Tutoriel Pepper (7): Reconnaissance d'image
Contenu de ce tutoriel
Dans ce tutoriel, nous expliquerons les spécifications et le comportement de la reconnaissance d'image par Pepper à travers des exemples.
- Spécifications relatives à l'image
- Comment vérifier l'image avec Choregraphe
- Traitement facial de base
- Faire face à l'apprentissage et à la discrimination
- Apprentissage de l'image et discrimination
** Pour la reconnaissance d'image, il n'y a pas de méthode de confirmation d'opération pour les robots virtuels, et une machine Pepper réelle est requise. ** Je voudrais que vous expérimentiez la machine à poivre à Aldebaran Atelier Akihabara. (URL de réservation: http://pepper.doorkeeper.jp/events)
Diverses spécifications de capteur
Les spécifications relatives au traitement d'image de Pepper sont les suivantes.
- Caméra 2D x 2 (front ** [A] **, bouche ** [B] **) ... Sortie 1920 x 1080, 15fps
- Caméra 3D (irradiation infrarouge: ** [C] **, détection infrarouge: ** [D] **) ... Capteur ASUS Xtion 3D, sortie 320 × 240, 20fps

Pepper utilise ces caméras pour reconnaître les personnes et les objets.
Comment vérifier l'image avec Choregraphe
Vous pouvez vérifier les informations de l'image prise par la caméra de Pepper dans Choregraphe.
Confirmation par le panneau du moniteur vidéo
Utilisez le panneau du moniteur vidéo pour les opérations liées aux images Pepper. Le panneau du moniteur vidéo est généralement situé dans la même zone que la bibliothèque de pause et peut être affiché en sélectionnant l'onglet Moniteur vidéo. Si vous ne le trouvez pas, sélectionnez [Moniteur vidéo] dans le menu [Affichage].

Le panneau du moniteur vidéo offre la possibilité de visualiser des images de la caméra de Pepper, ainsi que la possibilité de gérer la base de données de reconnaissance visuelle décrite ci-dessous.
- Image de la caméra ... Vous pouvez vérifier le contenu de la caméra de Pepper
- Bouton Lecture / Pause ... Lecture pour voir l'image actuelle de la caméra en temps réel. Vous pouvez arrêter cela avec une pause
- Bouton de mode d'apprentissage ... Passez en mode d'apprentissage d'image. Comment utiliser est expliqué dans le tutoriel d'apprentissage d'image
- Bouton Importer ... Importer la base de données de reconnaissance visuelle d'un fichier local dans Choregraphe
- Bouton Exporter ... Exporte la base de données de reconnaissance visuelle de Choregraphe vers un fichier local
- Bouton Effacer ... Effacer la base de données de reconnaissance visuelle actuelle
- Bouton Soumettre ... Soumet la base de données de reconnaissance visuelle contenue dans le Chorégraphe actuel à Pepper
Confirmation par le moniteur
Vous pouvez également utiliser l'application Monitor installée avec Choregraphe. L'application Monitor démarre comme suit.
-
Lancez l'application ** Monitor ** installée avec Choregraphe.
-
Cliquez sur ** Caméra ** dans le menu de lancement de l'application Moniteur
-
Une boîte de dialogue demandant le Pepper auquel se connecter s'ouvrira, alors sélectionnez le Pepper que vous utilisez.

-
La fenêtre Moniteur s'ouvre. Cliquez sur le bouton ** Lecture **.

-
Vous pouvez vérifier l'image prise par la caméra de Pepper
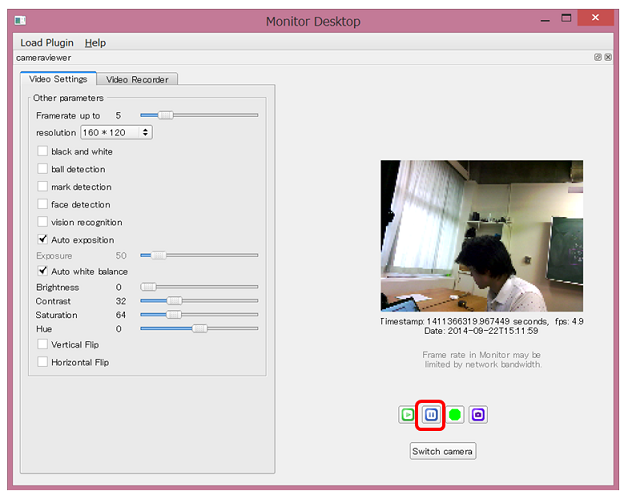 Vous pouvez arrêter la lecture avec le ** bouton Pause **
Vous pouvez arrêter la lecture avec le ** bouton Pause ** -
En plus des images, vous pouvez vérifier les informations relatives à la reconnaissance d'image. En cochant la ** détection de visage [A] **, vous pouvez vérifier l'état de la ** reconnaissance de visage de Pepper [B] **.

-
Si vous souhaitez vérifier le contenu de la caméra 3D, ** Sélectionnez [3d sensor monitor] dans le menu [Load Plugin] **

-
Vous pouvez vérifier la carte de profondeur en cliquant sur le ** bouton de lecture ** de la même manière qu'une caméra 2D.
 Vous pouvez arrêter la lecture avec le ** bouton Pause **
Vous pouvez arrêter la lecture avec le ** bouton Pause **
Avec cette application Monitor, vous pouvez vérifier en détail le contenu de l'image reconnue par Pepper.
Reconnaissance faciale de base
Reconnaissance de visage
En utilisant la boîte de détection de visage fournie en tant que boîte standard, vous pouvez obtenir le nombre de visages actuellement reconnus par Pepper. Ici, je vais essayer de combiner les zones Say Text que j'ai utilisées plusieurs fois pour faire ** parler le nombre de visages que Pepper reconnaît **.
Essayer de faire
- Préparation de la boîte à utiliser
- bibliothèque de boîtes standard
- Vision> Détection de visage ... Effectue la détection de visage et affiche le nombre de visages détectés.
- bibliothèque de boîtes avancées ... Sélectionnez l'onglet avancé de la bibliothèque de boîtes
- Audio> Voix> Dire le texte ... Prononcez la chaîne saisie
- Connectez les boîtes

En connectant le numberOfFaces (orange, type: number) de la zone de détection de visage au onStart (bleu, type: string) de la zone Say Text, vous pouvez faire en sorte que Pepper prononce la valeur de numberOfFaces sortie par la boîte de détection de visage. Je vais.

L'application est maintenant terminée. Lorsqu'un visage est reconnu, la boîte de détection de visage génère numberOfFaces et Pepper parle en réponse à cette sortie.
Contrôle de fonctionnement
Connectez-vous à Pepper et essayez de jouer. Lorsque vous montrez votre visage à Pepper, Pepper parle du nombre de visages en vue, comme "Ichi" et "Ni".
Dans Robot View, vous pouvez également connaître la position du visage reconnu par Pepper.

Par exemple, comme illustré ci-dessus, lorsque Pepper reconnaît un visage, une marque de visage apparaît dans la vue du robot. Cela montre la position du visage dont Pepper est conscient.
(Supplément) Personnalisation de la zone Say Text
Cet exemple est aussi simple que de dire des nombres tels que "ichi" et "ni". Il suffit de voir le mouvement de la boîte de détection de visage, mais c'est une application qui a du mal à dire ce que vous faites.
Ici, à titre d'exemple, si le nombre de visages détectés est de 1, modifions-le pour qu'il dise "Il y a une personne devant moi" **.
La zone Say Text est une boîte Python qui utilise l'API parlante ** ALTextToSpeech API **. Si vous pouvez manipuler la chaîne passée de la zone Dire le texte à ALTextToSpeech, vous pouvez modifier ce que vous dites.
Cette fois, j'essaierai d'utiliser la chaîne de caractères dans la zone Dire le texte. Double-cliquer sur la zone Say Text ouvrira le code Python, recherchant la fonction ʻonInput_onStart (self, p) `dans ce code. Vous pouvez voir qu'il existe une ligne comme celle-ci:
sentence = "\RSPD="+ str( self.getParameter("Speed (%)") ) + "\ "
sentence += "\VCT="+ str( self.getParameter("Voice shaping (%)") ) + "\ "
sentence += str(p)
sentence += "\RST\ "
id = self.tts.post.say(str(sentence))
self.ids.append(id)
self.tts.wait(id, 0)
p contient la valeur entrée dans la zone Say Text et construit la chaîne à donner à l'API ALTextToSpeech à phrase + = str (p).
Par conséquent, si vous changez cette partie en phrase + =" il y a une personne devant moi "+ str (p) +" il y a une personne " etc., au lieu de "une", "il y a une personne devant moi" "(" Une personne "parle" une personne ").
Suivi du visage
Similaire à la voix permet à Pepper de suivre la direction du visage. Dans l'exemple audio, nous ne déplaçions que l'angle du cou, mais ici nous allons utiliser la case Face Tracker pour ** nous déplacer dans la direction du visage **.
Essayer de faire
- Préparation des boîtes à utiliser (bibliothèque de boîtes standard)
- Trackers> Face Tracker ... Suivez votre visage
- Connectez les boîtes

Vous pouvez suivre votre visage simplement en démarrant la boîte de suivi de visage.
- Définissez les paramètres
Réglez la variable Mode du paramètre Face Tracker sur ** Move **.

L'application est maintenant terminée. La boîte Face Tracker a une grande fonctionnalité qui "identifie le visage et se déplace dans cette direction", donc le flux peut être aussi simple que cela.
Contrôle de fonctionnement
Connectez-vous à Pepper et essayez de jouer. Lorsqu'un humain est à proximité, il essaie de suivre le visage reconnu en pliant son cou, mais à mesure qu'il s'éloigne progressivement avec le visage tourné vers le visage, Pepper se déplace vers le visage. Si vous êtes connecté à Pepper par fil, veillez à ne pas le déplacer dans une direction inattendue.
Avant de m'y habituer, j'ai un peu peur d'être pourchassé en regardant Pepper, mais finalement je peux penser que mes yeux supérieurs sont mignons ...!
Faire face à l'apprentissage et à la discrimination
Dans l'exemple précédent, j'ai simplement compté et chassé les «visages». Voyons ici comment apprendre à se souvenir de qui est le visage.
Apprendre le visage
Vous pouvez laisser Pepper apprendre avec un visage en utilisant la zone Apprendre le visage. Ici, nous allons essayer ** de mémoriser le visage que Pepper a vu 5 secondes après la lecture avec le nom "Taro" **.
Essayer de faire
- Préparation des boîtes à utiliser (bibliothèque de boîtes standard)
- Edition de données> Edition de texte ... Sortie de n'importe quelle chaîne de caractères
- Vision> Apprendre le visage ... Mémorisez la correspondance entre les visages et les noms
-
Connectez les boîtes
-
Définissez la chaîne de caractères

Avec Learn Face, vous pouvez maintenant implémenter une application dans laquelle le visage de Pepper est appris comme un "taro".
Contrôle de fonctionnement
Après vous être connecté à Pepper et avoir joué, assurez-vous que votre visage est à portée de la caméra de Pepper. Cinq secondes après la lecture, les yeux de Pepper deviendront verts ** si le visage peut être appris normalement, et ** rouges ** s'il échoue.
Vous pouvez supprimer les données de visage apprises en exécutant ** Désapprendre tous les visages **.
####
[Référence] Learn Face Contenu Vous pouvez voir comment "Attendre 5 secondes" et "Les yeux deviennent verts" dans la zone Apprendre le visage sont réalisés en double-cliquant sur la case Apprendre le visage.
Vous pouvez voir que la zone Learn Face est une boîte de diagramme de flux et est représentée comme une collection de boîtes plus simples telles que Attendre. En regardant à l'intérieur de la boîte de cette manière, vous pouvez l'utiliser comme référence lorsque vous réfléchissez à la façon d'utiliser la boîte.
Faire face à la discrimination
Après avoir appris le visage, sur la base des données d'entraînement, ** déterminez qui est le visage que Pepper reconnaît actuellement et laissez-le prononcer le nom **.
Essayer de faire
- Préparation de la boîte à utiliser
- bibliothèque de boîtes standard
- Vision> Reco Visage ... Identifier les visages
- bibliothèque de boîtes avancées
- Audio> Voix> Dire le texte ... Prononcez la chaîne de caractères saisie dans la boîte précédente
- Connectez les boîtes
 C'est très simple, cela donne juste la sortie (bleu, chaîne) de la boîte de reconnaissance de visage à la boîte de texte.
C'est très simple, cela donne juste la sortie (bleu, chaîne) de la boîte de reconnaissance de visage à la boîte de texte.
Contrôle de fonctionnement
Connectez-vous à Pepper et jouez. Si vous montrez votre visage à Pepper et prononcez le nom que vous avez appris, tel que "Taro", vous réussirez. Apprenez Face multiple faces pour voir si Pepper peut être identifié correctement.
Apprentissage d'image et discrimination
Chorégraphe a une fonction pour faire fonctionner la base de données de reconnaissance visuelle, qui peut être utilisée pour faire apprendre à Pepper autre chose que le visage humain.
Images d'apprentissage
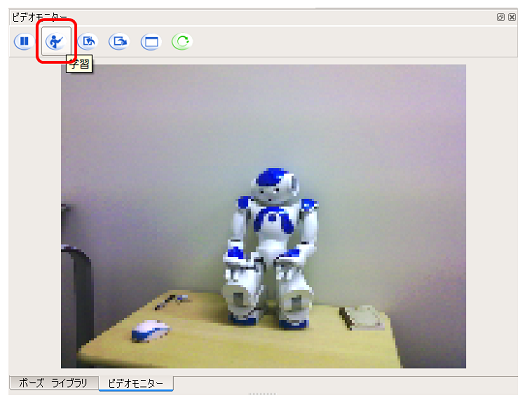
Utilisez le panneau du moniteur vidéo de Choregraphe pour apprendre les images. Ici, apprenons ** NAO ** dans l'atelier.
-
Connectez-vous à Pepper, avec l'objet sur le moniteur vidéo, cliquez sur le bouton ** Apprendre **
-
Cliquez avec le bouton gauche de la souris sur ** Limite d'objet **

-
Créez en cliquant avec le bouton gauche sur le sommet comme si vous dessiniez une ligne droite

-
Définissez les sommets pour entourer l'objet, puis cliquez avec le bouton gauche sur le point de départ.

-
La zone de l'objet est identifiée et une boîte de dialogue vous invitant à saisir des informations s'ouvre. Saisissez les informations appropriées.

Entrez NAO ici.

- Cliquez sur le bouton ** Envoyer la base de données de reconnaissance visuelle actuelle au robot ** pour envoyer les informations enregistrées dans la base de données de reconnaissance visuelle de Choregraphe à Pepper.

Vous avez maintenant associé Pepper avec la chaîne "NAO" aux caractéristiques d'image de NAO.
Discrimination d'image
Comme pour la discrimination faciale, nous essaierons de ** parler de ce que vous regardez en nous basant sur le contenu de la base de données de reconnaissance visuelle formée **.
Essayer de faire
La Vision Reco. Box vous permet de faire correspondre ce que Pepper recherche actuellement avec la base de données de reconnaissance visuelle pour obtenir le nom de l'objet.
- Préparation de la boîte à utiliser
- bibliothèque de boîtes standard
- Vision> Vision Reco. ... Correspond à la base de données de reconnaissance visuelle
- bibliothèque de boîtes avancées
- Audio> Voix> Dire le texte ... Prononcez la chaîne de caractères saisie dans la boîte précédente
-
Connectez les boîtes (1)
 Tout d'abord, donnez à la zone Say Text la sortie onPictureLabel (bleu, chaîne) de Vision Reco. Box, similaire à la discrimination de visage.
Tout d'abord, donnez à la zone Say Text la sortie onPictureLabel (bleu, chaîne) de Vision Reco. Box, similaire à la discrimination de visage. -
Connectez les boîtes (2) Dans cet exemple, la ** sortie onPictureLabel ** et ** l'entrée onStop ** de la Vision Reco. Box sont connectées afin d'arrêter le fonctionnement de la Vision Reco. Box tout en parlant après la reconnaissance (la raison sera décrite plus loin).
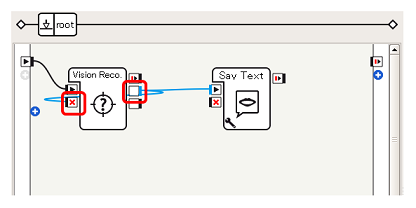 Après avoir parlé, connectez la ** sortie onStopped ** de la zone Say Text à ** l'entrée onStart ** de la Vision Reco. Box pour reprendre le fonctionnement de la Vision Reco. Box.
Après avoir parlé, connectez la ** sortie onStopped ** de la zone Say Text à ** l'entrée onStart ** de la Vision Reco. Box pour reprendre le fonctionnement de la Vision Reco. Box.

####
Par conséquent, si seule la connexion en 2. est utilisée, non seulement vous continuerez à parler "NAO", "NAO" et "NAO" tout en montrant NAO, mais cela continuera pendant un certain temps même si vous supprimez NAO de la vue de Pepper. Ce sera. Pour éviter de tels problèmes, une fois que la Vision Reco. Box a produit le résultat de la reconnaissance, la Vision Reco. Box est temporairement arrêtée, et une fois que la zone Say Text est terminée, l'opération Vision Reco. ..
Contrôle de fonctionnement
Essayez de vous connecter à Pepper et de lire l'application que vous avez créée. Parler de "NAO" lors de la présentation de NAO est un succès.
Comme vous pouvez le voir, Pepper a différentes fonctions pour la reconnaissance d'image. En contrôlant Pepper avec les informations obtenues des yeux, la plage de contrôle peut être élargie. Veuillez essayer.
Recommended Posts