Scraping de sites Web à l'aide de JavaScript en Python
Aperçu
J'ai utilisé Python pour gratter un site qui crée un DOM avec JavaScript, alors notez la procédure.
En gros, j'ai fait une combinaison de Scrapy et Selenium.
Scrapy
Scrapy est un framework pour implémenter des robots d'exploration.
Implémentez le robot en tant que classe qui satisfait l'interface déterminée par le framework, comme le robot en tant que sous-classe de * Spider *, les informations récupérées en tant que sous-classe de * Item * et le traitement des informations récupérées en tant que sous-classe de * Pipeline *.
Une commande appelée * scrapy * est fournie qui vous permet de voir une liste de vos robots d'exploration et de les lancer.
Selenium
Selenium est un outil (est-ce que ça va?) Pour contrôler le navigateur par programmation. Il peut être utilisé dans divers langages, y compris Python. Il apparaît souvent dans le contexte des tests automatisés des sites Web / applications. Vous pouvez l'utiliser pour exécuter JavaScript et extraire des sources HTML, y compris un DOM généré dynamiquement.
À l'origine, il semblait contrôler le navigateur via JavaScript, mais maintenant il envoie un message directement au navigateur pour contrôler le navigateur.
Lorsque je l'ai essayé dans mon environnement (OSX), je ne pouvais pas l'utiliser dans Safari et Chrome sans installer quelque chose comme une extension. Vous pouvez l'utiliser tel quel avec Firefox. Si vous incluez PhantomJS, vous pouvez gratter sans fenêtre, afin de pouvoir l'utiliser sur le serveur.
Pourquoi utiliser Scrapy
Vous pouvez gratter avec du sélénium seul sans utiliser Scrapy,
- Scrapage de plusieurs pages en parallèle (multi-thread? Process?), ―― Combien de pages ont été explorées, combien de fois l'erreur s'est produite et le journal est bien résumé.
- évite la duplication des pages explorées,
- Fournit diverses options de réglage telles que l'intervalle d'analyse, --Combinez CSS et XPath pour sortir des informations du DOM (la combinaison est assez pratique!),
- Les résultats de l'exploration peuvent être crachés en JSON ou XML,
- Vous pouvez écrire un robot avec une belle conception de programme (je pense que c'est mieux que de le concevoir vous-même),
Le mérite d'utiliser Scrapy qui me vient à l'esprit est le suivant.
Au début, étudier le framework était un problème, j'ai donc implémenté le robot uniquement avec Selenium et PyQuery, mais si j'écrivais des journaux et la gestion des erreurs , La sensation de réinvention de la roue est devenue plus forte et je me suis arrêté.
Avant l'implémentation, j'ai lu Scrapy Documentation depuis le début jusqu'à la page Paramètres, et autour de * Présentation de l'architecture * et * Downloader Middleware *.
Utilisez Scrapy et Selenium en combinaison
L'histoire originale est ce débordement de pile.
L'architecture de Scrapy ressemble à ceci (extrait de la documentation de Scrapy).
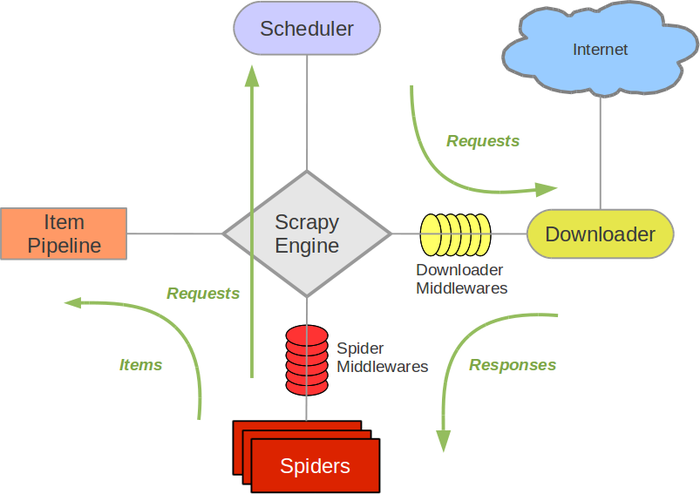
Personnalisez * les middlewares de téléchargement * pour permettre à Scrapy's Spider de gratter avec Selenium.
Implémentation du middleware de téléchargement
Downloader Middleware est implémenté comme une classe ordinaire qui implémente * process_request *.
selenium_middleware.py
# -*- coding: utf-8 -*-
import os.path
from urlparse import urlparse
import arrow
from scrapy.http import HtmlResponse
from selenium.webdriver import Firefox
driver = Firefox()
class SeleniumMiddleware(object):
def process_request(self, request, spider):
driver.get(request.url)
return HtmlResponse(driver.current_url,
body = driver.page_source,
encoding = 'utf-8',
request = request)
def close_driver():
driver.close()
Si vous enregistrez ce middleware de téléchargement, * Spider * appellera * process_request * avant de gratter la page. Pour plus d'informations, cliquez ici (http://doc.scrapy.org/en/1.0/topics/downloader-middleware.html).
Puisqu'il renvoie une instance de * HtmlResponse *, Download Middleware ne sera pas appelé après cela. En fonction du paramètre de priorité, Default Donwload Middleware (comme l'analyse du fichier robots.txt) Notez qu'il ne sera pas appelé.
Ci-dessus, j'utilise Firefox, mais si je veux utiliser PhantomJS, réécrivez la variable * driver *.
Télécharger l'enregistrement du middleware
Enregistrez * Selenium Middleware * dans la classe * Spider * que vous souhaitez utiliser.
some_spider.py
# -*- coding: utf-8 -*-
import scrapy
from ..selenium_middleware import close_driver
class SomeSpider(scrapy.Spider):
name = "some_spider"
allowed_domains = ["somedomain"]
start_urls = (
'http://somedomain/',
)
custom_settings = {
"DOWNLOADER_MIDDLEWARES": {
"some_crawler.selenium_middleware.SeleniumMiddleware": 0,
},
"DOWNLOAD_DELAY": 0.5,
}
def parse(self, response):
#Traitement du robot d'exploration
def closed(self, reason):
close_driver()
- DOWNLOADER_MIDDLEWARES * dans * custom_settings * est le paramètre. J'écris un processus pour la méthode * close * pour fermer la fenêtre Firefox utilisée pour le scraping.
Recommended Posts