J'ai essayé la classification d'image d'AutoGluon
introduction
J'ai essayé la classification d'image d'AutoGluon (https://autogluon.mxnet.io/index.html) qui est une bibliothèque AutoML dans l'environnement de Google Colaboratory. Fondamentalement, le contenu est ajouté au contenu officiel de démarrage rapide.
environnement
Il est réalisé au Google Colaboratory.
Courir
Paramètres de Google Colab
Pour la classification des images, le modèle Deep Learning est utilisé, configurez-le pour utiliser le GPU (voir la figure ci-dessous).
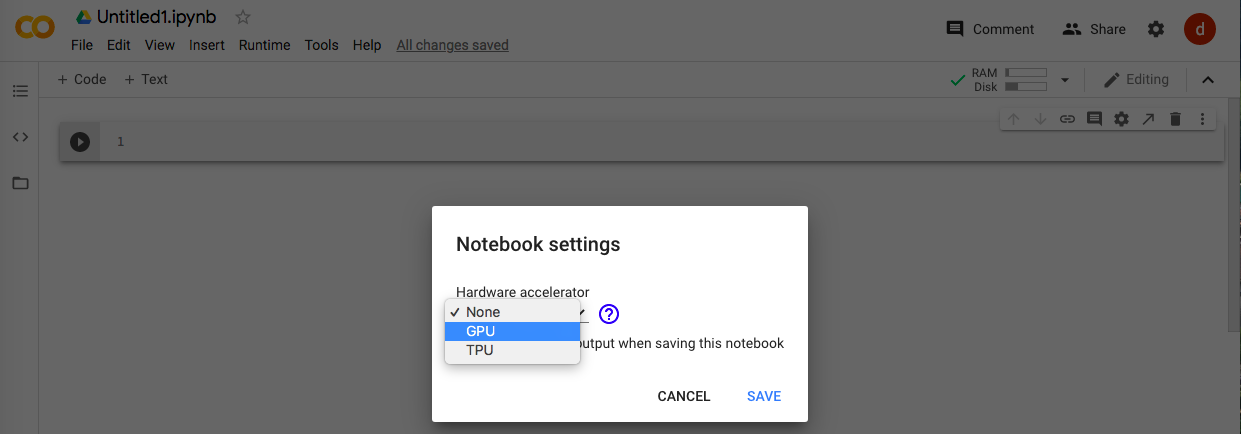
Installation de la bibliothèque avec Google Colab
Avec uniquement les paramètres ci-dessus, lorsque j'exécute AutoGluon, j'obtiens une erreur s'il n'y a pas de GPU. Par conséquent, je l'ai installé en référence à cet article (https://qiita.com/tasmas/items/22cf80a4be80f7ad458e). Il n'y a pas eu d'erreurs particulières et j'ai pu bien le faire.
!pip uninstall -y mkl
!pip install --upgrade mxnet-cu100
!pip install autogluon
!pip install -U ipykernel
Redémarrez le runtime après l'exécution.
Exécutez Auto Gluon
Suivez le Quick Start officiel. https://autogluon.mxnet.io/tutorials/image_classification/beginner.html
Tout d'abord, importez la bibliothèque et téléchargez les données. Les données sont les données d'image de Shopee-IET qui se trouvaient à Kaggle, et les images telles que les vêtements sont classées en quatre catégories, «Pantalons bébé», «Chemise bébé», «Chaussures décontractées pour femmes» et «Femmes en haut». Cependant, le lien vers Kaggle sur la page Auto Gluon était rompu. (Kaggle a également une page, mais je n'ai pas pu trouver les données à la fois. Elle a peut-être été supprimée car ce sont les données de l'ancien concours.)
import autogluon as ag
from autogluon import ImageClassification as task
filename = ag.download('https://autogluon.s3.amazonaws.com/datasets/shopee-iet.zip')
ag.unzip(filename)
Chargez respectivement les données d'entraînement et les données d'évaluation.
train_dataset = task.Dataset('data/train')
test_dataset = task.Dataset('data/test', train=False)
«Ajustez» simplement les données d'entraînement pour créer un modèle d'identification d'image. Incroyablement facile ...
classifier = task.fit(train_dataset,
epochs=5,
ngpus_per_trial=1,
verbose=False)
Voici le résultat de sortie standard au moment de l'ajustement. Apparemment, j'apporte ResNet 50. Enfin, cela vous donne également une courbe d'apprentissage. Cette fois, j'apprenais seulement 5 époques, donc cela n'a pris que quelques minutes.
scheduler_options: Key 'training_history_callback_delta_secs': Imputing default value 60
scheduler_options: Key 'delay_get_config': Imputing default value True
Starting Experiments
Num of Finished Tasks is 0
Num of Pending Tasks is 2
scheduler: FIFOScheduler(
DistributedResourceManager{
(Remote: Remote REMOTE_ID: 0,
<Remote: 'inproc://172.28.0.2/371/1' processes=1 threads=2, memory=13.65 GB>, Resource: NodeResourceManager(2 CPUs, 1 GPUs))
})
100%
2/2 [03:58<00:00, 119.19s/it]
Model file not found. Downloading.
Downloading /root/.mxnet/models/resnet50_v1b-0ecdba34.zip from https://apache-mxnet.s3-accelerate.dualstack.amazonaws.com/gluon/models/resnet50_v1b-0ecdba34.zip...
100%|██████████| 55344/55344 [00:01<00:00, 45529.30KB/s]
[Epoch 5] Validation: 0.456: 100%
5/5 [01:06<00:00, 13.29s/it]
Saving Training Curve in checkpoint/plot_training_curves.png
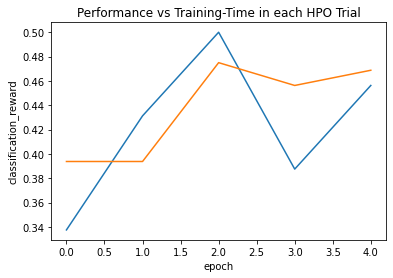
La précision au moment de l'apprentissage était d'environ 50%. Je pense que cela ne peut pas être aidé avec les paramètres actuels.
print('Top-1 val acc: %.3f' % classifier.results['best_reward'])
# Top-1 val acc: 0.469
Faisons une prédiction pour certaines données d'image. Si vous prédisez les données de "Baby Shirt", il est certainement classé comme "Baby Shirt".
image = 'data/test/BabyShirt/BabyShirt_323.jpg'
ind, prob, _ = classifier.predict(image, plot=True)
print('The input picture is classified as [%s], with probability %.2f.' %
(train_dataset.init().classes[ind.asscalar()], prob.asscalar()))
# The input picture is classified as [BabyShirt], with probability 0.61.
Lors du calcul de la précision à l'aide des données d'évaluation, elle était d'environ 70%.
test_acc = classifier.evaluate(test_dataset)
print('Top-1 test acc: %.3f' % test_acc)
# Top-1 test acc: 0.703
C'est vraiment pratique car vous pouvez construire un modèle en un clin d'œil comme celui-ci, tout en J'ai senti que la fonction d'ajustement était vraiment importante, alors j'ai fait quelques recherches.
Un peu de recherche sur l'ajustement
Arguments de la fonction fit
Cette fois, j'ai utilisé la fonction d'ajustement dans l'identification d'image. Le code source (https://github.com/awslabs/autogluon/blob/15c105b0f1d8bdbebc86bd7e7a3a1b71e83e82b9/autogluon/task/image_classification/image_classification.py#L63) est extrait ci-dessous.
@staticmethod
def fit(dataset,
net=Categorical('ResNet50_v1b', 'ResNet18_v1b'),
optimizer=NAG(
learning_rate=Real(1e-3, 1e-2, log=True),
wd=Real(1e-4, 1e-3, log=True),
multi_precision=False
),
loss=SoftmaxCrossEntropyLoss(),
split_ratio=0.8,
batch_size=64,
input_size=224,
epochs=20,
final_fit_epochs=None,
ensemble=1,
metric='accuracy',
nthreads_per_trial=60,
ngpus_per_trial=1,
hybridize=True,
scheduler_options=None,
search_strategy='random',
search_options=None,
plot_results=False,
verbose=False,
num_trials=None,
time_limits=None,
resume=False,
output_directory='checkpoint/',
visualizer='none',
dist_ip_addrs=None,
auto_search=True,
lr_config=Dict(
lr_mode='cosine',
lr_decay=0.1,
lr_decay_period=0,
lr_decay_epoch='40,80',
warmup_lr=0.0,
warmup_epochs=0
),
tricks=Dict(
last_gamma=False,
use_pretrained=True,
use_se=False,
mixup=False,
mixup_alpha=0.2,
mixup_off_epoch=0,
label_smoothing=False,
no_wd=False,
teacher_name=None,
temperature=20.0,
hard_weight=0.5,
batch_norm=False,
use_gn=False),
**kwargs):
Parce que ResNet50 a été appelé par défaut dans `` net '' qui est l'un des arguments Vous pouvez voir qu'il a été appelé plus tôt. Ainsi, lorsque vous souhaitez essayer un autre modèle, la question est de savoir quel modèle vous pouvez choisir.
À propos du modèle à appeler
Comme décrit sur la page officielle (https://autogluon.mxnet.io/tutorials/image_classification/hpo.html), glooncv model_zoo (https://gluon-cv.mxnet.io/model_zoo/classification.html) ) Semble pouvoir récupérer le modèle. Les modèles enregistrés au 4 septembre 2020 sont indiqués dans la figure ci-dessous.
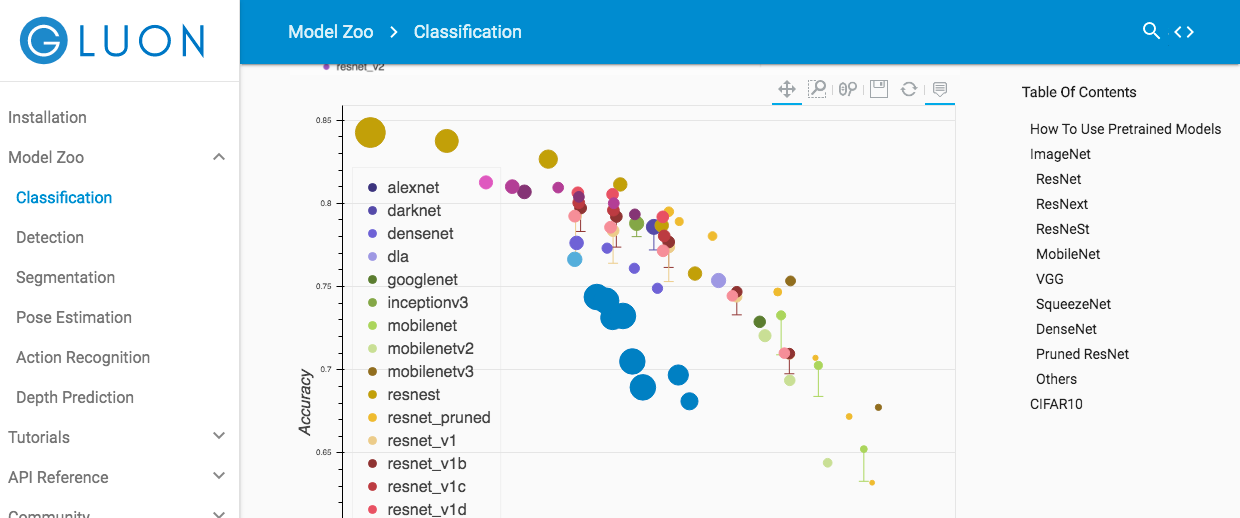
En plus de ResNet mentionné ci-dessus, nous avons constaté qu'il existe des modèles formés tels que MobileNet et VGG. Les modèles sont déjà affichés par ordre de précision, donc je pense que c'est facile à choisir.
À propos de mon propre modèle
D'un autre côté, si vous souhaitez créer votre propre réseau de neurones, il semble que vous puissiez le créer en utilisant `` mxnet '' qui est utilisé dans la base d'AutoGluon.
https://github.com/awslabs/autogluon/blob/15c105b0f1d8bdbebc86bd7e7a3a1b71e83e82b9/autogluon/task/image_classification/nets.py#L52
def mnist_net():
mnist_net = gluon.nn.Sequential()
mnist_net.add(ResUnit(1, 8, hidden_channels=8, kernel=3, stride=2))
mnist_net.add(ResUnit(8, 8, hidden_channels=8, kernel=5, stride=2))
mnist_net.add(ResUnit(8, 16, hidden_channels=8, kernel=3, stride=2))
mnist_net.add(nn.GlobalAvgPool2D())
mnist_net.add(nn.Flatten())
mnist_net.add(nn.Activation('relu'))
mnist_net.add(nn.Dense(10, in_units=16))
return mnist_net
De plus, vous pouvez également définir `metric et `ʻoptimiser```, donc j'ai pensé que ce serait facile de faire du Deep Learning.
à la fin
Dans le cas de l'analyse d'image, il y avait une image de logique de calcul de bâtiment utilisant Tensorflow, keras, etc., mais quand il devient possible de construire un modèle si facilement, il est appliqué au traitement des données d'image (suppression du bruit, Augmentation, etc.). Je pensais que ce serait très bien parce que le temps que je pourrais passer augmenterait relativement.
Étant donné qu'AutoGluon est basé sur la bibliothèque (ou plateforme) de Deep Learning mxnet, j'étais convaincu qu'AutoGluon prend également en charge le traitement du langage naturel (NLP). Au contraire, il semble que Auto Gluon-Tabular soit un élément alpha plus.
Étant donné qu'AWS prend en charge à la fois AutoGluon et mxnet, j'aimerais finir par penser que les bibliothèques ici sont utilisées pour les services AWS ML.
Recommended Posts