Une collection de méthodes utilisées lors de l'agrégation de données avec des pandas
Lire le fichier CSV
data = pd.read_csv("sample.csv", encoding="UTF-8")
data
résultat

Contenu de sample.csv
Inutile,Inutile,Inutile,Inutile,Inutile,Inutile
Inutile,Titre A,Titre B,Titre C,Titre D,Inutile
Inutile,10,20,30,40,Inutile
Inutile,100,200,300,400,Inutile
Inutile,Inutile,Inutile,Inutile,Inutile,Inutile
J'enregistre les données qui se trouvaient dans la feuille de calcul Google au format CSV et j'imagine les données lors de leur analyse. Je pense qu'il y a pas mal de feuilles où les mémos et remarques sont rédigés sans être structurés. Je pense que vous pouvez sélectionner la gamme lors de la sauvegarde, mais cette fois, je vais essayer de l'organiser avec des pandas après la pratique.
Remplacez le contenu de la ligne spécifiée par le nom de la colonne
data.columns = data.iloc[0]
data
résultat

Extraire uniquement les lignes / colonnes spécifiées
data = data.iloc[1:3,1:5]
data
résultat
 C'est juste ce que je veux.
C'est juste ce que je veux.
Produire diverses statistiques récapitulatives (échec)
data.describe()
résultat
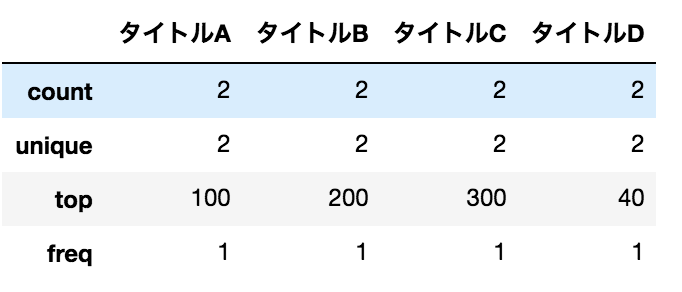 Je pensais que la moyenne, etc. sortirait, mais ce n'est pas le cas.
C'est parce que le type de valeur n'est pas numérique.
Je pensais que la moyenne, etc. sortirait, mais ce n'est pas le cas.
C'est parce que le type de valeur n'est pas numérique.
Changer le type de valeur
data = data.astype('int')
data
résultat

Produire diverses statistiques récapitulatives (succès)
data.describe()
résultat

Obtenez le coefficient de corrélation
data.corr()
résultat
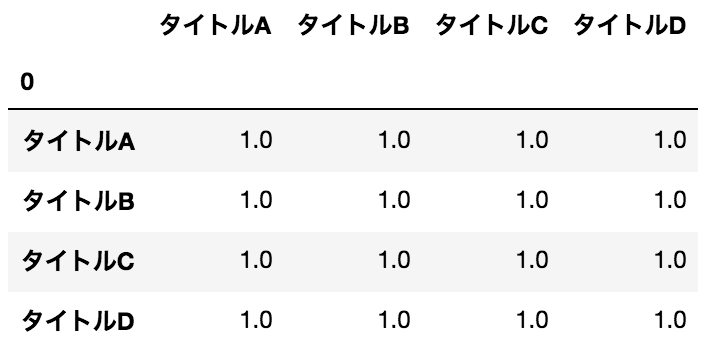 #### Remarques
Je ne sais pas quel est le 0 en haut à gauche
#### Remarques
Je ne sais pas quel est le 0 en haut à gauche
Diverses autres choses
data.sum() #total
data.skew() #asymétrie
data.kurt() #kurtosis
data.var() #Distribué
data.cov() #Matrice de covariance
Remarques
- Il était facile de comprendre la covariance http://mathtrain.jp/covariance
- Il était facile de comprendre la matrice de covariance http://mathtrain.jp/covariance
Diagramme de barbe de boîte d'affichage
%matplotlib inline #Obligatoire pour afficher sur la page
data.plot(kind='box')
résultat
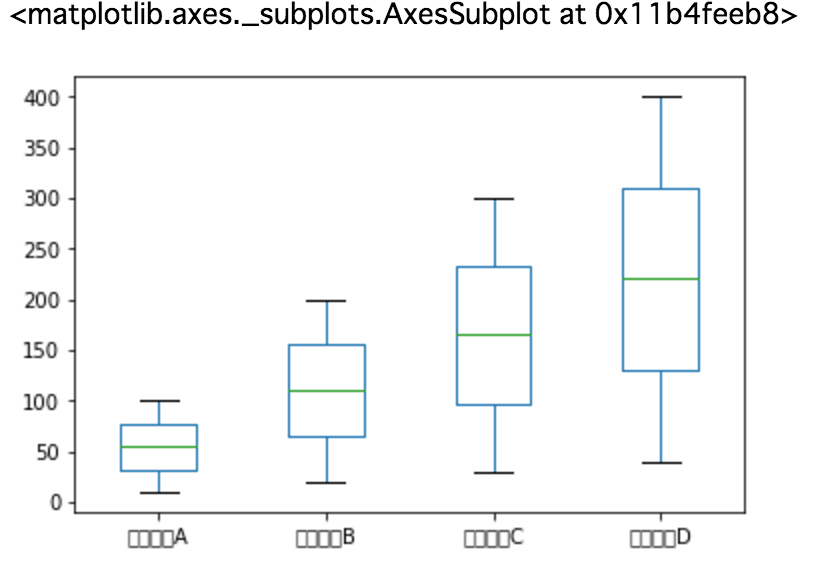 #### Remarques
L'étiquette japonaise n'est pas affichée, mais le japonais est
```
matplotlib.rcParams['font.family'] = 'M+ 1c' #Police spécifiable
```
Il peut être affiché en spécifiant comme.
Les polices qui peuvent être spécifiées sont
```
import matplotlib.font_manager as fm
fm.findSystemFonts()
```
Vous pouvez le découvrir sur.
http://qiita.com/hagino3000/items/1b54acc01483ccd0ac72
Je l'ai mentionné.
#### Remarques
L'étiquette japonaise n'est pas affichée, mais le japonais est
```
matplotlib.rcParams['font.family'] = 'M+ 1c' #Police spécifiable
```
Il peut être affiché en spécifiant comme.
Les polices qui peuvent être spécifiées sont
```
import matplotlib.font_manager as fm
fm.findSystemFonts()
```
Vous pouvez le découvrir sur.
http://qiita.com/hagino3000/items/1b54acc01483ccd0ac72
Je l'ai mentionné.
Jointure DataFrame (direction des lignes)
pd.concat([data,data])
résultat

Jointure DataFrame (direction de la colonne)
pd.concat([data,data], axis=1)
résultat

Changer toutes les valeurs
data.pipe(lambda df: df / 2)
résultat

Trier par valeur
data['Titre A'].sort_values(ascending = True)
résultat
