[Classification des phrases] J'ai essayé différentes méthodes de mise en commun des réseaux de neurones convolutifs
introduction
Dans la classification des phrases, le pooling max est souvent utilisé pour les réseaux de neurones convolutifs (CNN), mais je me suis demandé si d'autres méthodes de mise en commun seraient inutiles.
Les données
- Code source
- Mis en œuvre avec Chainer.
- base de données
- J'utilise Stanford Sentiment Treebank (SST). -Vous pouvez le télécharger sur ici.
- Expression distribuée par mot
- J'utilise le modèle entraîné de word2vec (GoogleNews-vectors-negative300.bin.gz). Vous pouvez le télécharger à ici.
Qu'est-ce que la classification des phrases?
La tâche d'attribution d'une étiquette de déclaration. Par exemple, dans le SST ci-dessus, chaque phrase a des étiquettes positives et négatives.
[positif]Elle a une bonne personnalité et, surtout, un bon style.
[Négatif]L'animation de cette saison est médiocre.
SST est en anglais, mais l'exemple japonais ressemble à ceci. En plus des négatifs positifs, il existe également des ensembles de données qui peuvent être utilisés pour aborder des sujets tels que le sport et la politique.
Modèle de réseau
Basé sur Convolutional Neural Networks for Sentence Classification [Kim, 2014]. Dans le domaine du traitement du langage naturel, cet article est souvent cité quand on parle de CNN.

couche de pooling
La partie de pooling Max-over-time (pooling max) dans la figure ci-dessus est la couche de pooling. Cette fois, l'histoire ici. En plus de la mise en commun maximale, CNN peut également utiliser la mise en commun moyenne. max pooling récupère la plus grande valeur de la carte des caractéristiques, tandis que la mise en commun moyenne récupère la moyenne des valeurs de la carte des caractéristiques. Cet article a déjà signalé que la mise en commun maximale avait un taux de précision plus élevé pour la classification de texte dans certains ensembles de données que la mise en commun moyenne.
Rembourrage
Alors la mise en commun maximale est bien, mais Cependant, dans le traitement du langage naturel, les longueurs des phrases d'entrée ne sont pas les mêmes, donc un processus appelé remplissage est nécessaire pour uniformiser la longueur des phrases d'entrée. Par conséquent, à proprement parler, la longueur de la phrase n'est pas moyennée, mais la longueur de phrase maximale de l'entrée est moyennée. (Peut-être que le papier présenté ci-dessus est aussi ...) Dans ce cas, je me suis demandé si la version de mise en commun moyenne n'était pas la version qui faisait la moyenne de la longueur de la carte de caractéristiques (longueur maximale de la phrase), mais la version qui faisait la moyenne de la longueur de la phrase.
(Exemple.)

↑ Le résultat de la convolution \
Code (partie réseau)
cnn_average.py
class CNN_average(Chain):
def __init__(self, vocab_size, embedding_size, input_channel, output_channel_1, output_channel_2, output_channel_3, k1size, k2size, k3size, pooling_units, output_size=args.classtype, train=True):
super(CNN_average, self).__init__(
w2e = L.EmbedID(vocab_size, embedding_size),
conv1 = L.Convolution2D(input_channel, output_channel_1, (k1size, embedding_size)),
conv2 = L.Convolution2D(input_channel, output_channel_2, (k2size, embedding_size)),
conv3 = L.Convolution2D(input_channel, output_channel_3, (k3size, embedding_size)),
l1 = L.Linear(pooling_units, output_size),
)
self.output_size = output_size
self.train = train
self.embedding_size = embedding_size
self.ignore_label = 0
self.w2e.W.data[self.ignore_label] = 0
self.w2e.W.data[1] = 0 #Non-caractère
self.input_channel = input_channel
def initialize_embeddings(self, word2id):
#w_vector = word2vec.Word2Vec.load_word2vec_format('./vector/glove.840B.300d.txt', binary=False) # GloVe
w_vector = word2vec.Word2Vec.load_word2vec_format('./vector/GoogleNews-vectors-negative300.bin', binary=True) # word2vec
for word, id in sorted(word2id.items(), key=lambda x:x[1])[1:]:
if word in w_vector:
self.w2e.W.data[id] = w_vector[word]
else:
self.w2e.W.data[id] = np.reshape(np.random.uniform(-0.25,0.25,self.embedding_size),(self.embedding_size,))
def __call__(self, x):
h_list = list()
ox = copy.copy(x)
if args.gpu != -1:
ox.to_gpu()
b = x.shape[0]
emp_array = xp.array([len(xp.where(x[i].data != 0)[0]) for i in range(b)], dtype=xp.float32).reshape(b,1,1,1)
x = xp.array(x.data)
x = F.tanh(self.w2e(x))
b, max_len, w = x.shape # batch_size, max_len, embedding_size
x = F.reshape(x, (b, self.input_channel, max_len, w))
c1 = self.conv1(x)
b, outputC, fixed_len, _ = c1.shape
tf = self.set_tfs(ox, b, outputC, fixed_len) # true&flase
h1 = self.average_pooling(F.relu(c1), b, outputC, fixed_len, tf, emp_array)
h1 = F.reshape(h1, (b, outputC))
h_list.append(h1)
c2 = self.conv2(x)
b, outputC, fixed_len, _ = c2.shape
tf = self.set_tfs(ox, b, outputC, fixed_len) # true&flase
h2 = self.average_pooling(F.relu(c2), b, outputC, fixed_len, tf, emp_array)
h2 = F.reshape(h2, (b, outputC))
h_list.append(h2)
c3 = self.conv3(x)
b, outputC, fixed_len, _ = c3.shape
tf = self.set_tfs(ox, b, outputC, fixed_len) # true&flase
h3 = self.average_pooling(F.relu(c3), b, outputC, fixed_len, tf, emp_array)
h3 = F.reshape(h3, (b, outputC))
h_list.append(h3)
h4 = F.concat(h_list)
y = self.l1(F.dropout(h4, train=self.train))
return y
def set_tfs(self, x, b, outputC, fixed_len):
TF = Variable(x[:,:fixed_len].data != 0, volatile='auto')
TF = F.reshape(TF, (b, 1, fixed_len, 1))
TF = F.broadcast_to(TF, (b, outputC, fixed_len, 1))
return TF
def average_pooling(self, c, b, outputC, fixed_len, tf, emp_array):
emp_array = F.broadcast_to(emp_array, (b, outputC, 1, 1))
masked_c = F.where(tf, c, Variable(xp.zeros((b, outputC, fixed_len, 1)).astype(xp.float32), volatile='auto'))
sum_c = F.sum(masked_c, axis=2)
p = F.reshape(sum_c, (b, outputC, 1, 1)) / emp_array
return p
Contenu de l'expérience
Comparez les quatre méthodes de regroupement suivantes en utilisant le Stanford Sentiment Treebank (SST) comme ensemble de données
- max pooling --un pooling moyen (1 / max len) ← Celui qui prend la moyenne avec la longueur maximale de la phrase --un pooling moyen (1 / envoyé len) ← Celui qui prend la moyenne pour chaque longueur de phrase --Attention pooling ← J'ai essayé d'utiliser le mécanisme Attention pour la couche de pooling. Pour plus d'informations ici
Résultat expérimental
| pooling method | SST-2 | SST-5 |
|---|---|---|
| max | 86.3 (0.27) | 46.5 (1.13) |
| average (1/max len) | 84.6 (0.38) | 46.0 (0.69) |
| average (1/sent len) | 86.6 (0.51) | 47.3 (0.44) |
| attention | 86.0 (0.20) | 47.2 (0.37) |
La valeur est la moyenne après 5 essais et la valeur entre () est l'écart type. SST-5 est une tâche pour classer 5 valeurs de très négatives, négatives, neutres, positives et très positives, et SST-2 est une tâche pour classer positive et négative à l'exclusion du neutre.
max pooling Cela tremble un peu, et le résultat est que le pooling moyen, qui est en moyenne par la longueur de la phrase, est le meilleur. La mise en commun moyenne, qui prend la moyenne de la longueur maximale de la peine, est certainement plus faible que la mise en commun maximale. ..
Visualisez l'état de la carte des caractéristiques
[very positive] I admired this work a lot.
J'ai essayé de vérifier comment la carte des fonctionnalités de CNN de mise en commun maximale et de mise en commun moyenne (1 / len envoyé) CNN est apprise pour la phrase.
admired(Admirer)Un mot qui exprime le sens positif et le soulignea lotEst le point de prédiction.
La taille de la fenêtre de CNN ici est de 3. Le nombre de cartes de caractéristiques est de 100.
Tout d'abord, la mise en commun maximale. .. .. Ce type confond cette phrase avec `` [positif] '' et le prédit. Je suis désolé.

Puisqu'il s'agit d'un pooling maximal, la partie la plus sombre de chaque carte d'entités sera extraite après cela.
admired this workIl existe de nombreuses cartes d'entités dont la partie de est extraite.
admiré ce travail et beaucoup. <PAD>Est extrait dans une carte des caractéristiques distincte.
Ensuite, la mise en commun moyenne. .. .. Ce mec répond correctement `` [très positif] ''. Garçon mignon.
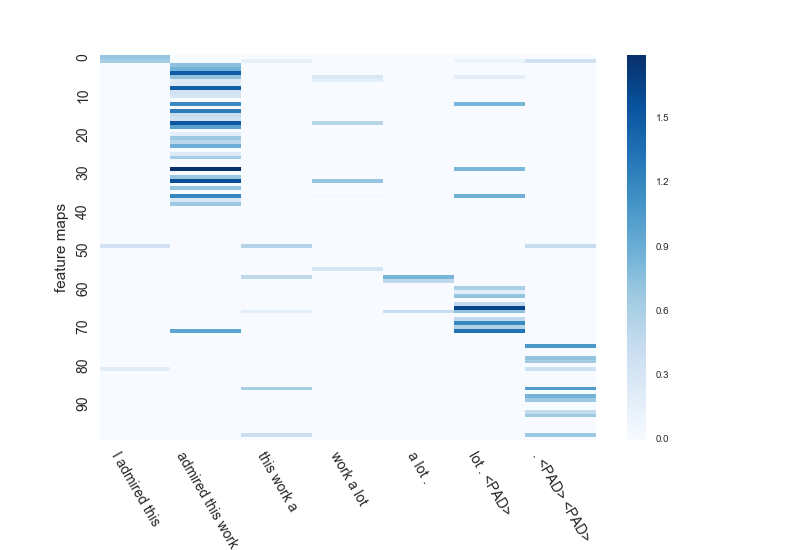
Puisqu'il s'agit d'une mise en commun moyenne, vous pouvez considérer plusieurs éléments tels que le deuxième et le troisième en plus de la partie la plus sombre.
#### **`admiré ce travail et beaucoup. <PAD>Vous pouvez également voir une carte des caractéristiques qui extrait.`**
``` <PAD>Vous pouvez également voir une carte des caractéristiques qui extrait.
Il semble que les résultats d'apprentissage soient assez différents même avec le même CNN entre le pooling max, qui n'utilise que la valeur maximale, et le pooling moyen, qui utilise toutes les valeurs pour obtenir la valeur moyenne.
# Considération
Alors que la mise en commun maximale ne peut extraire qu'une seule entité d'une seule carte
La mise en commun moyenne et la mise en commun de l'attention peuvent extraire plusieurs identités d'une même carte de caractéristiques.
Dans l'exemple ci-dessus, il est possible de considérer ```admired``` et `` a lot``` qui sont un peu séparés les uns des autres dans une même carte de caractéristiques en même temps. Je me demande si c'était bon. .. ..
# en conclusion
Dans le traitement du langage naturel, la mise en commun maximale est souvent utilisée, mais il s'est avéré que la mise en commun moyenne peut également être utilisée de manière inattendue si elle est correctement divisée par la longueur de la phrase.
En fait, je pense que la mise en commun moyenne est meilleure intuitivement.
Cela prend plus de temps à calculer que max, mais cela ne me dérange pas car CNN lui-même est rapide. (C'était beaucoup plus rapide que RNN en utilisant LSTM.)
Quand je fais CNN à partir de maintenant, j'aimerais essayer la mise en commun moyenne en même temps.
Recommended Posts