Résumé des situations dans lesquelles plotly express peut être utilisé [Quand pouvez-vous l'utiliser depuis matplotlib? ]
introduction
En parlant de dessin de graphiques, matplotlib + serborn est le principal. Au-delà de ceux-ci ** Le potentiel est explicite, ce qui vous permet de créer des graphiques interactifs. ** ** Je voudrais me concentrer sur les points où le complot express est plus pratique que matplotlib + seaborn.
complotement express, j'ai l'impression qu'il n'y a pas beaucoup d'habitude. ** Les graphiques peuvent être tracés avec moins de lignes que l'intrigue, et ceux qui ont utilisé matplotlib devraient pouvoir l'introduire sans trop d'inconfort. ** **
Pensée personnelle ** La scène où l'expression intrigue est utile ** ressemble à ceci. «J'ai écrit un histogramme, mais l'ourlet est trop large à droite, donc je ne comprends pas vraiment ... Cependant, il est difficile d'écrire un graphique avec seulement l'ourlet droit agrandi. ――Je veux faire un graphique à barres empilées, mais les rares sont écrasés. En premier lieu, les graphiques empilés avec seaborn sont gênants. ――Je souhaite vérifier les données qui ne sont pas alignées dans le diagramme de dispersion, mais il est difficile de savoir quelles données ne sont pas alignées. ――J'ai fait un diagramme par paires, mais il y a trop de variables explicatives ... Y a-t-il un moyen de vérifier quelles variables explicatives sont importantes en une seule fois? ――Je souhaite connaître l'heure et la valeur lorsqu'une erreur se produit dans les données de la série chronologique.
Que faire dans cet article
Tracons un graphique pratique par rapport à seaborn Nous utiliserons des données titanesques, des données annuelles sur le nombre de passagers et des données de qualité de vin de l'ensemble de données python comme données d'analyse.
** Avec données titanesques --Hydrogène --Graphique à barres empilées --Boîte moustaches Avec les données du numéro de passager du vol
- Graphique linéaire Avec les données de qualité du vin
- Nuage de points
- Coordonnées parallèles **
J'ai également publié un lien vers le fichier html réel pour ces graphiques. À partir du lien html, vous pouvez ressentir la sensation de bouger réellement. Ça fait du bien. Par exemple, ce graphique. https://nakanakana12.github.io/plotly/hello_world/histgram.html
Cet article est incroyablement détaillé sur la façon de dessiner divers graphiques. Résumé de la méthode de dessin de base de Plotly Express, le standard de facto de la bibliothèque de dessin Python à l'ère Reiwa https://qiita.com/hanon/items/d8cbe25aa8f3a9347b0b
Importer la bibliothèque
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
from sklearn.datasets import load_wine
données titanesques
python
df = pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic3.csv')
#Ajout d'une colonne avec des âges arrondis tous les 10 ans
df["age10"] = df["age"] // 10 * 10
df["survived_num"] = df["survived"]
df["survived"] = df["survived"].replace(1,"alive").replace(0,"dead")
df["sex_num"] = df["sex"].replace("female",1).replace("male",0)
df = df.reset_index()
df.head()

histogramme
** Plotly est pratique pour les distributions avec un long ourlet à droite! ** **
Affiche un histogramme des tarifs. Code couleur selon qu'ils ont survécu. Le tarif n'est pas normalement distribué, mais ** a un long ourlet sur le côté droit **. Dans un tel cas, matplotlib rend difficile la visualisation d'un petit nombre de données, ce qui pose un problème.
Avec plotly, vous pouvez agrandir une petite zone, il est donc facile de saisir la situation.
Dans ce cas, le nombre de personnes au tarif élevé est faible, mais le taux de survie est élevé, simplement en parcourant un graphique.
python
fig = px.histogram(df, x="fare", color="survived",nbins=200, opacity=0.4, marginal="box"
, title="Histogramme des tarifs par Survived")
fig.update_layout(barmode='overlay')
fig.show()
#Enregistrer au format HTML
fig.write_html('./histogram.html', auto_open=False)

Cliquez ici pour le fichier html. Vous pouvez le déplacer. https://nakanakana12.github.io/plotly/hello_world/histgram.html
Graphique à barres empilées
** Avec plotly express, les graphiques à barres empilés sont faciles et faciles à voir! ** **
C'est peut-être la meilleure recommandation.
Le problème avec la création d'un graphique à barres empilées est lorsqu'il existe de nombreuses classifications. Parfois, je ne connais pas le nombre de choses qui sont peu nombreuses. Avec plotly, il est pratique de pouvoir vérifier le nombre en déplaçant le curseur même si le nombre est petit.
Ici, nous avons visualisé si nous avons survécu ou non par l'âge. De plus, j'ai fait un cas où le sexe est affiché ensemble et un cas où le graphique est séparé. Il est bien visualisé que le taux de survie est faible après les années 50 et que le taux de survie est plus élevé pour les femmes.
python
#Prétraitement
df_bar = df.groupby(["survived", "age10","sex"],as_index=False).size().reset_index(drop=True)
df_bar.columns = ["survived", "age10","sex","count"]
df_bar.head()

python
fig = px.bar(df_bar, y="age10", x="count", orientation="h",color="survived"
, title="Survécu par l'âge(Afficher tout ensemble)")
fig.show()
 Cliquez ici pour le fichier html.
https://nakanakana12.github.io/plotly/hello_world/bar.html
Cliquez ici pour le fichier html.
https://nakanakana12.github.io/plotly/hello_world/bar.html
python
fig = px.bar(df_bar, y="age10", x="count", orientation="h",facet_row="sex",color="survived"
, title="Survécu par l'âge")
fig.show()

Cliquez ici pour le fichier html. https://nakanakana12.github.io/plotly/hello_world/bar3.html
Boîte à moustaches
** Facile à vérifier les valeurs aberrantes! ** **
Dans le cas d'une boîte à moustaches, il est pratique de pouvoir vérifier facilement les valeurs aberrantes et les données d'intervalle de confiance.
En outre, je trouve personnellement pratique de spécifier hover_data comme index. Cela facilite la visualisation immédiate de l'index des valeurs aberrantes et des données dans d'autres colonnes.
python
fig = px.box(df, x="pclass", y="age", color="survived", hover_data=["index"])
fig.show()
#Enregistrer au format HTML
fig.write_html('./box.html', auto_open=False)

Cliquez ici pour le fichier html. https://nakanakana12.github.io/plotly/hello_world/box.html
Données sur les passagers des avions
Graphique linéaire
** Connaissez facilement l'heure et la valeur des valeurs anormales! ** **
Dans le cas des données de séries chronologiques, le graphique en traits pointillés est une norme. Tracons la transition mensuelle à partir du nombre de données de passagers.
Vous pouvez sélectionner le graphique à afficher en cliquant sur la légende, ou vous pouvez sélectionner la section d'affichage avec le curseur ci-dessous. Vous pouvez également vérifier les axes x et y des points qui vous intéressent avec la souris.
Pour être honnête, ces données n'en bénéficient pas, mais elles semblent être utiles lorsqu'il y a de nombreuses catégories ou lorsque vous souhaitez vérifier l'axe des x des valeurs aberrantes.
python
df = sns.load_dataset("flights")
fig = px.line(df, x="year", y="passengers", color="month", title="Changements dans le nombre de passagers")
fig.update_layout(xaxis_range=['1949-01-01', '1961-01-01'], # datetime.Peut être spécifié par datetime
xaxis_rangeslider_visible=True)
fig.show()
#Enregistrer au format HTML
fig.write_html('./time_series.html', auto_open=False)

Cliquez ici pour le fichier html. https://nakanakana12.github.io/plotly/hello_world/time_series.html
Données de qualité du vin
Préparation des données
python
data_wine = load_wine()
df = pd.DataFrame(data_wine["data"], columns=data_wine["feature_names"])
df["target_ID"] = data_wine["target"]
df["target"] = df["target_ID"].replace(0,"bad").replace(1,"good").replace(2,"great")
df["alcohol_rank"] = np.where(df["alcohol"] < df["alcohol"].mean(),"low", "high")
df["flavanoids_rank"] = np.where(df["flavanoids"] < df["flavanoids"].mean(),"low", "high")
df = df.reset_index()
df.head()

Nuage de points
** Vous pouvez facilement trouver l'index des données qui vous intéressent! ** **
Il est pratique de pouvoir vérifier facilement quelles données sont une valeur aberrante en pointant la souris sur le diagramme de dispersion.
Ma recommandation personnelle est de spécifier l'index pour hover_data. Si vous faites cela, vous pouvez trouver l'index des données aberrantes simplement en pointant la souris, et vous pouvez facilement vérifier d'autres valeurs.
Il est assez facile de faire des choses comme des parcelles de paires marines.
python
fig = px.scatter(df, x="alcohol", y="color_intensity", color="target",
marginal_x="box", marginal_y="histogram", trendline="ols",
hover_data=["index"],
title="Relation entre la teneur en alcool et l'intensité de la couleur du vin")
fig.show()
#Enregistrer au format HTML
fig.write_html('./scatter.html', auto_open=False)

Cliquez ici pour le fichier html. https://nakanakana12.github.io/plotly/hello_world/scatter.html
python
fig = px.scatter_matrix(df, dimensions=["alcohol", "flavanoids","color_intensity","hue"],color="target",
hover_data=["index"],
title="Analyse de corrélation des variables explicatives du vin")
fig.show()
#Enregistrer au format HTML
fig.write_html('./scatter2.html', auto_open=False)
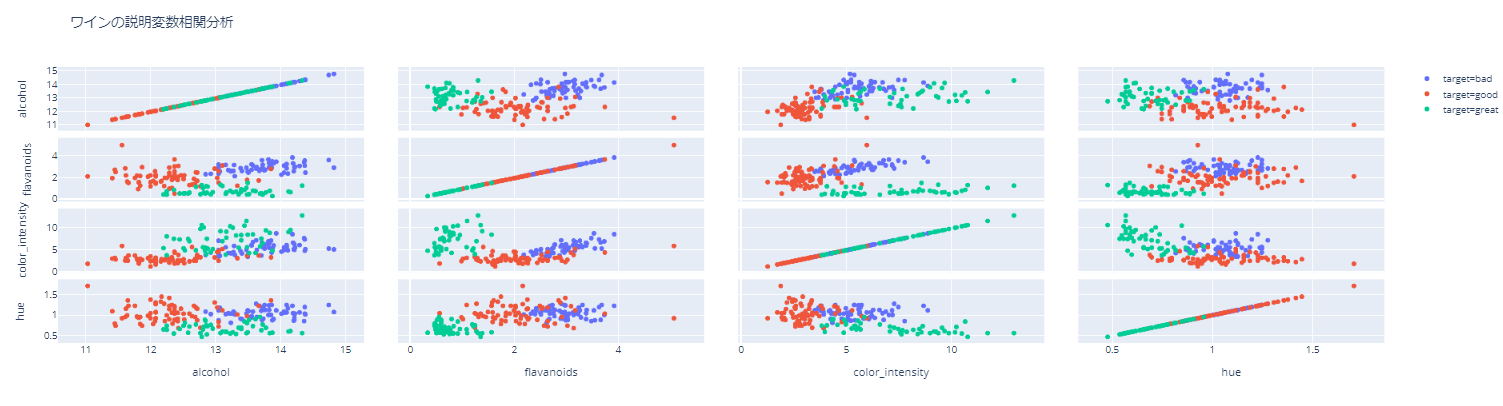
Cliquez ici pour le fichier html. https://nakanakana12.github.io/plotly/hello_world/scatter2.html
Coordonnées parallèles
** Facile à vérifier la corrélation pour chaque variable! !! ** **
Cela peut être extrêmement utile lorsqu'il existe de nombreuses variables explicatives.
En regardant cette figure, il est évident que target_ID augmente lorsque les flavonoïdes et la teinte sont petits et lorsque color_intensity est grand. Je pense que la corrélation des autres variables est également assez facile à comprendre.
Il peut également être utilisé pour les variables catégorisées.
python
fig = px.parallel_coordinates(df, dimensions=["alcohol","flavanoids", "color_intensity","hue"],color="target_ID")
fig.show()
#Enregistrer au format HTML
fig.write_html('./parallel.html', auto_open=False)

Cliquez ici pour le fichier html. https://nakanakana12.github.io/plotly/hello_world/parallel.html
python
#Pour les variables catégorielles
fig = px.parallel_categories(df, dimensions=["alcohol_rank","flavanoids_rank","target"],color="target_ID")
fig.show()
#Enregistrer au format HTML
fig.write_html('./parallel_cat.html', auto_open=False)

Cliquez ici pour le fichier html. https://nakanakana12.github.io/plotly/hello_world/parallel_cat.html
À la fin
Je connaissais lui-même l'intrigue, mais j'avais l'habitude de l'utiliser et j'ai abandonné l'apprentissage. Comparé à cela, ** plotly express est assez facile à démarrer. ** ** C'est vraiment pratique lorsque vous devez vérifier les valeurs aberrantes.
J'aimerais un jour remettre en question la visualisation et l'animation 3D.
Jusqu'à la fin Merci d'avoir lu. Si vous le trouvez utile, il serait encourageant d'utiliser LGTM.