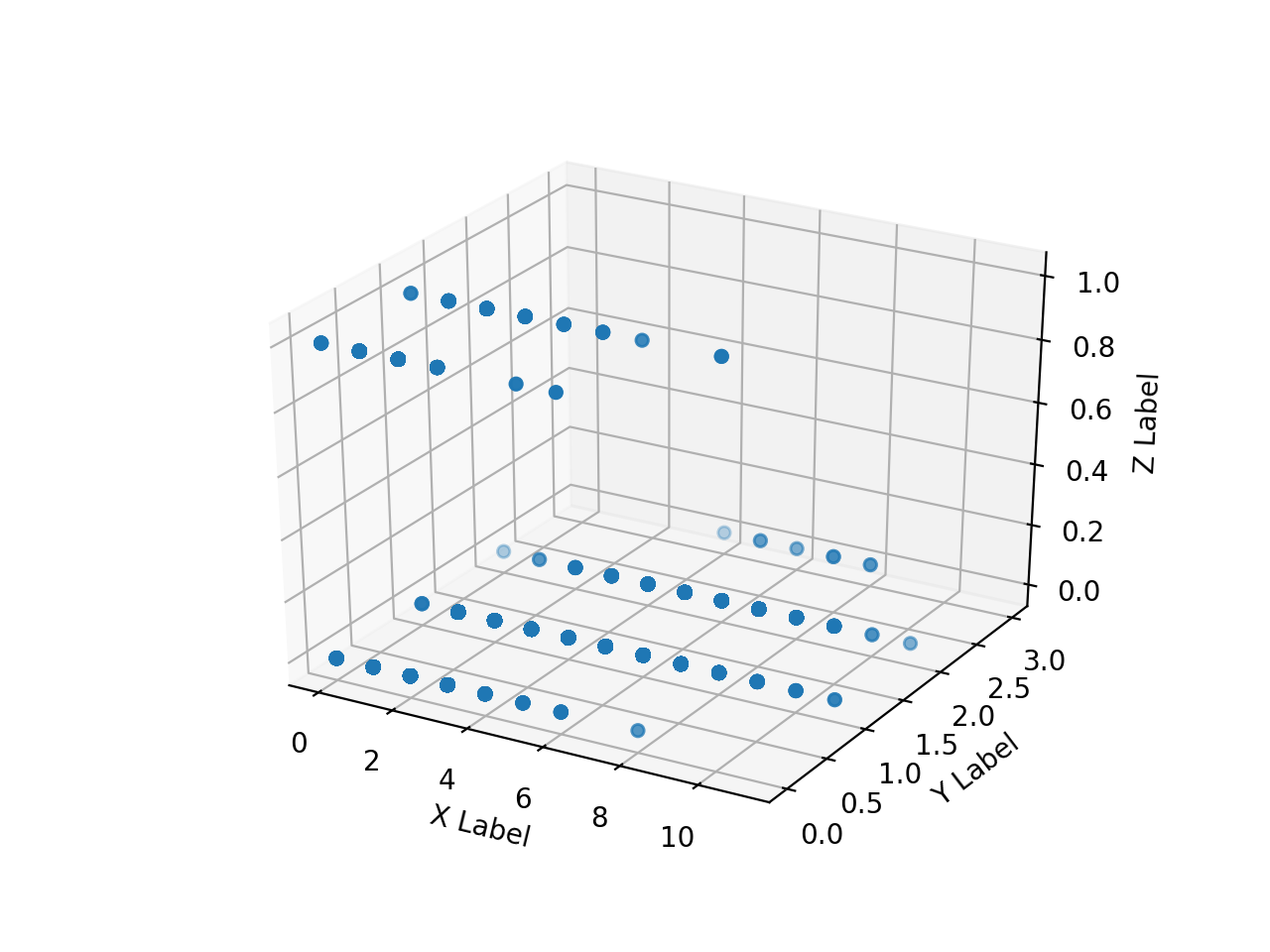
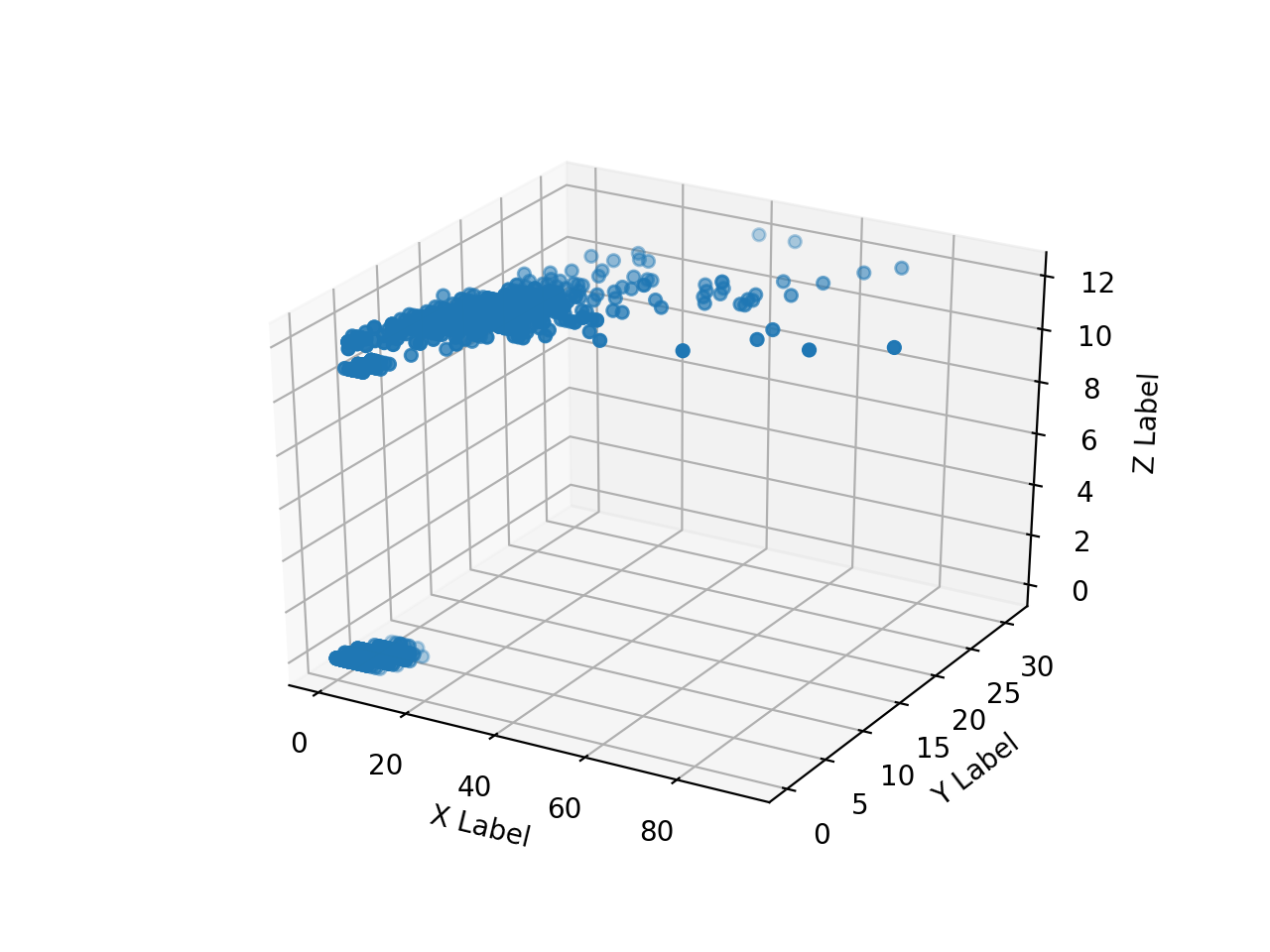
La plage de tableau de ʻax.scatter () ʻis[0: 10000],[500000: 510000],[5500000: 5510000],[755000000: 75510000], respectivement.
annotation En raison de la commodité de l'image, la zone où la valeur de pixel (Z) des données de l'enseignant prend une certaine valeur est considérablement biaisée vers l'arrière, On voit que les mêmes valeurs HH et HV sont divisées en 2 classes. Il est donc imprudent de ne classer que HH et HV en 2 classes, mais pour l'instant, voyons ce que nous pouvons obtenir avec cela.
2.3 Créer une image à 3 canaux
Les images HH, HV à 1 canal sont empilées pour créer des images à 3 canaux.
J'ai pensé qu'il serait bon d'empiler le tableau numpy mentionné ci-dessus, mais l'image multicanal n'est pas une pile de tableaux 2D pour le nombre de canaux. Un tableau 1D avec la longueur du nombre de canaux a été aligné dans XY.
Pour le faire, créez d'abord un tableau de 3 tableaux 2D disposés côte à côte (imgx), puis utilisez transpose () pour changer l '«axe» afin de rendre la direction du canal la plus interne (imgy).
imgx = np.array([imgs[0], imgs[1], imgs[1]*0])
imgy = imgx.transpose(1,2,0)
imgz = imgy * 16
io.imshow(imgz)
io.show()
Puisque 3 canaux sont requis, \ * 0 est utilisé pour créer et inclure les 0 plans. De plus, comme la valeur du pixel est trop petite, elle est corrigée par \ * 16 pour pouvoir être distinguée (imgz).
Comme c'est un gros problème, je vais essayer de l'afficher côte à côte avec l'image d'origine.
im21 = cv2.hconcat([gray2rgb(imgs[0]*16), gray2rgb(imgs[1]*16)])
im22 = cv2.hconcat([gray2rgb(imgs[2]*16), imgz])
im2 = cv2.vconcat([im21, im22])
io.imshow(im2)
io.show()
Gray2rgb () est utilisé pour faire correspondre le nombre de canaux lors de la jonction.
3. Classification --SVM
3.1 SVM
Revenons à l'histoire. Après avoir lu une image à 1 canal H x L, remodelez-la en 1 x H \ * W. Si cela est transposé par vstacking 2 images, les valeurs de pixel de 2 images sont arrangées pour chaque pixel, et s'il est également défini avec l'image d'annotation remodelée à 1 x H \ * W, il semble qu'un classificateur puisse être fait avec SVM.
import sklearn.svm
import joblib
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import time
def reshape_and_calc(img):
rimg = list(map(lambda i: i.reshape([1, -1]), img))
print(rimg[0].shape, rimg[0].dtype, rimg[0].ndim)
train = np.vstack((rimg[0], rimg[1])).transpose()
label = rimg[2][0]
print(train.shape, label.shape)
train = train / 16.0 # [0..255]À[0..1)Équivaut à 16 fois après
label = np.where(label>10, 1, 0)
print(train)
print(label)
De façon effrayante, les données à manger par l'entraînement sont une matrice N x 2, mais l'étiquette (variable objective) mangée par svm de scikit-learn est un vecteur 1 x N (donc transpose () dans le calcul de train". Est attaché).
Pourquoi est-ce différent verticalement et horizontalement?
Après cela, alimentez entièrement l'objet classificateur SVM comme indiqué ci-dessous, et enfin sérialisez-vous avec joblib.
svm = sklearn.svm.SVC(kernel='rbf', random_state=0, gamma=0.10, C=10.0)
svm.fit(train, label)
joblib.dump(svm, 'svmmodel.sav')
Cependant, ce svm.fit () prend beaucoup de temps et ne montre aucun progrès, donc il reste bloqué quelque part s'il calcule vraiment Je ne peux pas dire si c'est inutile, peu importe combien de temps j'attends.
Donc, je me demande si c'est correct de le faire, mais je vais essayer de découper les données petit à petit et de les former en séquence. Le code ci-dessous a fonctionné.
train_X, test_X, train_y, test_y = train_test_split(train, label, train_size=0.8, random_state=1999)
#print(train_X, test_X, train_y, test_y)
print('data splitted', train_X.shape, test_X.shape, train_y.shape, test_y.shape)
M = len(train_X)
L=65536
offset=0
start_time = time.time()
while offset < M:
print('fitting', offset, '/', M, time.time() - start_time, "sec")
L2 = min(offset+L, M)
svm.fit(train_X[offset:L2], train_y[offset:L2])
offset += L
print('done')
y_pred = svm.predict(test_X)
print('Misclassified samples: %d' % (test_y != y_pred).sum())
print('Accuracy: %.2f' % accuracy_score(test_y, y_pred))
Un tel journal demeure.
fitting 76349440 / 76548774 706.0181198120117 sec
fitting 76414976 / 76548774 706.6317739486694 sec
fitting 76480512 / 76548774 707.2629809379578 sec
fitting 76546048 / 76548774 707.8376820087433 sec
done
Misclassified samples: 54996
Accuracy: 1.00
Il a géré 76 548 774 points en 707 secondes.
Je suis soudainement devenu accro à cela lorsque la vérification a été effectuée dans un groupe de fichiers différent en premier lieu, et je ne voulais pas train_test_split parce que je voulais mettre toutes les données dans la formation.
3.2 Classification SVM - Équilibre du positif et du négatif
train_test_split () coupe un ensemble pour l'entraînement et un ensemble pour la vérification pour l'évaluation des résultats d'apprentissage à partir d'un ensemble de données d'apprentissage et d'étiquettes. À propos, il semble que la lecture aléatoire sera ajoutée au hasard.
Cependant, ici, c'est un gaspillage de tourner une pièce pour l'évaluation, et puisque l'évaluation est faite dans un autre fichier, supposons que vous vouliez utiliser le fichier entier pour les données d'entraînement et n'utilisez pas train_test_split ().
train_X, test_X, train_y, test_y = train_test_split(train, label, train_size=0.8, random_state=1999)
Si vous insérez simplement la partie de train, label dans train_X, train_y, elle sera rejetée car les données d'étiquette de hâte ne contiennent que des exemples corrects.
ValueError: The number of classes has to be greater than one; got 1 class
À bien y penser, la source de ces données d'enseignant était une seule image avec des valeurs de pixels, et la seule partie différente de la classe était la petite zone au bas de l'image. Si vous pincez la valeur de pixel par le haut, une seule classe sera incluse si vous n'avancez pas considérablement.
La méthode d'amélioration consiste à extraire le même nombre de pixels pour les deux classes = 0 et = 1, à les combiner, à les mélanger aléatoirement au cas où et à les traiter dans l'ordre du haut, 65536 à la fois. Afin d'extraire le même nombre des deux classes, plus les classes nécessitent un mélange aléatoire et sont combinées et mélangées à nouveau.
Quand je l'ai essayé, c'était extrêmement lent. On dit que c'est rapide parce que c'est engourdi, mais c'est naturellement lent si vous faites cela.
Dans un fichier, le nombre de pixels était de 95 685 968, dont 4 811 822 étaient positifs et négatifs, donc 9 623 644 points ont été extraits. Il y a deux valeurs de HH et VV par point, et ce sera une valeur à virgule flottante de 64 bits lorsqu'elle est normalisée avec [0, 1), donc 96 millions de points x 2 x 8 octets Les données d'entrée ont été créées en extrayant 153,6M de 1,54G.
def reshape_them(imgs):
rimg = list(map(lambda i: i.reshape([1, -1]), imgs))
train = np.vstack((rimg[0], rimg[1])).transpose()
teach = rimg[2][0]
print(train.shape, teach.shape)
train = train / 256.0
teach = np.where(teach>10, 1, 0)
return [train, teach]
def balance(data):
train_x = data[0]
train_y = data[1]
mask = train_y == 1
train_x_pos = train_x[mask]
train_x_neg = train_x[np.logical_not(mask)]
sample = min(len(train_x_pos), len(train_x_neg))
train_y_balance = [1 for i in range(sample)] + [0 for i in range(sample)]
print('shrink length to', len(train_y_balance))
if len(train_x_pos) < len(train_x_neg):
np.random.shuffle(train_x_neg)
else:
np.random.shuffle(train_x_pos)
train_x_balance = np.concatenate([train_x_pos[:sample], train_x_neg[:sample]])
print("shuffled and concatenated", train_x_balance.shape)
Y = np.hstack([train_x_balance, np.array(train_y_balance).reshape([len(train_y_balance),1])])
#print(Y.shape)
np.random.shuffle(Y)
print(Y[:,0:2], Y[:,2].transpose())
return([Y[:,0:2], Y[:,2].transpose()])
def run(train_X, train_Y, model):
print(train_X.shape, train_Y.shape)
M = len(train_X)
L=65536
offset=0
start_time = time.time()
while offset < M:
print('fitting', offset, '/', offset / M, time.time() - start_time, "sec")
L2 = min(offset+L, M)
#print(train_X[offset:L2], train_Y[offset:L2])
model.fit(train_X[offset:L2], train_Y[offset:L2])
offset += L
print('done')
(X, Y) = reshape_them(imgs)
(X, Y) = balance([X, Y])
svm = sklearn.svm.SVC(kernel='rbf', random_state=0, gamma=0.10, C=10.0)
run(X, Y, svm)
3.3 SVM-Après l'apprentissage
L'apprentissage lui-même a été effectué sur AWS. Lorsque l'apprentissage est terminé
joblib.dump(svm, modelfile)
L'objet SVM est sérialisé comme Homura. Apportez ceci à votre PC local Pour le fichier à portée de main
with open(modelfile, mode="rb") as f:
svm = joblib.load(f)
M = len(X)
L=65536
offset=0
start_time = time.time()
y_pred = []
while offset < M:
print('prediciting', offset, '/', offset / M, time.time() - start_time, "sec")
L2 = min(offset+L, M)
_Y = svm.predict(X[offset:L2])
y_pred.append(_Y)
#print('Misclassified samples: %d' % (Y[offset:L2] != _Y).sum())
#print('Accuracy: %.2f' % accuracy_score(Y[offset:L2], _Y))
offset += L
predicted = np.concatenate(y_pred).reshape(imgs[2].shape)
io.imshow(predicted)
io.show()
im2 = cv2.hconcat([predicted*10.0, imgs[2]*1.0])
io.imshow(im2)
io.show()
Si vous sortez la valeur prédite et la combinez et la renvoyez à l'image, il semble que vous puissiez juger à quoi elle ressemble en tant qu'image.
Ainsi, lorsque je l'essaye, les noms de module sont légèrement différents entre Linux dans l'environnement AWS et python dans le MacOS local, comme indiqué ci-dessous, et je ne peux pas le lire.
File "/usr/local/Cellar/python/3.7.5/Frameworks/Python.framework/Versions/3.7/lib/python3.7/pickle.py", line 1426, in find_class
__import__(module, level=0)
ModuleNotFoundError: No module named 'sklearn.svm._classes'
Certainement, si vous regardez le début du fichier de sérialisation, si vous le faites avec AWS
00000000 80 03 63 73 6b 6c 65 61 72 6e 2e 73 76 6d 2e 5f |..csklearn.svm._|
00000010 63 6c 61 73 73 65 73 0a 53 56 43 0a 71 00 29 81 |classes.SVC.q.).|
00000020 71 01 7d 71 02 28 58 17 00 00 00 64 65 63 69 73 |q.}q.(X....decis|
00000030 69 6f 6e 5f 66 75 6e 63 74 69 6f 6e 5f 73 68 61 |ion_function_sha|
00000040 70 65 71 03 58 03 00 00 00 6f 76 72 71 04 58 0a |peq.X....ovrq.X.|
Il y a Ansco, mais quand j'essaye de le cracher sur mac
00000000 80 03 63 73 6b 6c 65 61 72 6e 2e 73 76 6d 2e 63 |..csklearn.svm.c|
00000010 6c 61 73 73 65 73 0a 53 56 43 0a 71 00 29 81 71 |lasses.SVC.q.).q|
00000020 01 7d 71 02 28 58 17 00 00 00 64 65 63 69 73 69 |.}q.(X....decisi|
00000030 6f 6e 5f 66 75 6e 63 74 69 6f 6e 5f 73 68 61 70 |on_function_shap|
00000040 65 71 03 58 03 00 00 00 6f 76 72 71 04 58 06 00 |eq.X....ovrq.X..|
Il n'y a pas d'Ansco comme. Eh bien, il y a un flou dans un tel endroit.
Je ne pouvais pas m'en empêcher, alors j'ai essayé de le prédire sur AWS, mais contrairement à l'apprentissage, ce n'est qu'un calcul de chemin, mais c'est mortellement lent. Comme mentionné ci-dessus, il n'y a pas d'extraction pour rendre les nombres positifs et négatifs, donc il y a beaucoup de points de calcul, mais c'est encore lent.
ex73: prediciting 65929216 / 0.9993775530341474 9615.45419716835 sec
ex75: prediciting 70975488 / 0.9991167432331827 10432.654431581497 sec
C'était un cours de 2,8 heures par dossier.
 Prédiction à gauche, étiquette à droite
Prédiction à gauche, étiquette à droite