Pensez aux spécifications pour le développement de moteurs de recommandation de co-filtrage
Je veux faire une recommandation de co-filtrage, mais il n'y a pas de bonne bibliothèque open source, et le service ASP est essentiellement de 50 000 yens / mois ou plus. Je n'ai pas d'autre choix que de le faire moi-même
Qu'est-ce que la recommandation de co-filtrage?
Je pense que l'exemple de mise en œuvre le plus connu est la fonction "Les personnes qui ont acheté ce produit ont également acheté ce produit". Auparavant, j'ai présenté Implémentation de la version simplifiée. Cet article est une continuation de la version simplifiée de l'article.
Cité du co-filtrage de wikipedia
Le filtrage collaboratif (Collaborative Filtering, CF) est une méthodologie qui accumule les informations de préférence de nombreux utilisateurs et effectue automatiquement des inférences en utilisant les informations d'autres utilisateurs qui ont des préférences similaires à celles d'un utilisateur. Il est souvent comparé au principe du bouche-à-oreille, qui renvoie aux opinions de personnes aux goûts similaires.
 Comme le rebut et la construction de M. Haneda, un écrivain de musculation qui a remporté le prix en même temps que l'étincelle, est recommandé en premier, c'est M. Amazon, qui a remporté le prix Naoki.
Comme le rebut et la construction de M. Haneda, un écrivain de musculation qui a remporté le prix en même temps que l'étincelle, est recommandé en premier, c'est M. Amazon, qui a remporté le prix Naoki.
Le filtrage coopératif est une technologie morte
Si vous pêchez sur le Web, il existe un article japonais datant de 2005. En outre, il existe de nombreuses entreprises qui fournissent des services de recommandation, et vous pouvez trouver de nombreuses entreprises en effectuant une recherche (bien qu'elles soient toutes chères), il semble donc que la théorie qui peut être faite soit sur le marché.
Il semble que le co-filtrage soit généralement réalisé par corrélation avec le coefficient de Jaccard. La formule de calcul du coefficient Jaccard pour le produit X et le produit A est la suivante.
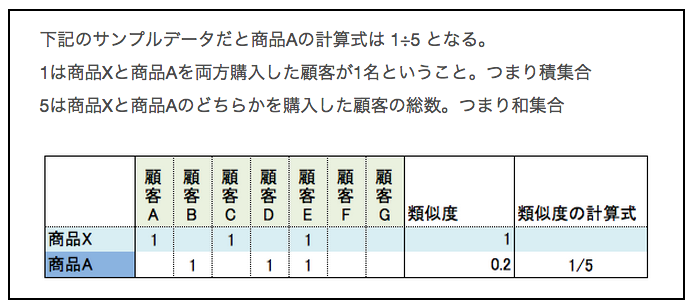
Ainsi, s'il y a 1 million de produits, il faut calculer le coefficient Jaccard 1 million de fois pour calculer les produits recommandés à partir du produit X. Le montant du calcul explose. Cette méthode de calcul n'est pas réaliste.
Le co-filtrage est une technologie morte. Les ancêtres qui ont rencontré les problèmes ci-dessus ont proposé plusieurs solutions. Amazon a publié un article qui peut être résolu en créant un index inversé en 2003.
Code de validation d'index inversé
Des échantillons pour calculer le coefficient Jaccard sont dispersés sur le Web, mais je ne trouve pas d'échantillon qui crée un index inversé pour le résoudre. La seule chose concrète que j'ai trouvée était [Calcul de similarité dans les recommandations: tendances et contre-mesures #DSIRNLP 4th 2013.9.1](https://speakerdeck.com/komiya_atsushi/rekomendoniokerulei-si-du-ji- Créons un index inversé en nous référant au matériau suan-sofalseqing-xiang-todui-ce-number-dsirnlp-di-4hui-2013-dot-9-1).
# -*- coding: utf-8 -*-
from __future__ import absolute_import, unicode_literals
#ID produit:10 acheteurs
from collections import defaultdict
ITEM_10_BUY_USERS = ['A', 'C', 'E', 'G']
#Historique des achats de produits de l'acheteur(Index inversé)
INDEX_BASE = 'INDEX_BUY_HISTORY_USER_{}'
INDEX = {
'INDEX_BUY_HISTORY_USER_A': [10, 20, 50, 60, 90],
'INDEX_BUY_HISTORY_USER_B': [20, 20, 50, 60, 70],
'INDEX_BUY_HISTORY_USER_C': [10, 30, 50, 60, 90],
'INDEX_BUY_HISTORY_USER_D': [30, 40, 50, 60],
'INDEX_BUY_HISTORY_USER_E': [10],
'INDEX_BUY_HISTORY_USER_F': [70, 80, 90],
'INDEX_BUY_HISTORY_USER_G': [10, 70, 90],
}
#Calculer la similitude à l'aide de l'indice inverse
result = defaultdict(int)
for user_id in ITEM_10_BUY_USERS:
#Obtenez l'historique des achats pour chaque utilisateur d'INDEX
buy_history = INDEX.get(INDEX_BASE.format(user_id))
#Agréger le nombre d'articles achetés
for item_id in buy_history:
result[item_id] += 1
l = []
for key in result:
l.append((key, result[key]))
#Montrer la similitude des résultats
l.sort(key=lambda x: x[1], reverse=True)
print l
>>> [(10, 4), (90, 3), (50, 2), (60, 2), (70, 1), (20, 1), (30, 1)]
Il a été constaté que les produits présentant une forte similitude avec le produit 10 ont la corrélation la plus élevée dans l'ordre du produit 90, du produit 50 et du produit: 60. Avec cette méthode, la quantité de calcul est inférieure au coefficient de Jaccard qui calcule la similitude avec tous les produits, et il semble possible de contrôler la quantité de calcul en contrôlant le nombre d'utilisateurs auquel se référer.
Le cœur du moteur de recommandation est la vitesse de mise à jour
Par exemple, nous exploitons un site de vente avec 1 million de produits et 1 million d'utilisateurs. "Spark" sorti le 11 mars 2015 est devenu un grand succès à partir de la date de sortie et s'est vendu à 50 000 exemplaires en un jour. S'il y a beaucoup de produits, un petit festival aura lieu une fois par semaine, il semble donc que la rapidité avec laquelle nous mettons à jour les recommandations d'un million de produits entraînera directement des ventes.
Cependant, la quantité de calcul est énorme. Le monde de la concurrence est la rapidité avec laquelle vous pouvez mettre à jour. En tant que fonction requise pour le moteur de recommandation, il peut être nécessaire de disposer d'un mécanisme permettant le calcul parallèle. Lorsque le producteur me dit que l'intervalle de mise à jour ne peut pas être réduit à 1/4, je mets à jour avec 4 unités maintenant, donc si je calcule avec 16 unités, soit 4 fois, ce sera 1/4. Puisqu'une unité coûte 50 000 yens par mois, le coût mensuel augmente de 5 x 12 = 600 000 yens. Ce serait bien si vous pouviez répondre. (Le producteur doit partir et l'ingénieur doit être en mesure de revenir à l'heure.)
Je pense que Redis est bon pour le back-end
Je pense que Redis est un bon backend pour le moteur de recommandation. Il est mort, il est lu rapidement, il est fourni par AWS, il fonctionne dans un seul thread, donc s'il est utilisé correctement, les données sont garanties atomiques et les E / S sont plus rapides que RDS. Il est également facile à utiliser car il existe des bibliothèques de Ruby, PHP, Node.js et Perl. Être garanti Atomic signifie thread-safe. En d'autres termes, on considère qu'il remplit les conditions qui peuvent être utilisées comme backend pour le calcul parallèle.
- Je pense que l'implémentation idéale est une méthode dans laquelle le backend peut être sélectionné avec data_handler.
spécification
- l'installation de pip est possible
- Il a une fonction d'étiquette et peut être recommandé pour chaque étiquette.
- La mise à jour des produits recommandés peut être exécutée en parallèle
- Disponible depuis Ruby et PHP
- Le produit peut être supprimé
- L'historique des achats de l'utilisateur peut être modifié
- L'utilisateur peut être supprimé
Objectif de performance
Avec 1 million de produits, 1 million d'utilisateurs et une moyenne de 50 achats par utilisateur
- Toutes les mises à jour des recommandations peuvent être effectuées dans les 4 heures sur un seul MacBook Pro
- La mise à jour des produits recommandés doit être effectuée dans les 10 secondes avec un MacBook Pro par produit
J'aimerais pouvoir l'appeler comme ça
[sample]Au moment de l'introduction du nouveau système
#Enregistrer tous les produits
for goods in goods.get_all():
Recomender.register(goods.id, tag=goods.tag)
#Enregistrer tout l'historique des achats
for user in user.get_all():
Recomender.like(user.id, user.history.goods_ids)
# sample1.Mettre à jour les recommandations pour tous les produits(Fil unique)
Recomender.update_all()
# sample2.Mettre à jour les recommandations pour tous les produits(Filetage multithread)
Recomender.update_all(proc=4)
# sample3.Mettre à jour les recommandations pour tous les produits(4 clusters parallèles x 4 parallèles)
#Cluster parallèle.1 Première moitié de tous les produits 1/Calculer 4
Recomender.update_all(proc=4, scope=[1, 4])
#Cluster parallèle.2 Première moitié de tous les produits 1/Calculer 4
Recomender.update_all(proc=4, scope=[2, 4])
#Cluster parallèle.3 Deuxième moitié de tous les produits 1/Calculer 4
Recomender.update_all(proc=4, scope=[3, 4])
#Cluster parallèle.4 Deuxième moitié de tous les produits 1/Calculer 4
Recomender.update_all(proc=4, scope=[4, 4])
sample_code
#Ajout d'un nouveau produit
new_goods_id = 2100
tag = "book"
Recomender.register(new_goods_id, tag=tag)
#La personne qui a acheté ce produit a également acheté ce produit. Obtenez 5
goods_id = 102
print Recomender.get(goods_id, count=5)
>>> [802, 13, 45, 505, 376]
#Mettre à jour les recommandations pour des produits spécifiques
Recomender.update(goods_id)
#Mettre à jour les recommandations pour tous les produits
Recomender.update_all()
#M. A est des marchandises_Acheter des identifiants
user_id = "dd841cad-b7cf-473b-9006-77823ad5e006"
goods_ids = [102, 102, 103, 104]
Recomender.like(user_id, goods_ids)
recommendation_data_update
#Modifier l'étiquette de produit
new_tag = "computer"
Recomender.change_tag(goods_id, new_tag)
#Supprimer le produit
Recomender.remove(goods_id)
#Supprimer l'utilisateur
Recomender.remove_user(user_id)
Tout ce que vous avez à faire est de le faire ... le faire ... ke .... tsu ......... ke .....
référence
- Filtrage coopératif Toshiyuki Masui
- [Calcul de similarité dans les recommandations La tendance et les contre-mesures #DSIRNLP 4th 2013.9.1](https://speakerdeck.com/komiya_atsushi/rekomendoniokerulei-si-du-ji-suan-sofalseqing-xiang-todui-ce- numéro-dsirnlp-di-4hui-2013-dot-9-1)
- Amazon.com Recommendations Item-to-Item Collaborative Filtering
C'était terminé
Sortie du moteur de recommandation RealTime de filtrage coopératif J'ai hâte de travailler avec vous.
Recommended Posts