Pandas du débutant, par le débutant, pour le débutant [Python]
Avant de lire cet article
Ceci est un résumé de ce que j'ai écrit pour ne pas l'oublier, avec un peu d'informations ajoutées. S'il est difficile à lire ou à comprendre, veuillez le commenter car nous le corrigerons.
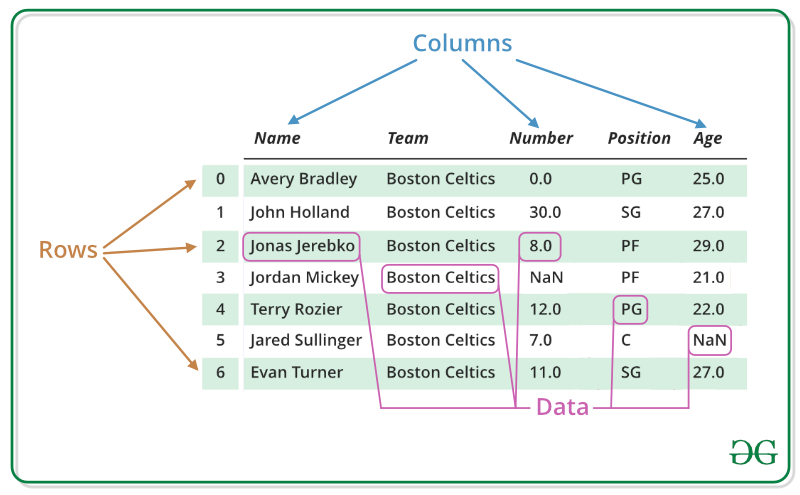 Référence: https://www.geeksforgeeks.org/python-pandas-dataframe/
Référence: https://www.geeksforgeeks.org/python-pandas-dataframe/
Environnement de développement à utiliser
- anaconda
- Pycharm
- Python3.7.7
Modifier l'historique -2020/04/05 -2020/04/05 --Ajout: supprimer les données
Avant de commencer Pandas
#Installer, importer
pip install pandas
import pandas as pd
Jouons réellement avec les pandas.
Obtenez des données
Si vous voulez faire quelque chose avec les pandas, vous devez l'obtenir. Préparez-le au format csv. Cette fois, j'utiliserai une personne infectée par le virus corona (préfecture de Hyogo).
url = "https://web.pref.hyogo.lg.jp/kk03/corona_hasseijyokyo.html"
dfs = pd.read_html(url)
print(dfs[0].head())
#Afficher le tableau HTML à l'invite
>>>
0 1 2 3 4 5 6
0 Nombre Âge Sexe Résidence Occupation Date de l'annonce Remarques
1162 40 Homme Médecin de la ville de Kobe 1er avril NaN
2161 20 Homme Itami Health and Welfare Office Juridiction Company Employee 1 avril NaN
3160 50 femmes au chômage de la ville de Takarazuka au 1er avril NaN
4159 60 Homme Médecin de la ville de Takarazuka 1er avril NaN
#Créez le tableau sur HTML csv.
#Éditeur de texte
import csv
tables = pd.read_html("https://web.pref.hyogo.lg.jp/kk03/corona_hasseijyokyo.html", header=0)
data = tables[0]
data.to_csv("coronaHyogo.csv", index=False) #production
Lire CSV
dfs = pd.read_csv('C:/Users/Desktop/coronaHyogo.csv')
print (dfs)
#Ouvrez CSV avec des pandas
>>>
Nombre Âge Sexe Résidence Profession Date de l'annonce Remarques
0169 40 Homme Employé de bureau de la ville d'Amagasaki 2 avril NaN
1168 60 Homme employé du bureau de la ville d'Ashiya 2 avril NaN
2167 50 Homme Itami Health and Welfare Office Juridiction Company Employee 2 avril NaN
3166 20 Femme Itami City NaN 2 avril NaN
4165 20 Malé Akashi City NaN 2 avril NaN
.. ... .. .. ... ... ... ...
64105 70 Homme Itami City Chômeurs 21 mars NaN
65104 80 Femme au chômage de la ville de Takarazuka 21 mars Décès
66103 60 Homme employé du bureau de la ville d'Amagasaki 21 mars NaN
67102 40 Femme rapatriée (annoncée par le centre de santé de la ville de Himeji) Chômage 21 mars NaN
68101 20 Homme étudiant de la ville d'Amagasaki 20 mars NaN
Confirmation des données
dfs.shape #Vérifiez le nombre de lignes et de colonnes dans le dataframe
>>> (69, 7)
dfs.index #Vérifier l'index
>>> RangeIndex(start=0, stop=69, step=1)
dfs.columns #Vérifier la colonne
>>> Index(['nombre', 'Âge', 'sexe', 'résidence', 'Métier', 'Date de l'annonce', 'Remarques'], dtype='object')
dfs.dtypes #Vérifiez le type de données de chaque colonne de dataframe
>>>
Numéro int64
Âge int64
Objet de genre
Lieu de résidence objet
Objet d'occupation
Objet de date d'annonce
Objet Remarques
dtype: object
Extraction d'informations
df.head(3)
#Extrait de la tête à la troisième ligne.
>>>
Nombre Âge Sexe Résidence Profession Date de l'annonce Remarques
0169 40 Homme Employé de bureau de la ville d'Amagasaki 2 avril NaN
1168 60 Homme employé du bureau de la ville d'Ashiya 2 avril NaN
2167 50 Homme Itami Health and Welfare Office Juridiction Company Employee 2 avril NaN
dfs.tail()
#Tirez par derrière.
>>>
Nombre Âge Sexe Résidence Profession Date de l'annonce Remarques
64105 70 Homme Itami City Chômeurs 21 mars NaN
65104 80 Femme au chômage de la ville de Takarazuka 21 mars Décès
66103 60 Homme employé du bureau de la ville d'Amagasaki 21 mars NaN
67102 40 Femme rapatriée (annoncée par le centre de santé de la ville de Himeji) Chômage 21 mars NaN
68101 20 Homme étudiant de la ville d'Amagasaki 20 mars NaN
dfs[["Âge","sexe","Date de l'annonce"]].head()
#Spécifiez une colonne et extrayez.
>>>
Âge Sexe Date de l'annonce
0 40 Homme 2 avril
1 60 Homme 2 avril
2 50 Homme 2 avril
3 20 femmes 2 avril
4 20 Homme 2 avril
row2 = dfs.iloc[3]
print(row2)
#Seules les troisièmes données du haut sont affichées.
>>>
Numéro 166
20 ans
sexe féminin
Lieu de résidence Itami City
Profession NaN
Date de l'annonce 2 avril
Remarques NaN
Mise en forme des données
dfs.rename(columns={'sexe': 'sex'}, inplace=True)
dfs.head()
#Changement de nom (du sexe au sexe)
>>>
Nombre Âge sexe Lieu de résidence Profession Date de l'annonce Remarques
0169 40 Homme Employé de bureau de la ville d'Amagasaki 2 avril NaN
1168 60 Homme employé du bureau de la ville d'Ashiya 2 avril NaN
2167 50 Homme Itami Health and Welfare Office Juridiction Company Employee 2 avril NaN
dfs.set_index('Âge', inplace=True)
dfs.head()
#
>>>
Numéro Sexe Lieu de résidence Profession Date de l'annonce Remarques
Âge
40169 Homme employé du bureau de la ville d'Amagasaki 2 avril NaN
60168 Homme employé du bureau de la ville d'Ashiya 2 avril NaN
50167 Homme Itami Health and Welfare Office Juridiction Company Employee 2 avril NaN
dfs.index
>>>
Int64Index([40, 60, 50, 20, 20, 70, 50, 40, 20, 50, 60, 60, 60, 10, 30, 60, 10,
30, 20, 60, 60, 30, 60, 60, 20, 70, 60, 20, 20, 30, 40, 40, 30, 20,
20, 50, 30, 70, 60, 60, 70, 20, 60, 30, 50, 40, 30, 10, 50, 70, 20,
80, 20, 80, 40, 70, 30, 80, 60, 70, 40, 70, 90, 80, 70, 80, 60, 40,
20],
df.sort_values(by="Âge", ascending=True).head() # ascending=Vrai par ordre croissant
# 'Âge'Colonnes décroissantes
# df.sort_values(['Âge', 'Date de l'annonce'], ascending=False).head() #Le multiple est possible
>>>
Nombre sexe Lieu de résidence Occupation Date de l'annonce Remarques
Âge
10122 étudiante de la ville de Kobe 27 mars NaN
10153 Étudiante de la ville d'Amagasaki, 1er avril NaN
10156 Étudiante de l'école professionnelle de Kawanishi City 1er avril NaN
20 135 Femme Itami Health and Welfare Office Jurisdiction Company Employé 30 mars NaN
20117 Homme Médecin de la ville de Nishinomiya 24 mars NaN
#Suprimmer les données
print(df.drop(columns=['nombre','résidence']))
Comptez le nombre de données
dfs['Âge'].value_counts()
60 15
20 13
70 9
30 9
40 8
50 6
80 5
10 3
90 1
Name:Âge, dtype: int64
Trouver des indicateurs statistiques
#moyenne
mean = dfs['Âge'].mean()
print(mean) #46.3768115942029
#total
sum = dfs['Âge'].sum()
print(sum) #3200
#Médian
median = dfs['Âge'].median()
print(median) #50.0
#Valeur maximum
dfsmax = dfs['Âge'].max()
print(dfsmax) #90
#valeur minimum
dfsmin = dfs['Âge'].min()
print(dfsmin) #10
#écart-type
std = dfs['Âge'].std()
print(std) #21.418176344401118
#Distribué
var = dfs['Âge'].var()
print(var) #458.73827791986366
Recommended Posts