[SWIFT] Exécutez un modèle simple réalisé avec Keras sur iOS à l'aide de CoreML
Afin de comprendre les outils CoreML, j'ai pensé que ce serait bien si je pouvais utiliser un modèle simple que j'ai créé et changer le modèle à ma guise. J'expliquerai la procédure.
Quoi faire
Étant donné deux ensembles de nombres, créez un modèle qui prédit le résultat de leur ajout.
<Fig. 1>
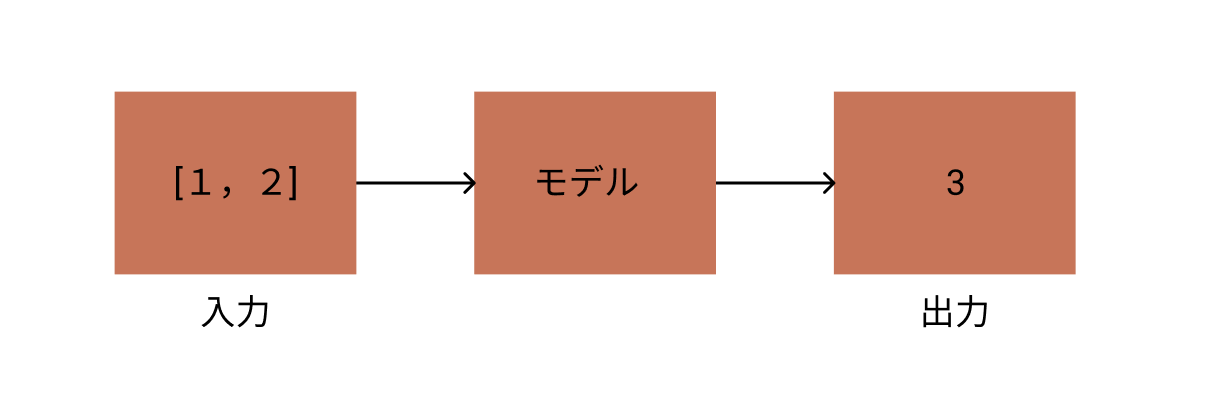
procédure
La version complète de ce code est stockée ici. https://gist.github.com/TokyoYoshida/bab3d0396c05afce445852d2ae224cf4
** 1. Démarrez Google Colab **
Accédez au site Google Colaboratory. Google Colaboratory
** 2. Installez et importez ce dont vous avez besoin **
Tensorflow et keras sont également installés selon la version de coremltools.
notebook
!pip install tensorflow==1.14.0
!pip install -U coremltools
!pip install keras==2.2.4
Importez ensuite les modules requis.
notebook
from keras.models import Sequential
from keras.layers import Dense, Activation
import numpy as np
import math
from keras.utils import np_utils
import keras
** 3. Préparez-vous pour Tensorboard **
Des informations sur le modèle peuvent être requises lors de la conversion avec les outils CoreML. Pour ce faire, vous devez comprendre le modèle dans une certaine mesure, mais soyez prêt à le visualiser avec Tensorboard, car cela vous aidera à comprendre les informations du modèle. (Je crée moi-même un modèle cette fois, donc je n'ai pas besoin d'informations sur le modèle)
référence: [TF] Comment utiliser Tensorboard de Keras
notebook
!mkdir logs
tb_cb = keras.callbacks.TensorBoard(log_dir='./logs', histogram_freq=0, batch_size=32, write_graph=True, write_grads=False, write_images=False, embeddings_freq=0, embeddings_layer_names=None, embeddings_metadata=None)
cbks = [tb_cb]
** 4. Faire un modèle et former **
Saisissez des données pour créer 10 000 combinaisons de deux entiers. Puisque les données de l'enseignant sont traitées cette fois comme un problème de classification, il s'agira de 18 tableaux [0,1,2,3,4 ... 17,18]. (Parce que 9 + 9 = 18 est la valeur maximale en tant que combinaison de réponses) Dans ce tableau, seule la partie réponse contient 1 et les autres parties contiennent 0. Cette méthode d'expression est appelée One-hot expression.
<Fig. 2>
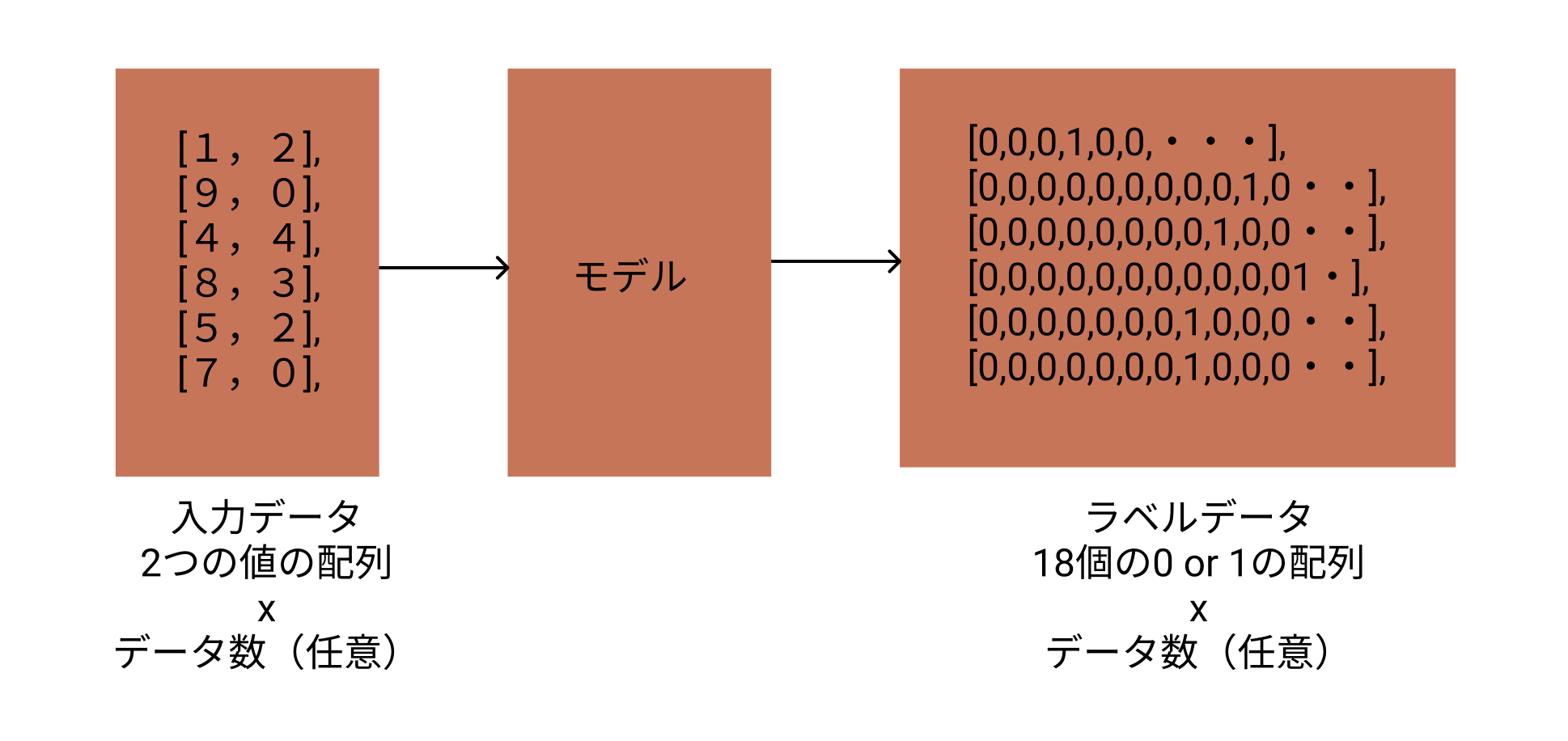
Le modèle utilise trois couches simples entièrement connectées et la fonction d'activation utilise softmax.
référence: Ajout d'un chiffre avec Keras
notebook
x = np.random.randint(0, 10, (10000,2))
y = np_utils.to_categorical(np.sum(x, axis=1))
model = Sequential()
model.add(Dense(512, activation='relu', input_dim=2))
model.add(Dense(256, activation='relu'))
model.add(Dense(y.shape[1]))
model.add(Activation("softmax"))
model.compile('rmsprop',
'categorical_crossentropy',
metrics=['accuracy'])
train_rate = 0.7
train_len = math.floor(len(x) * train_rate)
trainx = x[0:train_len]
trainy = y[0:train_len]
testx = x[train_len:]
testy = y[train_len:]
history = model.fit(trainx, trainy,
batch_size=128,
epochs=100,
verbose=1,
callbacks=cbks,
validation_data=(testx, testy))
Exécutez le code ci-dessus pour commencer à apprendre.
notebook
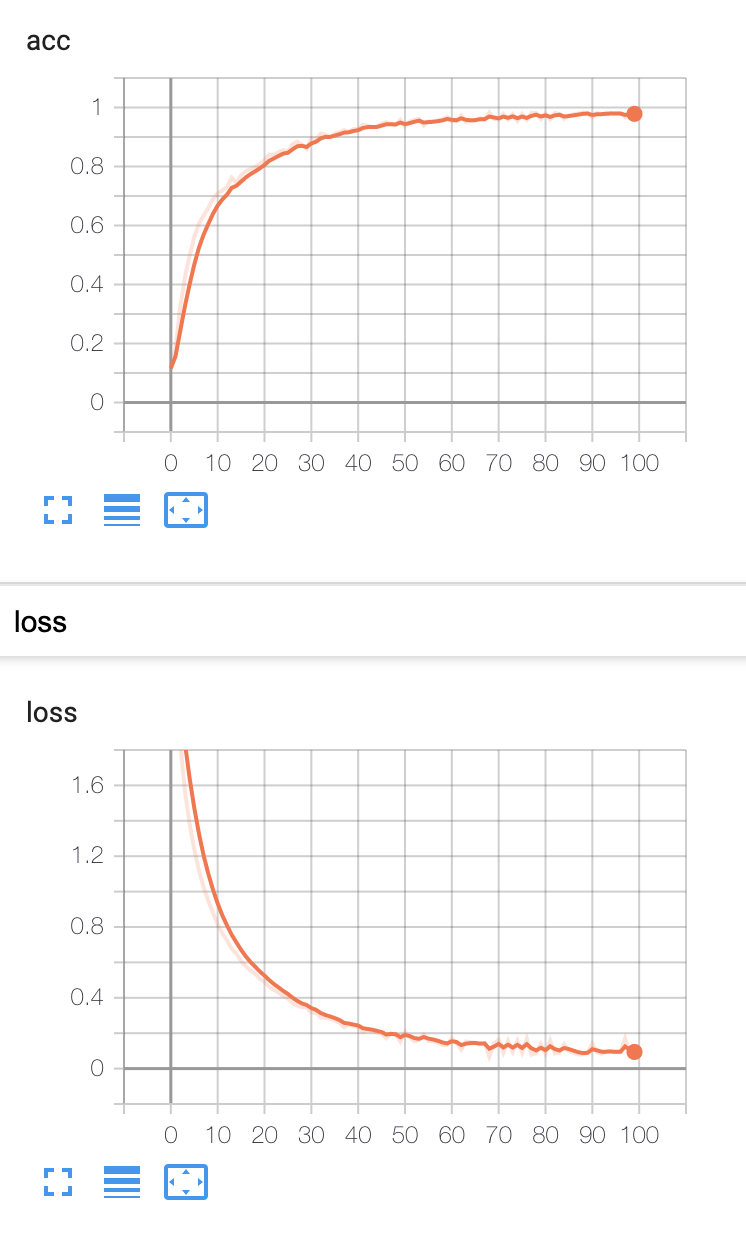
7000/7000 [==============================] - 0s 54us/step - loss: 0.1705 - acc: 0.9677 - val_loss: 0.0172 - val_acc: 1.0000
Epoch 99/100
7000/7000 [==============================] - 0s 53us/step - loss: 0.0804 - acc: 0.9804 - val_loss: 0.0069 - val_acc: 1.0000
Epoch 100/100
7000/7000 [==============================] - 0s 57us/step - loss: 0.0745 - acc: 0.9806 - val_loss: 0.0062 - val_acc: 1.0000
Bien que les données d'apprentissage et les données de test soient séparées cette fois, le résultat de la vérification (val_acc) par les données de test n'est pas très fiable car il y a en fait un brouillard.
** 5. Essayez de visualiser avec Tensorboard **
Chargez et exécutez Tensroboard.
Pour une raison quelconque, si vous ne désinstallez pas tensorboard-plugin-wit, une erreur se produira, alors désinstallez-le.
notebook
%load_ext tensorboard
!pip uninstall tensorboard-plugin-wit
%tensorboard --logdir ./logs
Situation d'apprentissage
Informations graphiques
Les couches sont entrées du bas (dense_1), la sortie du haut (activation_1), et ainsi de suite, du bas vers le haut.
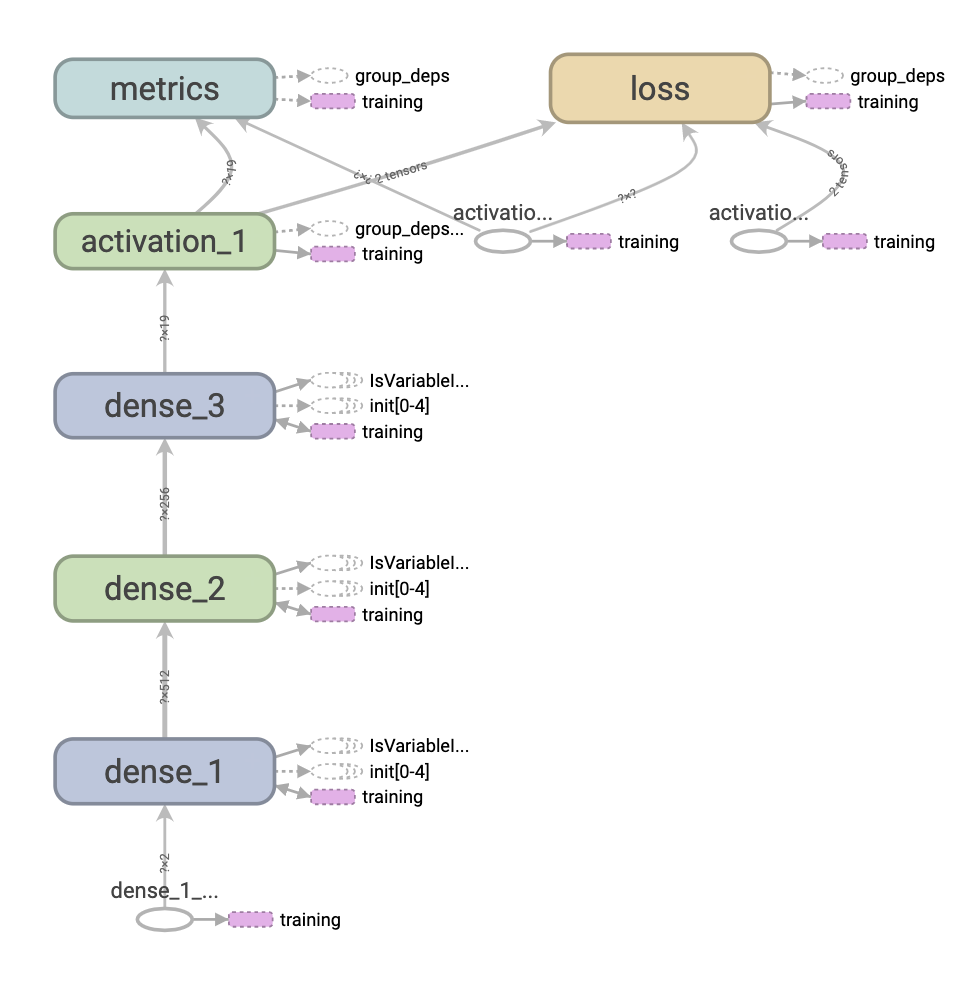
Regardons le côté entrée (dense_1).
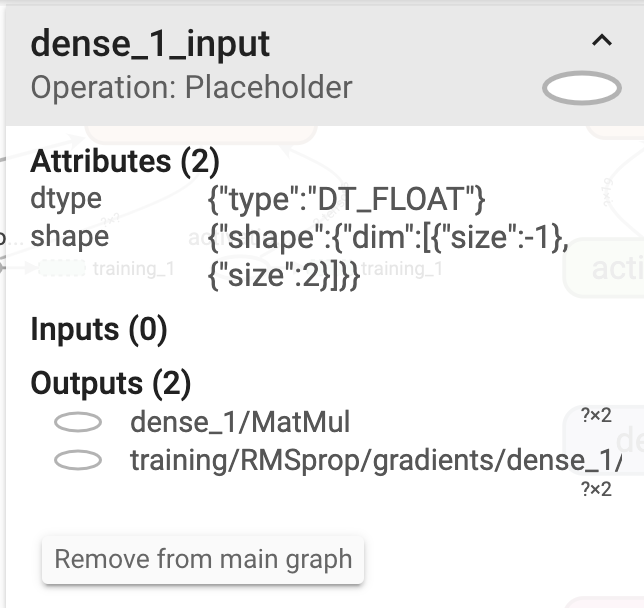
Vous pouvez voir que l'opération est un espace réservé et les données sont saisies ici. dtype est DT_FLOAT. Les données cette fois sont constituées d'entiers, mais elles peuvent également gérer des données avec des fractions ou moins. La forme est {"dim": {"size": -1}, "size": 2]}. En d'autres termes, c'est la forme de (-1,2). -1 signifie n'importe quelle valeur. 2 est dû au fait que vous saisissez une combinaison de deux lettres. Dans les données d'entrée de la <Fig.2>, il correspond que la combinaison des deux nombres x le nombre de données de test (facultatif).
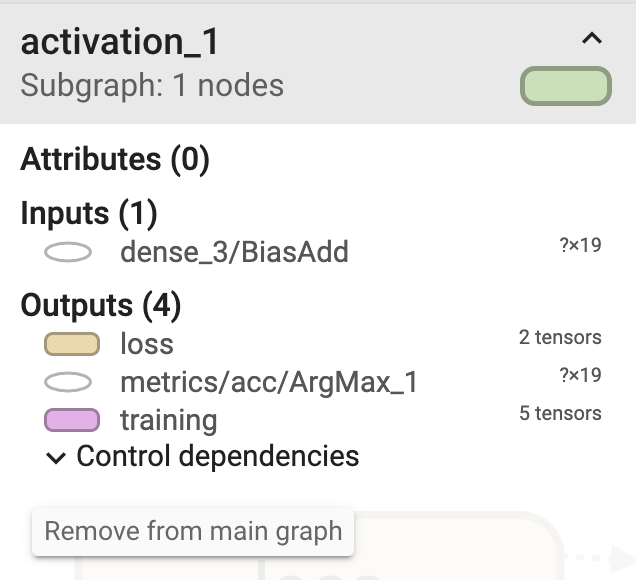
Regardons le côté sortie (activation_1). Puisque activation_1 est une fonction softmax, le résultat du calcul de la fonction softmax est sorti pour les 19 nombres sortis par le dense_3 précédent et sorti vers la perte, les métriques et l'apprentissage.
Les informations du modèle peuvent également être générées à l'aide de la méthode de résumé de keras. Dans Tensorboard, les couches étaient de bas en haut, mais celle-ci est de haut en bas.
notebook
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 512) 1536
_________________________________________________________________
dense_2 (Dense) (None, 256) 131328
_________________________________________________________________
dense_3 (Dense) (None, 19) 4883
_________________________________________________________________
activation_1 (Activation) (None, 19) 0
=================================================================
Total params: 137,747
Trainable params: 137,747
Non-trainable params: 0
** 6. Essayez de prédire sur Notebook **
Avant de l'exécuter sur iOS, assurez-vous qu'il fonctionne bien sur votre ordinateur portable. Si vous donnez une combinaison appropriée de deux nombres, vous pouvez voir que le calcul est correct.
notebook
np.argmax(model.predict(np.array([[7,6]])),axis=1)
// array([13])
np.argmax(model.predict(np.array([[1,3]])),axis=1)
// array([4])
** 7. Conversion en Core ML **
Enregistrez le modèle créé ci-dessus. (Même si vous ne le faites pas, le modèle est déjà obtenu, vous pouvez donc le convertir en Core ML tel quel.)
notebook
model.save('my_model.h5')
Lisez et convertissez.
notebook
from keras.models import load_model
keras_model = load_model('my_model.h5')
from coremltools.converters import keras as converter
#Faire une étiquette de classement pour les numéros des résultats attendus["0","1","2"..."18"]
class_labels = np.arange(0, 19).astype('unicode').tolist()
#conversion
mlmodel = converter.convert(keras_model, #Modèle à convertir
output_names=['digitProbabilities'], #Donnez un nom à la sortie attendue. Il sera accessible sous forme de nom de variable depuis swift
class_labels=class_labels, #Étiquette de classification des résultats des prévisions
predicted_feature_name='digit' #Donnez un nom à la sortie de classification. Il sera accessible sous forme de nom de variable depuis swift
)
vous sauvegardez.
notebook
coreml_model_path = 'my_model.mlmodel'
mlmodel.save(coreml_model_path)
Le code ici est le même que celui écrit dans ce livre.
Introduction à la pratique des outils de base ML - iOS x DEEP LEARNING

** 8. Téléchargez le modèle Core ML (fichier .mlmodel) **
Sélectionnez dans Notebook comme indiqué ci-dessous et sélectionnez "Télécharger" pour télécharger.
** 9. Glisser-déposer vers le projet Xcode **
Démarrez Xcode et créez une "Application à vue unique" à partir de Créer un projet.
Le projet que j'ai réalisé cette fois est sur github, vous pouvez donc l'utiliser. TokyoYoshida/CoreMLSimpleTest
Faites glisser et déposez le fichier .mlmodel vers n'importe quel emplacement de votre projet.
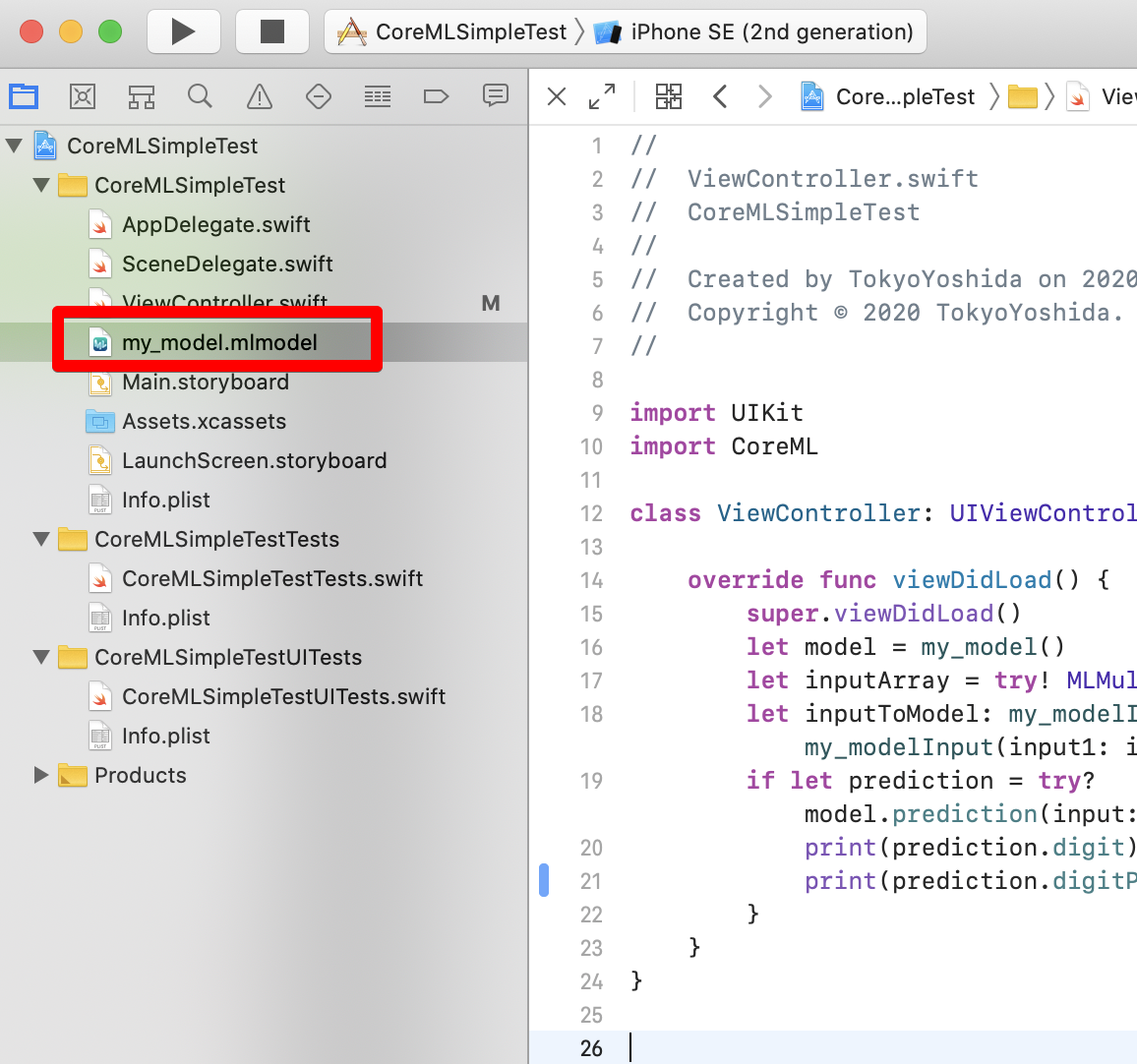
Vous pouvez voir l'aperçu en sélectionnant le modèle dans Xcode.
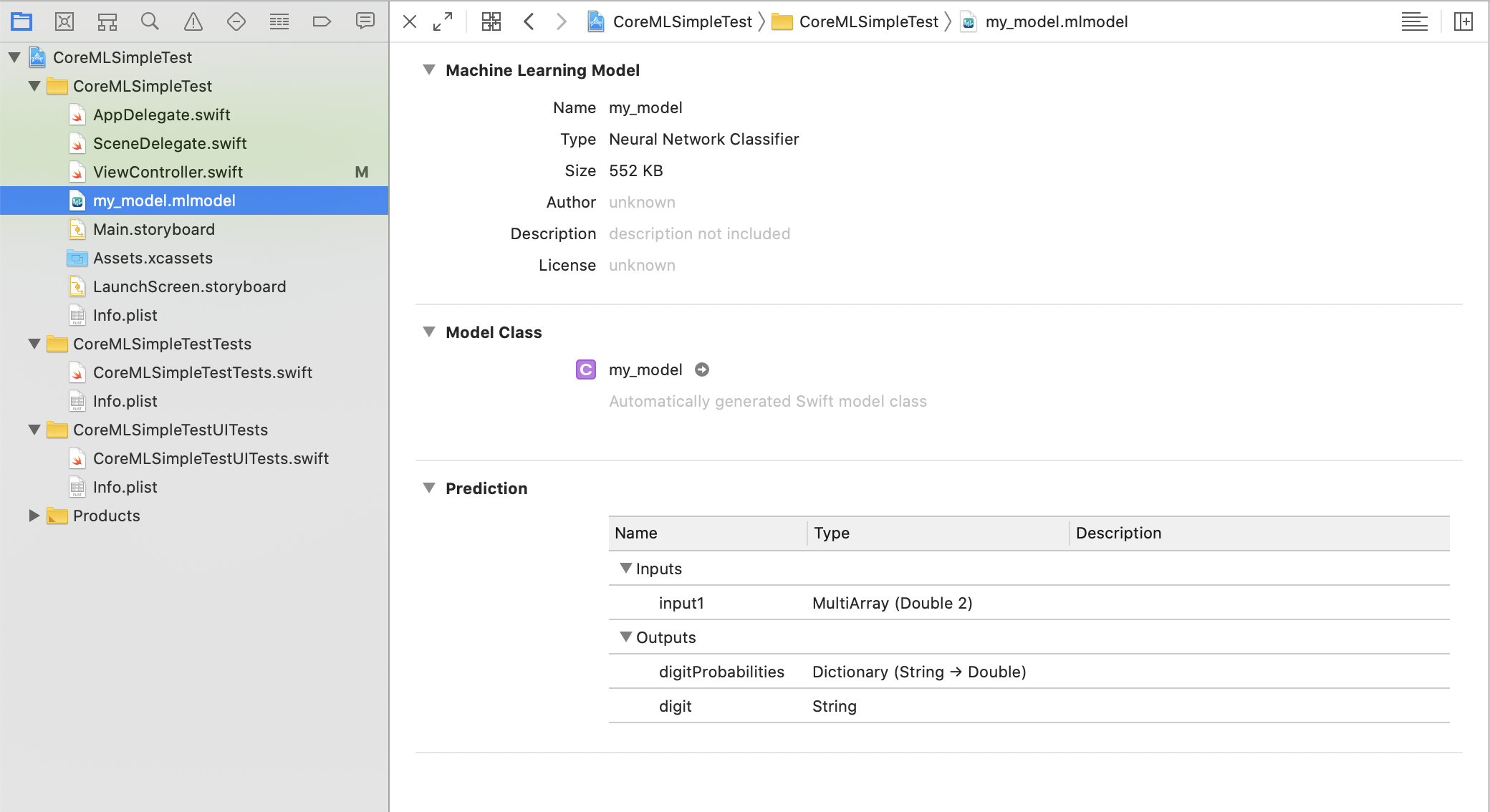
L'entrée est de type MultiArray et prend deux Doubes. Cela donne [2,3], par exemple, si vous voulez attendre 2 + 3. Dans la sortie, digitProbabilities est Dictionary, et la chaîne de caractères est Key et Double est Value. Cet élément est un résultat attendu et la probabilité pour chaque étiquette numérique est sortie. chiffre est le résultat de l'application du résultat attendu à l'étiquette numérique.
Le type MultiArray est un tableau multidimensionnel utilisé comme entrée ou sortie du modèle défini dans Core ML.
** 10. Écrivez le code d'inférence à l'aide de Core ML **
Étant donné que ce modèle n'est pas une reconnaissance d'image, nous utiliserons directement Core ML sans utiliser Vision Framework. Nous écrirons le code dans viewDidLoad de ViewController.
ViewController.swift
class ViewController: UIViewController {
override func viewDidLoad() {
super.viewDidLoad()
let model = my_model()
//Créez une paire de nombres que vous souhaitez prédire
let inputArray = try! MLMultiArray([2,3])
let inputToModel: my_modelInput = my_modelInput(input1: inputArray)
//Déduire
if let prediction = try? model.prediction(input: inputToModel) {
//Sortie de résultat
print(prediction.digit)
print(prediction.digitProbabilities)
}
}
}
** 11. Faites-le **
Lorsque je lance l'application, l'écran de l'application apparaît inutilement, mais je m'en fiche et regarde la colonne Sortie de Xcode.
Sortie de résultat
5
["13": 1.401298464324817e-45, "7": 4.403268860642129e-08, "16": 0.0, "12": 1.401298464324817e-45, "10": 1.401298464324817e-45, "4": 2.876720373024e-06, "11": 1.401298464324817e-45, "1": 1.2956196287086532e-23, "6": 6.624156412726734e-06, "8": 6.452452973902557e-18, "15": 1.401298464324817e-45, "2": 7.265933324842114e-14, "0": 1.0373160919090815e-33, "18": 0.0, "9": 1.7125880512063084e-34, "17": 0.0, "3": 1.129986526746086e-15, "14": 1.401298464324817e-45, "5": 0.9999904632568359]
Puisque nous donnons 2 + 3, 5 est déduit. Dans la sortie de digitProbabilities, la probabilité est sortie en utilisant chaque étiquette comme clé. La probabilité d'être 5 est de 0,9999904632568359, donc presque 1. La probabilité d'autres nombres, par exemple 13, est de 1,401298464324817e-45, mais c'est 1,401298464324817 ✕ 10 à la -45e puissance, donc le résultat est presque nul.
finalement
Note publie régulièrement sur le développement iOS, alors suivez-nous. https://note.com/tokyoyoshida
Nous envoyons des conseils simples sur Twitter. https://twitter.com/jugemjugemjugem
Recommended Posts