word2vec
Motivation ・ Word2vec peut donner un vecteur qui peut exprimer la signification d'un mot d'une bonne manière simplement en donnant une grande quantité de texte. ・ Si vous utilisez ce bon vecteur comme quantité de caractéristiques, vous pouvez vous attendre à une amélioration de la précision dans diverses tâches. ・ ・ Je souhaite améliorer l'exactitude des informations recommandées ・ ・ Utiliser comme quantité de fonctionnalités pour les tâches de prédiction FX pour améliorer la précision, etc. ··Visualisation
・ (Touchez une extrémité de l'apprentissage en profondeur)
position
・ En plus de comprendre word2vec, je souhaite l'utiliser pour faire des choses intéressantes et améliorer la précision des tâches.
Agenda | Plan ・ Découvrez la qualité du vecteur obtenu par word2vec (c'est aujourd'hui) ・ Appliquez le vecteur obtenu par word2vec à la tâche de recommandation d'informations et comparez-le avec le résultat d'un vecteur normal. -Appliquer le vecteur obtenu par word2vec à la tâche de prévision d'échange et le comparer avec le résultat d'un vecteur normal. ・ Appliquer le vecteur obtenu par word2vec à la visualisation telle que l'analyse des caractères pour visualiser le goût sans emprunter de subjectivité humaine. ・ ・ Exemple de visualisation de mots mimiques
 http://techlife.cookpad.com/entry/2015/02/27/093000
http://techlife.cookpad.com/entry/2015/02/27/093000
Qu'est-ce que word2vec
・ Si vous donnez une grande quantité de texte en entrée, quelque chose comme une boîte noire qui crée un vecteur qui peut exprimer la signification de chaque mot d'une bonne manière
Essayez différentes choses
Tout d'abord, essayez de créer un vecteur avec word2vec
Entrée: 100 Mo d'anglais ↓ word2vec ↓ Sortie: représentation vectorielle (200 dimensions) pour chaque mot
Le code source est très simple à écrire
genModel.py
import gensim
sentences = gensim.models.word2vec.Text8Corpus("/tmp/text8")
model = gensim.models.word2vec.Word2Vec(sentences, size=200, window=5, workers=4, min_count=5)
model.save("/tmp/text8.model")
print model["japan"]
(Exemple) Vecteur du mot "japon"
aaa.txt
[-0.17399372 0.138354 0.18780831 -0.09954771 -0.05048304 0.140431
-0.08839419 0.0392667 0.267914 -0.05268065 -0.04712765 0.09693304
-0.03826345 -0.11237499 -0.12375604 0.15184014 0.09791548 -0.0411933
-0.26620147 -0.14839527 -0.07404629 0.14330374 -0.15179957 0.00764518
0.01670248 0.15400286 0.03410995 -0.32461527 0.50180262 0.29173616
0.17549005 -0.13509558 -0.20063001 0.50294453 0.11713456 -0.1423867
-0.17336504 0.09798998 -0.22718145 -0.18548743 -0.08841871 -0.10192692
0.15840843 -0.12143259 0.14727007 0.2040498 0.30346033 -0.05397578
0.17116804 0.09481478 -0.19946894 -0.10160322 0.0196885 0.11808696
-0.04913231 0.17468756 -0.14707023 0.02459025 0.11828485 -0.01075778
-0.13718656 0.05486668 0.25277957 -0.16104579 0.0396373 0.14481564
0.22176275 -0.17076172 -0.038408 0.29362577 -0.13069664 0.04339954
0.00451817 0.16272108 0.02541053 -0.14659256 0.16529948 0.13884881
-0.1113431 -0.09699004 0.07190027 -0.04339439 0.17680296 -0.21379708
0.1572576 0.03031984 -0.21495718 0.03347488 0.22941446 -0.13862187
0.21907888 -0.13375367 -0.13810037 0.09477621 0.13297808 0.25428322
-0.03635533 -0.1352797 -0.13009973 -0.01995344 0.05807789 0.34588996
0.10643663 -0.02748342 0.00877294 0.10331466 -0.02298069 0.26759195
-0.24946833 0.0619933 0.06216418 -0.20149906 0.0586744 0.16416067
0.34322274 0.25680053 -0.03443218 -0.07131385 -0.08819276 -0.02436011
0.01131095 -0.11262415 0.08383768 -0.17228018 -0.04570909 0.00717434
-0.04942331 0.01721579 0.19824736 -0.14876001 0.10319072 0.10815206
-0.24551305 0.02878521 0.17684355 0.13430905 0.03504089 0.14440946
-0.12238772 -0.09751064 0.22464643 -0.00364726 0.30931923 0.04332043
-0.00956943 0.40026045 -0.11306871 0.07663886 -0.21093726 -0.24558903
-0.11918587 -0.11373471 -0.04725014 0.16204022 0.06828773 -0.09220605
-0.04137927 0.06957231 0.29234451 -0.20949519 0.24574679 -0.14875519
0.24135616 0.13015954 0.03091074 -0.45729914 0.14642039 0.1330456
0.09597694 0.19738108 -0.08785061 0.15975344 0.11823107 0.10955801
0.43996817 0.22706555 -0.01743319 0.06030531 -0.08983251 0.43928599
0.07300217 -0.31112081 0.25329435 -0.02628026 -0.0781511 -0.03673798
0.01265055 -0.08048201 -0.0556048 0.25650752 0.02342006 -0.17268351
0.06641581 -0.04409864 0.02202901 -0.12416532 0.08068784 0.12611917
0.00144407 -0.24265616]
Je ne sais pas si c'est bon ou mauvais de simplement regarder ce vecteur, alors je vais appliquer ce vecteur à quelque chose
Essayez l'application 1: recherchez des mots similaires
Affichons les 5 premiers mots similaires à "japon". (Obtenu en utilisant le vecteur word2vec et la similitude cos)
china 0.657877087593 india 0.605986833572 korea 0.598236978054 thailand 0.584705531597 singapore 0.552470624447
Les pays ayant des liens étroits sont en tête. A titre de comparaison, si vous trouvez les 5 premiers mots de la même manière avec un vecteur ordinaire (un vecteur formé par la fréquence d'apparition des mots qui coexistent avec le mot d'intérêt) sans utiliser word2vec,
in 0.617413123609 pensinula 0.604392809245 electification 0.602260135469 kii 0.5864838915 betrayers 0.575804870177
Et un résultat subtil. Je pense que ce sera mieux si vous mâchez tf-idf etc.
Essayez l'application 2: Visualisation du sens
Visualisez le vecteur obtenu à partir de word2vec et confirmez que la relation positionnelle exprime le sens. Par exemple, l'exemple ci-dessous trace deux mots pour certaines paires pays-capitale. La relation positionnelle entre le pays et la capitale est établie dans tous les cas → La notion de relation entre le pays et la capitale peut être appréhendée.
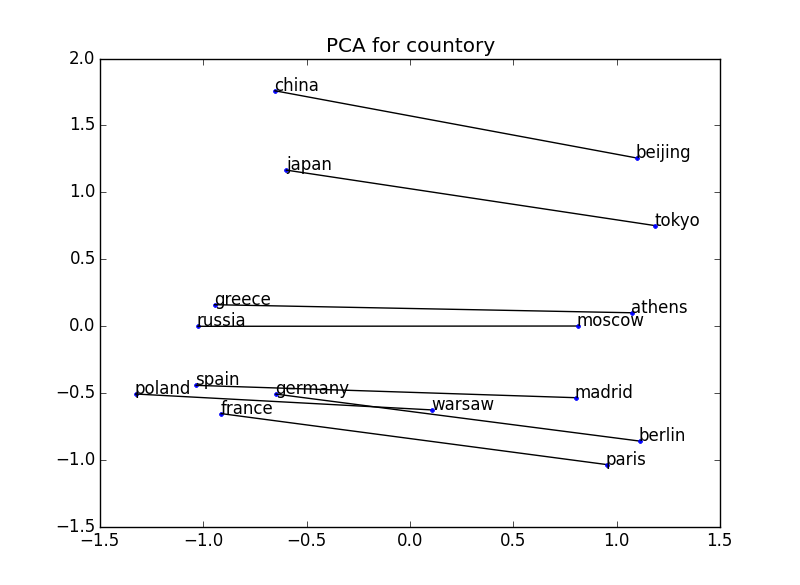 200 dimensions → 2 dimensions
200 dimensions → 2 dimensions
A titre de comparaison, nous avons tracé de la même manière avec un vecteur ordinaire (un vecteur formé par la fréquence d'occurrence des mots coexistant avec le mot d'intérêt) sans utiliser word2vec. Je pense que ce sera un peu mieux si cela est également normalisé.
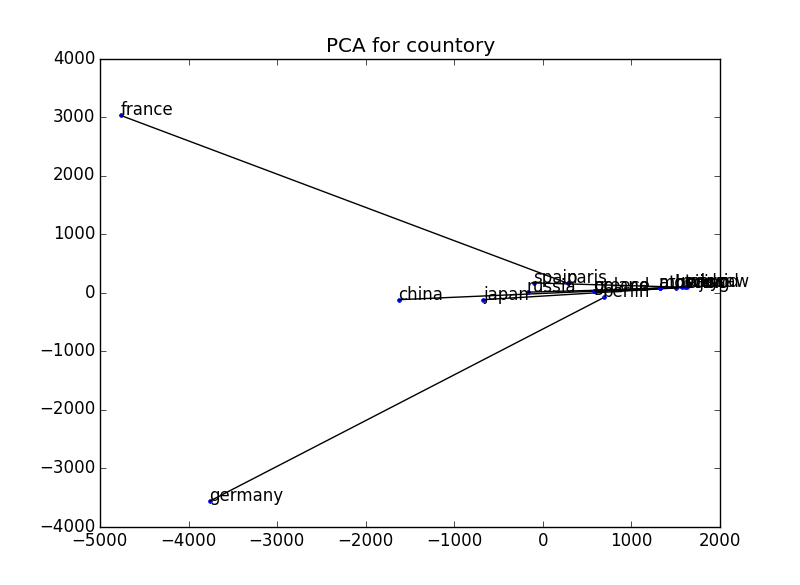 229 73 dimensions → 2 dimensions
229 73 dimensions → 2 dimensions
- Lors de la visualisation, la dimension du vecteur est réduite à 2 dimensions en utilisant l'analyse en composantes principales. Référence: http://breakbee.hatenablog.jp/entry/2014/07/13/191803
Exemple dans un livre:


Essayez l'application 3: Calcul de la signification
Si la signification est correctement exprimée en tant que vecteur, vous devriez pouvoir calculer la signification.
・ Roi - homme + femme = reine (Q: Quel est le roi des hommes pour les femmes? R: Reine) ・ Paris --France + Italie = Rome (Q: Qu'est-ce que Paris pour la France pour l'Italie? A: Rome)
Si vous ajoutez ou soustrayez le vecteur comme ci-dessus, vous pouvez réellement obtenir le résultat de ce calcul.
Autres méthodes conventionnelles par rapport aux informations appropriées de word2vec
Selon une étude de Mikolov et al., Afin de mesurer la capacité de cette addition et de cette soustraction, des tests tels que "Athène - Grèce + Oslo est correct si elle devient Norvège" ont montré que le taux de réponse correcte était de 9% ou 23% avec la méthode conventionnelle. Cependant, le modèle Skip-gram implémenté dans word2vec semble avoir considérablement amélioré le taux de précision à 55%. "
Extrait :: Yasukazu Nishio. "Traitement du langage naturel par word2vec"
Comment fonctionne word2vec
Abréviation
Image du fonctionnement de word2vec
Cette image et cette description m'ont beaucoup aidé.
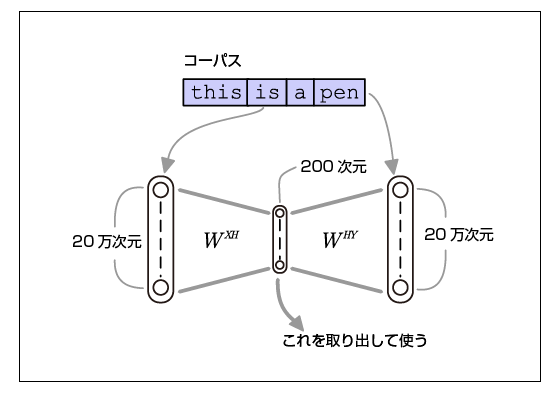
"La fonctionnalité est de mettre les mêmes données à la fois en entrée et en sortie. Si vous faites un tel apprentissage, vous pouvez penser qu'un réseau de neurones ennuyeux (mappage uniforme) qui produit la même chose que l'entrée grandira. La clé de cette méthode est que la taille de la couche masquée est définie si petite qu'elle ne peut pas apprendre un mappage constant. Par conséquent, Autoencoder apprend à regrouper autant d'informations que possible dans une couche cachée limitée, et par conséquent, le poids de la couche d'entrée → couche cachée est une représentation vectorielle de faible dimension des caractéristiques des données d'entrée. Le problème que le réseau de neurones apprend n'est pas le problème que vous voulez résoudre, mais l'expression distribuée que le réseau de neurones crée en laissant le réseau de neurones résoudre le problème difficile est précieuse. Omission Si le nombre de vocabulaire est de 200 000 dimensions, la couche intermédiaire de 200 dimensions n'a que 1/1 000 dimensions. Dans cette situation difficile, l'apprentissage est fait pour augmenter le taux de précision du problème de prédiction "deviner les mots environnants". De cette manière, la conversion est effectuée de sorte que les mots ayant un "degré de fréquence d'apparition des mots environnants" similaire deviennent des vecteurs à distance proche. "
Extrait :: Yasukazu Nishio. "Traitement du langage naturel par word2vec"
la mise en oeuvre
・ Autour de word2vec: gensim -Lors de la visualisation, la dimension du vecteur est réduite à deux dimensions en utilisant l'analyse en composantes principales. Référence: http://breakbee.hatenablog.jp/entry/2014/07/13/191803