Grattage de table avec belle soupe
introduction
Les tableaux HTML peuvent être récupérés en quelques lignes à l'aide de pd.read_html () de pandas, mais cette fois, j'aimerais vous montrer comment gratter sans utiliser read_html ().
Préparation
Installez Beautiful Soup. (Cette fois, nous utiliserons également des pandas pour créer une trame de données, alors installez-la comme il convient.)
$ pip install beautifulsoup4 # or conda install
politique
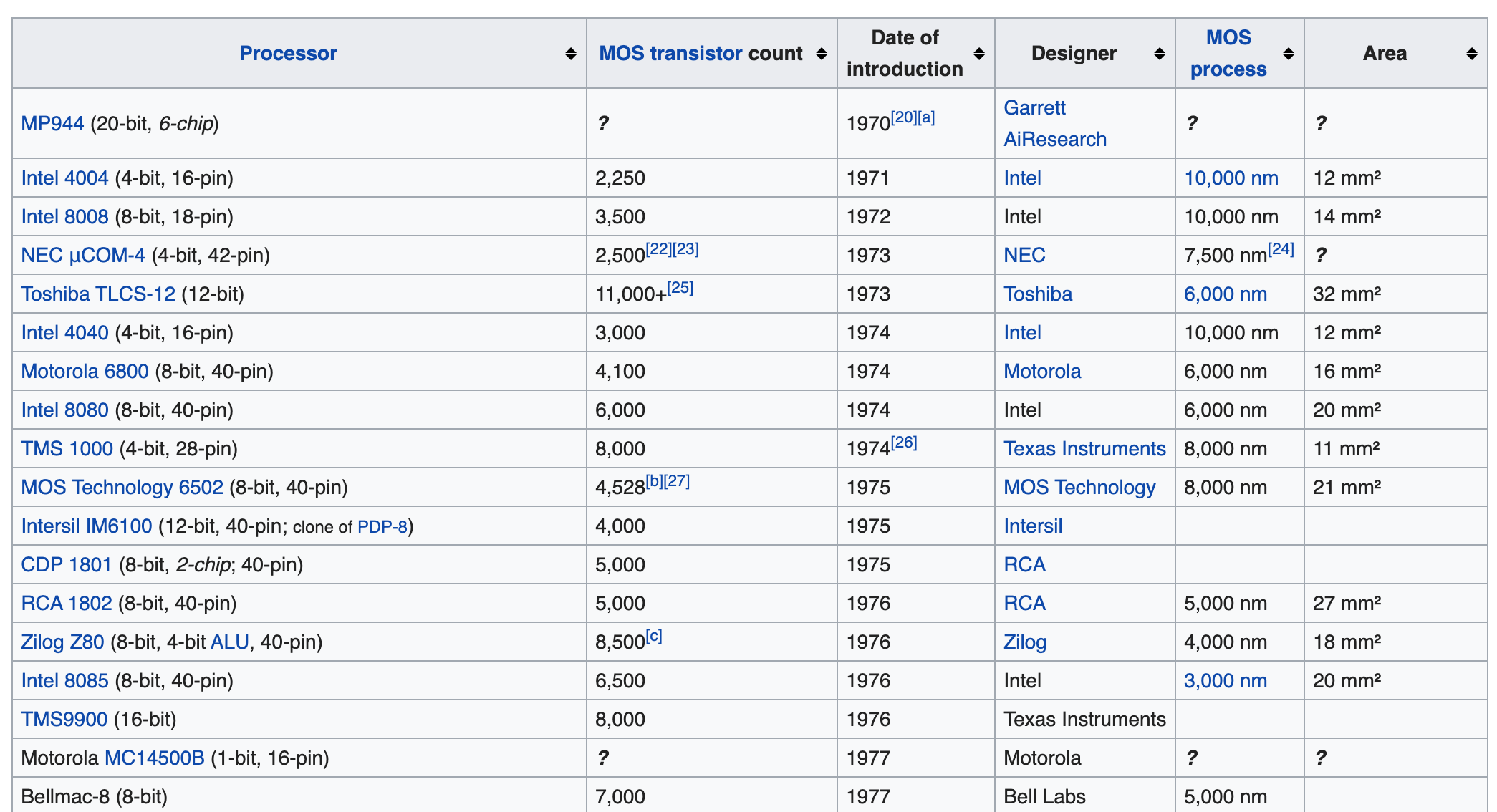
Cette fois, à titre d'exemple, obtenons la liste suivante des processeurs à partir de cette page wikipedia.
référence
Ici, pour référence, je voudrais montrer la méthode lors de l'utilisation de la méthode super-facile pd.read_html ().
import pandas as pd
url = 'https://en.wikipedia.org/wiki/Transistor_count' #URL de la page Web cible
dfs = pd.read_html(url) #Si la page Web comporte plusieurs tables, elles seront stockées au format dfs au format liste
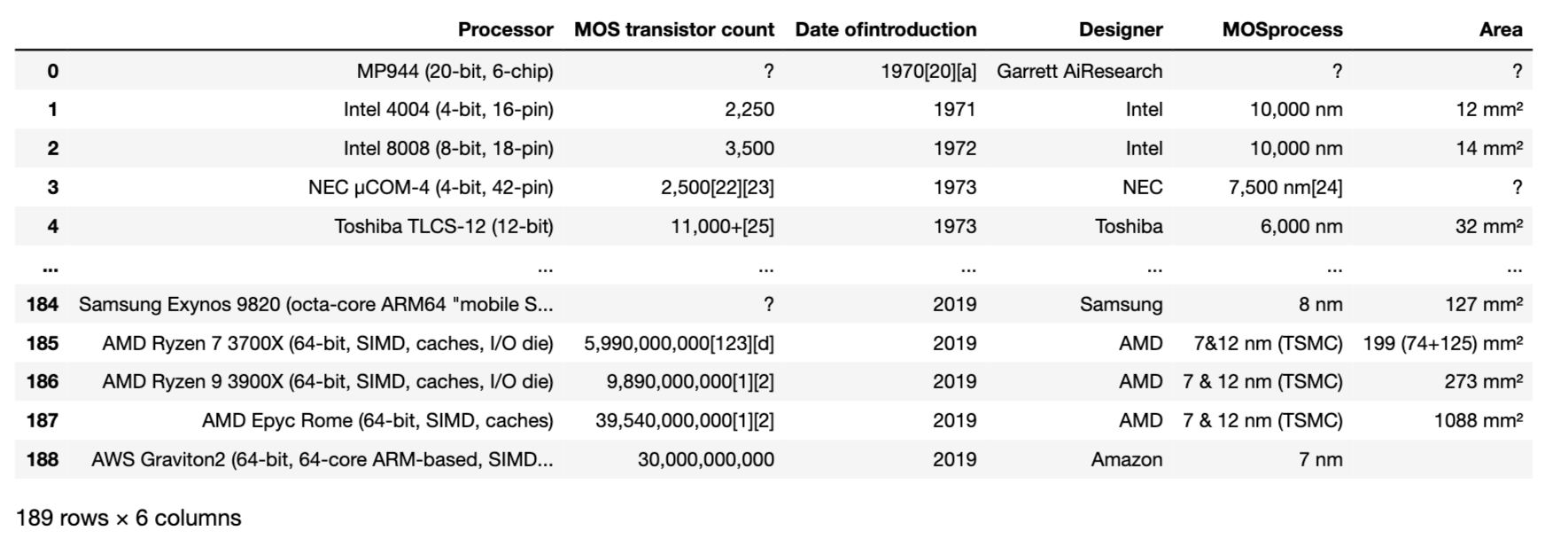
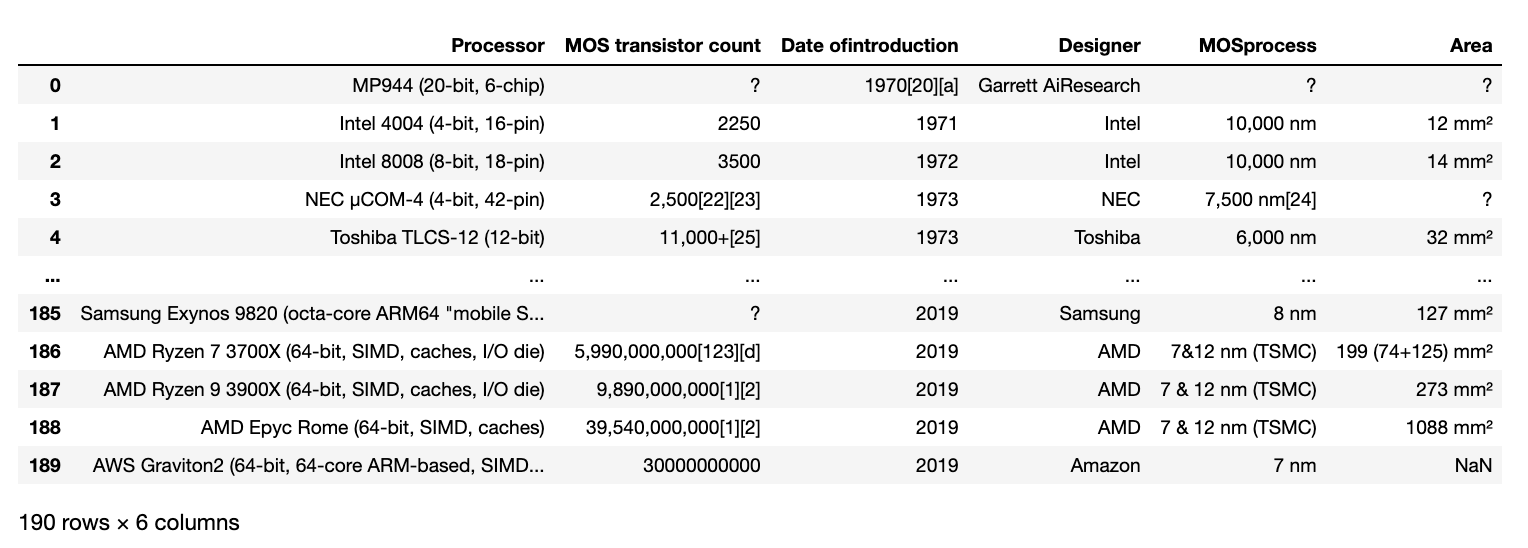
Cette fois, il semble que la table cible soit stockée dans le premier index de dfs, donc sortons dfs [1](dfs [0] stocke une table d'une autre classe).
dfs[1]
Le résultat de sortie ressemble à l'image ci-dessous et vous pouvez certainement le gratter.
Aperçu
Avant de gratter une table avec BeautifulSoup, jetons un coup d'œil à la page Web sur laquelle elle est grattée. Passons à la page wikipedia à partir du lien ci-dessus et ouvrons les outils de développement (dans le cas de chrome, vous pouvez l'afficher en faisant un clic droit sur le tableau ⇒ inspecter. Vous pouvez également sélectionner option + commande + I). En regardant la source html de la page avec les outils de développement, la table cible se trouve sous la balise \
| (données de la cellule du tableau) Vous pouvez voir qu'il a une structure hiérarchique (non visible dans l'image ci-dessous, mais il y a une balise \ | dans la hiérarchie ci-dessous \ au même niveau que la balise \ |
|---|
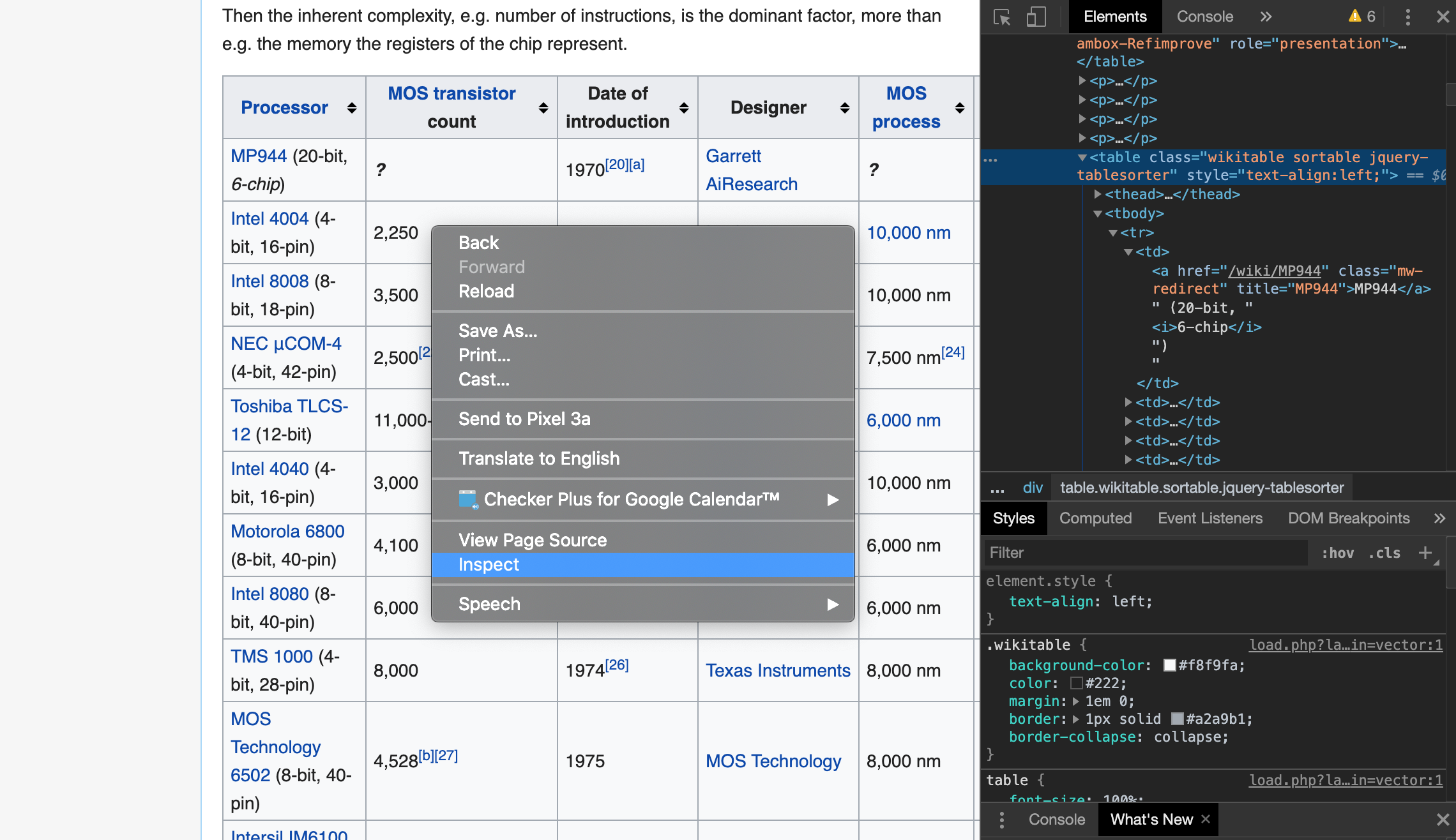
| à l'intérieur de la balise \ |
|---|
| à l'intérieur de la balise \ |
qui sont les composants d'en-tête de la 0ème ligne du tableau et extrait uniquement le composant de texte (v.text).
Le résultat est le suivant, mais \ n indiquant qu'un saut de ligne est un obstacle.
|