Le pouvoir des pandas: Python

Pandas Basics### Pandas is a Python package providing fast, flexible, and expressive data structures designed to make working with “relational” or “labeled” data both easy and intuitive. It aims to be the fundamental high-level building block for doing practical, real world data analysis in Python. Additionally, it has the broader goal of becoming the most powerful and flexible open source data analysis / manipulation tool available in any language. It is already well on its way toward this goal.
Pandas is a high-level data manipulation tool developed by Wes McKinney. It is built on the Numpy package and its key data structure is called the DataFrame. DataFrames allow you to store and manipulate tabular data in rows of observations and columns of variables.

pandas is well suited for many different kinds of data: -Données tabulaires avec des colonnes de typage hétérogène, comme dans une table SQL ou une feuille de calcul Excel -Données chronologiques ordonnées et non ordonnées (pas nécessairement à fréquence fixe). ・ Données matricielles arbitraires (typées de manière homogène ou hétérogènes) avec des étiquettes de ligne et de colonne ・ Toute autre forme d'ensembles de données d'observation / statistiques. Les données n'ont en fait pas besoin d'être étiquetées du tout pour être placées dans une structure de données pandas
Here are just a few of the things that pandas does well: ・ Gestion aisée des données manquantes (représentées par NaN) en virgule flottante ainsi que des données en virgule non flottante -Mutabilité de la taille: les colonnes peuvent être insérées et supprimées de DataFrame et d'objets de dimensions supérieures -Alignement automatique et explicite des données: les objets peuvent être explicitement alignés sur un ensemble d'étiquettes, ou l'utilisateur peut simplement ignorer les étiquettes et laisser Series, DataFrame, etc. Aligner automatiquement les données pour vous dans les calculs ・ Groupe par fonctionnalité puissant et flexible pour effectuer des opérations fractionnées-appliquer-combiner sur des ensembles de données, à la fois pour l'agrégation et la transformation des données ・ Facilitez la conversion de données irrégulières et indexées différemment dans d'autres structures de données Python et NumPy en objets DataFrame ・ Tranchage intelligent basé sur les étiquettes, indexation sophistiquée et sous-ensemble de grands ensembles de données ・ Fusion et jonction intuitives d'ensembles de données ・ Remodelage et pivotement flexibles des ensembles de données ・ Étiquetage hiérarchique des axes (possible d'avoir plusieurs étiquettes par tick) ・ Outils E / S robustes pour charger des données à partir de fichiers plats (CSV et délimités), de fichiers Excel, de bases de données et de sauvegarde / chargement de données à partir du format ultra-rapide HDF5 -Fonctionnalité spécifique à la série de temps: génération de plage de dates et conversion de fréquence, statistiques de fenêtre mobile, décalage et décalage de date.
To load the pandas package and start working with it, import the package.
In [1]: import pandas as pd
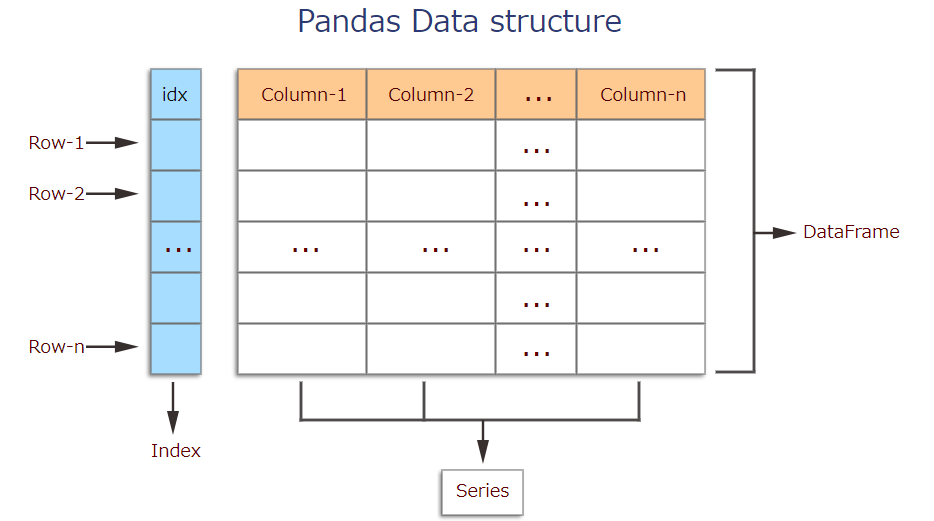
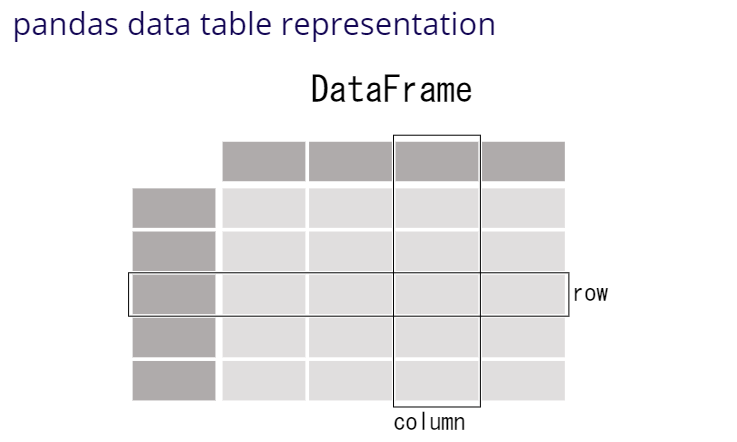
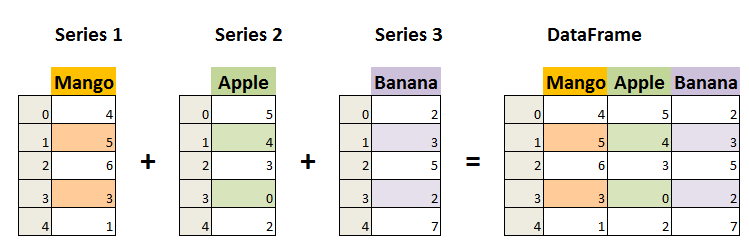
■Creating data The two primary data structures of pandas, Series (1-dimensional) and DataFrame (2-dimensional).Each column in a DataFrame is a Series.
** · Trame de données ** A DataFrame is a table. It contains an array of individual entries, each of which has a certain value. Each entry corresponds to a row (or record) and a column. For example, consider the following simple DataFrame:
In [2]: pd.DataFrame({'Yes': [50, 21], 'No': [131, 2]})
Out [2]:
| Yes | No | |
|---|---|---|
| 0 | 50 | 131 |
| 1 | 21 | 2 |
DataFrame entries are not limited to integers. For instance, here's a DataFrame whose values are strings:
In [3]: pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'], 'Sue': ['Pretty good.', 'Bland.']})
Out [3]:
| Bob | Sue | |
|---|---|---|
| 0 | I liked it. | Pretty good. |
| 1 | It was awful. | Bland. |
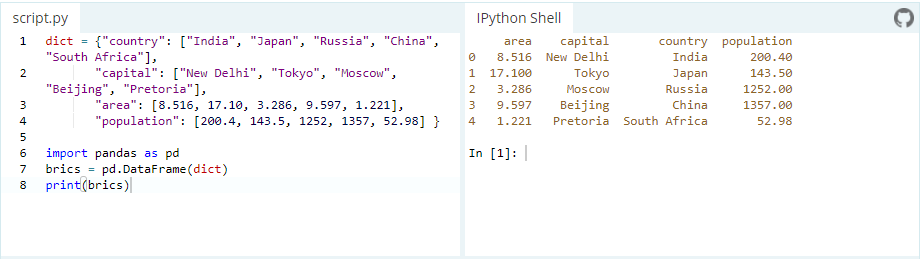
There are several ways to create a DataFrame. One way is to use a dictionary. For example:
** · Séries ** A Series, by contrast, is a sequence of data values. If a DataFrame is a table, a Series is a list. And in fact you can create one with nothing more than a list:
In [4]: pd.Series([1, 2, 3, 4, 5])
Out [4]:
0 1
1 2
2 3
3 4
4 5
dtype: int64
■Reading data files
Another way to create a DataFrame is by importing a csv file using Pandas.
Data can be stored in any of a number of different forms and formats. By far the most basic of these is the humble CSV file. Now, the csv cars.csv is stored and can be imported using pd.read_csv:
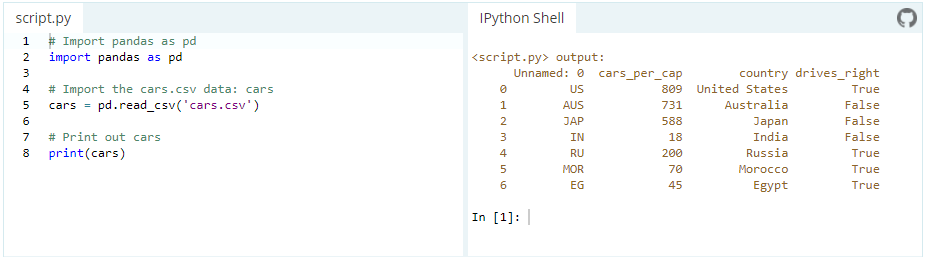
or we can examine the contents of the resultant DataFrame using the head() command, which grabs the first five rows:
In [5]: pd.head()
■ Other Useful Tricks ** ・ Obtenez le répertoire de travail actuel **
In [6]: import os
In [7]: os.getcwd()
** ・ Vérifiez le nombre de lignes et de colonnes présentes dans les données ** (o/p -> no. of rows, no. of columns)
In [8]: pd.shape
Out [8]: (2200, 15)
** ・ Renommez les colonnes **
In [9]: pd_new = pd.rename(colums = {'Amount.Requested': 'Amount.Requested_NEW'})
In [10]: pd_new.head()
** ・ Ecrire un dataframe en csv ou excel **
df.to_csv("filename.csv", index = False)
df.to_excel("filename.xlsx", index = False)
There are two ways to handle the situation where we do not want the index to be stored in csv file.
- you can use index=False while saving your dataframe to csv file.
df.to_csv("file_name.csv", index=False)
2 . Or you can save your dataframe as it is with an index, and while reading you just drop the column unnamed 0 containing your previous index.
df.to_csv("file_name.csv")
df_new = pd.read_csv("file_name.csv").drop(['unnamed 0'],axis=1)
here is the cheat-sheet for pandas. https://pandas.pydata.org/Pandas_Cheat_Sheet.pdf
Enjoy the Power of Pandas and I hope you found it helpful. Thank you for spending the time to read this article. See you in next topic. :grinning: :grinning:
Recommended Posts