Trouver le début de l'avenomics à partir du grossissement NT 1
Pairs Trade utilisant le grossissement NT
Pairs Trade est une méthode de trading bien connue qui utilise deux actions qui se comportent de manière similaire. Lorsqu'il y a une différence entre les deux mouvements, c'est une méthode pour essayer de faire un profit en prenant une position pour combler la différence, et cela se fait également par les hedge funds.
La méthode est expliquée en détail dans la récente lecture "Analyse des données chronologiques qui peuvent être utilisées immédiatement sur le terrain", et théoriquement, il semble que ce soit une prémisse que le trading par paires est établi si les deux ont une relation de cointégration républicaine. Au début, je voulais faire un Back Test pour voir si je pouvais faire un profit. Au Japon, le grossissement NT est utilisé comme un matériau pour le trading de paires, mais comme certains d'entre vous le savent peut-être, le rapport des deux indices, Nikkei225 et Topix, est appelé le grossissement NT (= Nikkei225 / Topix). La question se pose de savoir si la combinaison d'indices est théorique, mais j'ai décidé de la considérer comme une méthode populaire.
Dans le processus d'investigation, j'ai vu un grand changement dans Trend, alors j'y ai pensé sous le titre "Investigating the begin of avenomics".
Graphique historique et nuage de points
Premièrement, l'observation des données chronologiques.

Topix et Nikkei225 sont tous deux des indices boursiers calculés à partir du cours de l'action de la première partie de la Bourse de Tokyo, les mouvements sont donc très similaires. L'échelle de l'axe des y est différente dans le graphique (Nikkei225-gauche, Topix-droite), mais les lignes se chevauchent presque de 2005 à 2009. Vous pouvez également voir la tendance dans laquelle Nikkei225 est passé de la gamme Topix depuis 2010 environ.
Ensuite, regardons le nuage de points.

Dans ce graphique, nous pouvons voir que le tracé se situe au voisinage de deux lignes droites. En considérant cela avec le premier graphique et le graphique historique, on peut déduire que la ligne droite avec la plus petite pente était la tendance de NT au début, mais avec le temps, elle a changé pour devenir la tendance avec la plus grande pente. Sur la base de cette idée, nous avons ensuite effectué une analyse de régression. À propos, le graphique historique du grossissement du NT lui-même est le suivant.

Analyse de régression par modèles statistiques
Cette fois, nous avons effectué une analyse de régression linéaire, mais le module Python a utilisé ** StatsModels **. À partir des données de séries chronologiques de (Topix, Nikkei225), les données ont été extraites en définissant deux intervalles de temps et une régression a été effectuée pour chacun. Les intervalles de temps sont 2005 / B ~ 2008 / E et 2012 / B ~ 2014 / E. Le premier est le temps qui précède le "choc Lehman", et le second est l'ère dite des "Abenomics".
import statsmodels.api as sm
# ... pre-process ...
# Regression Analysis
index_s1 = pd.date_range(start='2005/1/1', end='2008/12/31', freq='B')
x1 = pd.DataFrame(index=index_s1); y1 = pd.DataFrame(index=index_s1)
x1['topix'] = mypair['topix'] # 2005 .. 2008/E
y1['n225'] = mypair['n225']
x1 = sm.add_constant(x1)
model1 = sm.OLS(y1[1:], x1[1:])
mytrend1 = model1.fit()
print mytrend1.summary()
index_s2 = pd.date_range(start='2012/1/1', end='2014/12/31', freq='B')
x2 = pd.DataFrame(index=index_s2); y2 = pd.DataFrame(index=index_s2)
x2['topix'] = mypair['topix'] # 2012 .. 2014/E
y2['n225'] = mypair['n225']
x2 = sm.add_constant(x2)
model2 = sm.OLS(y2[1:], x2[1:])
mytrend2 = model2.fit()
print mytrend2.summary()
# Plot fitted line
plt.figure(figsize=(8,5))
plt.plot(mypair['topix'], mypair['n225'], '.')
plt.plot(x1.iloc[1:,1], mytrend1.fittedvalues, 'r-', lw=1.5, label='2005-2008E')
plt.plot(x2.iloc[1:,1], mytrend2.fittedvalues, 'g-', lw=1.5, label='2012-2014E')
plt.grid(True)
plt.legend(loc=0)
Après avoir défini chaque donnée dans l'objet DataFrame appelé mypair [['topix', 'n225']] dans pandas, la liste ci-dessus a été exécutée.
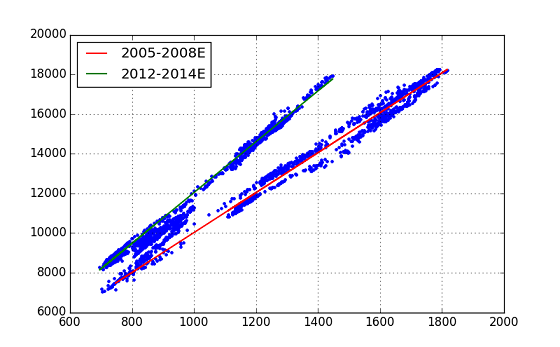
J'ai pu ajuster parfaitement les deux lignes droites. C'est une évaluation de l'analyse de régression, mais elle montre un nombre qui dépasse les attentes. (Les deux calculs de régression donnent de bons résultats, mais un résultat est affiché.)
>>> print mytrend1.summary()
OLS Regression Results (Early period, 2005-2008E)
==============================================================================
Dep. Variable: n225 R-squared: 0.981
Model: OLS Adj. R-squared: 0.981
Method: Least Squares F-statistic: 5.454e+04
Date: Sun, 21 Jun 2015 Prob (F-statistic): 0.00
Time: 17:11:26 Log-Likelihood: -7586.3
No. Observations: 1042 AIC: 1.518e+04
Df Residuals: 1040 BIC: 1.519e+04
Df Model: 1
==============================================================================
coef std err t P>|t| [95.0% Conf. Int.]
------------------------------------------------------------------------------
const -45.0709 62.890 -0.717 0.474 -168.477 78.335
topix 10.0678 0.043 233.545 0.000 9.983 10.152
==============================================================================
Omnibus: 71.316 Durbin-Watson: 0.018
Prob(Omnibus): 0.000 Jarque-Bera (JB): 30.237
Skew: -0.189 Prob(JB): 2.72e-07
Kurtosis: 2.256 Cond. No. 8.42e+03
==============================================================================
Warnings:
[1] The condition number is large, 8.42e+03. This might indicate that there are
strong multicollinearity or other numerical problems.
Le coefficient de détermination R-squired est 0,981, F-stat 5,454e + 04 valeur p 0,00 (!). Comme mentionné ci-dessus, le nombre conditionnel est trop grand du programme, n'est-ce pas étrange? de Un avertissement s'est produit. (Cette fois, je n'ai pas approfondi cet avertissement ... Veuillez me donner des conseils.)
Les équations pour les deux lignes de tendance obtenues à partir de cette analyse de régression (coef) sont les suivantes. Period-1(2005-2008) : n225 = topix x 10.06 - ** 45.07 ** Period-2(2012-2014) : n225 = topix x 12.81 - 773.24
On peut dire que l'indice de grossissement NT est passé de ** 10,06 ** à ** 12,81 **. Cependant, une question est de savoir pourquoi ce grand changement n'est pas visible dans le graphique historique de NT.

Puisque l'interception est passée de la période 1 à la période 2, j'ai également recherché «ntr2» (ligne verte) qui éliminait l'effet, mais il a été dit que NT sautait par étapes (de 10,06 à 12,81). Cela ne semble pas être le cas.
La conclusion de l'analyse à ce jour est que ** "Avenomics a commencé entre 2009 et 2012 (début)" **. Ce n'est pas un résultat net, mais il est naturel (à partir de ce résultat) de penser que cette tendance économique avait déjà commencé, au moins en décembre 2012, lorsque le Premier ministre Abe a pris ses fonctions de Premier ministre pour le deuxième mandat.
(Comme la conclusion n'est pas claire, j'ai fait une classification en utilisant ensuite scicit-learn. Voir l'article "2".)
Les références
- "Analyse de données chronologiques utilisables immédiatement sur le terrain" (Daisuke Yokouchi (Auteur), Yoshimitsu Aoki (Auteur), Revue technique) http://gihyo.jp/book/2014/978-4-7741-6301-7
- "Python for Finance": (O'reilly Media) http://shop.oreilly.com/product/0636920032441.do --pandas document http://pandas.pydata.org/pandas-docs/stable/index.html
- Document StatsModels http://statsmodels.sourceforge.net/stable/
Recommended Posts