Décodage du modèle LSTM de Keras.
Aperçu
J'ai utilisé Keras et Tensorflow pour calculer les poids de mon réseau de neurones, mais il est étonnamment difficile de savoir comment l'utiliser dans de vraies applications (applications iPhone, applications Android, Javascript, etc.).
S'il s'agit d'un simple réseau de neurones, c'est simple, mais comme il fallait utiliser les poids appris en LSTM cette fois, j'ai déchiffré le contenu de Predict of LSTM de Keras.
Les poids appris peuvent être récupérés avec model.get_weights (), mais aucune information sur celui-ci ne sort même si je la recherche sur Google.
Après tout, suite à l'écriture du code et à son essai au hasard, les poids récupérés par model.get_weights () sont
Premier (indice 0): poids de couche d'entrée LSTM pour les entrées, poids de porte d'entrée, poids de porte de sortie, poids de porte d'oubli
Deuxième (indice 1): poids d'entrée de la couche cachée, poids de la porte d'entrée, poids de la porte de sortie, poids de la porte d'oubli
Troisième (index 2): biais pour la couche d'entrée et la couche cachée
Quatrième (indice 3): poids pour l'entrée de couche de sortie (poids pour la sortie de couche cachée)
Cinquième (indice 4): biais vers la couche de sortie (biais vers la sortie de la couche cachée)
J'ai découvert.
Pour comprendre cela, j'ai écrit le code qui (se comportera) comme model.predict () à la fin.
J'espère que la page officielle de Keras a quelque chose comme ça. .. .. ..
Sortie de get_weigts ()
Si weights = model.get_weights (), les poids suivants sont stockés.
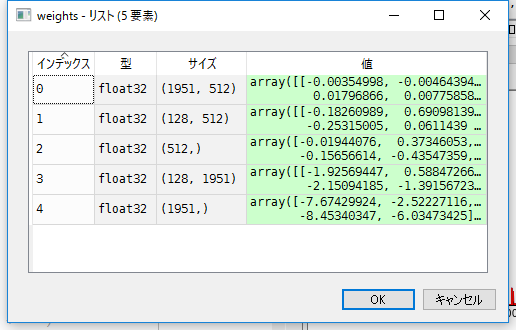
Le nombre 1951 est le nombre de nœuds dans la couche d'entrée, donc il n'y a pas de problème. L'index 3 128 a également le nombre de nœuds de couche masqués défini sur 128, de sorte qu'il peut être considéré comme un poids pour la sortie de la couche masquée. Le problème était 512, ce qui était le plus déroutant.
J'ai soudainement imaginé que quatre types de «poids pour l'entrée, poids pour les portes d'entrée, poids pour les portes de sortie et poids pour les portes d'oubli» sont stockés. Cependant, en regardant la page officielle de Keras, il y a une déclaration que LSTM utilise (unité de stockage à long et court terme - Hochreiter 1997.). En parlant de 1997, la porte de l'oubli n'était pas pondérée. .. .. ?? Il semble que la porte de l'oubli ait été créée en 1999. .. .. .. C'est ce qu'il dit ici aussi ...? http://kivantium.hateblo.jp/entry/2016/01/31/222050
Bien que cela me dérange, j'ai pensé que si j'écrivais le code en solide, ceux-ci seraient clarifiés, alors j'ai décidé d'écrire ce code qui se comporte de la même manière que model.predict.
Code pour démêler model.predict ()
En guise de prémisse, le modèle de LSTM utilisé pour le décodage cette fois est le suivant. Exemple de code pour générer des phrases à l'aide de LSTM.
from __future__ import print_function
from keras.models import Sequential
from keras.layers import Dense, Activation
from keras.layers import LSTM
from keras.optimizers import RMSprop
from keras.utils.data_utils import get_file
import numpy as np
import random
import sys
from keras.models import model_from_json
import copy
import matplotlib.pyplot as plt
import math
#path = get_file('nietzsche.txt', origin='https://s3.amazonaws.com/text-datasets/nietzsche.txt')
text = open('hokkaido_x.txt', 'r', encoding='utf8').read().lower()
print('corpus length:', len(text))
chars = sorted(list(set(text)))
print('total chars:', len(chars))
char_indices = dict((c, i) for i, c in enumerate(chars))
indices_char = dict((i, c) for i, c in enumerate(chars))
# cut the text in semi-redundant sequences of maxlen characters
#maxlen = 40
maxlen = 3
step = 2
sentences = []
next_chars = []
for i in range(0, len(text) - maxlen, step):
sentences.append(text[i: i + maxlen])
next_chars.append(text[i + maxlen])
print('nb sequences:', len(sentences))
print('Vectorization...')
X = np.zeros((len(sentences), maxlen, len(chars)), dtype=np.bool)
y = np.zeros((len(sentences), len(chars)), dtype=np.bool)
for i, sentence in enumerate(sentences):
for t, char in enumerate(sentence):
X[i, t, char_indices[char]] = 1
y[i, char_indices[next_chars[i]]] = 1
# build the model: a single LSTM
print('Build model...')
model = Sequential()
model.add(LSTM(128, input_shape=(maxlen, len(chars)),activation='sigmoid',inner_activation='sigmoid'))
model.add(Dense(len(chars)))
model.add(Activation('softmax'))
optimizer = RMSprop(lr=0.01)
model.compile(loss='categorical_crossentropy', optimizer=optimizer)
def sample(preds, temperature=1.0):
# helper function to sample an index from a probability array
preds = np.asarray(preds).astype('float64')
preds = np.log(preds) / temperature
exp_preds = np.exp(preds)
preds = exp_preds / np.sum(exp_preds)
probas = np.random.multinomial(1, preds, 1)
return np.argmax(probas)
model.fit(X, y, batch_size=64, epochs=1)
diversity = 0.5
print()
generated = ''
sentence = "Godzilla"
# sentence = text[start_index: start_index + maxlen]
generated += sentence
# print('----- Generating with seed: "' + sentence + '"')
# sys.stdout.write(generated)
# for i in range(400):
x = np.zeros((1, maxlen, len(chars)))
for t, char in enumerate(sentence):
x[0, t, char_indices[char]] = 1.
preds = model.predict(x, verbose=0)[0]
plt.plot(preds,'r-')
plt.show()
D'autre part, le code suivant renvoie la même valeur que «model.predict». Je suis fatigué d'écrire pour des déclarations, donc je les ai décrites comme c1, c2, c3, etc., mais ces nombres correspondent à maxlen dans le modèle ci-dessus. Si vous souhaitez augmenter maxlen, vous pouvez créer une structure de boucle avec un document for. Pour le code, je me suis référé au site suivant. http://blog.yusugomori.com/post/154208605320/javascript%E3%81%AB%E3%82%88%E3%82%8Bdeep-learning%E3%81%AE%E5%AE%9F%E8%A3%85long-short-term
print(preds)
weights = model.get_weights()
obj=weights
w1=obj[0]
w2=obj[1]
w3=obj[2]
w4=obj[3]
w5=obj[4]
hl = 128
def sigmoid(x):
return 1.0 / (1.0 + np.exp(-x))
def tanh(x):
return (np.exp(x)-np.exp(-x))/(np.exp(x)+np.exp(-x))
def activate(x):
x[0:hl] = sigmoid(x[0:hl]) #i
x[hl:hl*2] = sigmoid(x[hl:hl*2]) #a
x[hl*2:hl*3] = sigmoid(x[hl*2:hl*3]) #f
x[hl*3:hl*4] = sigmoid(x[hl*3:hl*4]) #o
return x
def cactivate(c):
return sigmoid(c)
x1 = np.array(x[0,0,:])
x2 = np.array(x[0,1,:])
x3 = np.array(x[0,2,:])
h1 = np.zeros(hl)
c1 = np.zeros(hl)
o1 = x1.dot(w1)+h1.dot(w2)+w3
o1 = activate(o1)
c1 = o1[0:hl]*o1[hl:hl*2] + o1[hl*2:hl*3]*c1
#c1 = o1[0:128]*o1[128:256] + c1
h2 = o1[hl*3:hl*4]*cactivate(c1)
#2e
o2 = x2.dot(w1)+h2.dot(w2)+w3
o2 = activate(o2)
c2 = o2[0:hl]*o2[hl:hl*2] + o2[hl*2:hl*3]*c1
#c2 = o2[0:128]*o2[128:256] + c1
h3 = o2[hl*3:hl*4]*cactivate(c2)
#3e
o3 = x3.dot(w1)+h3.dot(w2)+w3
o3 = activate(o3)
c3 = o3[0:hl]*o3[hl:hl*2] + o3[hl*2:hl*3]*c2
#c3 = o3[0:128]*o3[128:256] + c2
h4 = o3[hl*3:hl*4]*cactivate(c3)
y = h4.dot(w4)+w5
y = np.exp(y)/np.sum(np.exp(y))
plt.plot(y,'b-')
plt.show()
En conséquence, vous pouvez voir que preds et y produisent des valeurs similaires.
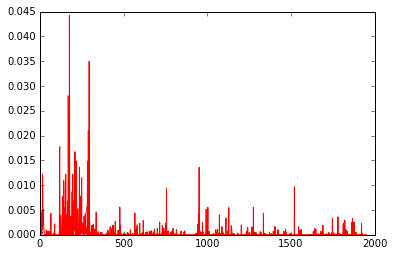 résultats du tracé preds
résultats du tracé preds
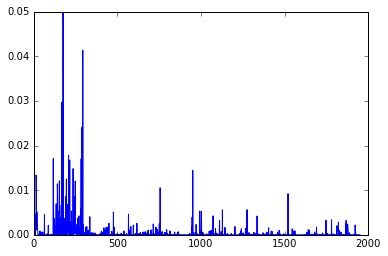 résultat du tracé de y
résultat du tracé de y
À propos, le code ci-dessus utilise sigmoïde pour la fonction d'activation et la fonction de cellule interne, mais pour une raison quelconque, il n'a pas fonctionné avec tanh. Je veux mettre à jour quand il est résolu.
Recommended Posts