Extract the table of image files with OneDrive & Python
I want to extract the table from the image
You may want to extract the ** table in the image file ** as table data.
For example, "scan a paper book or document and digitize it as an image file or PDF file".
(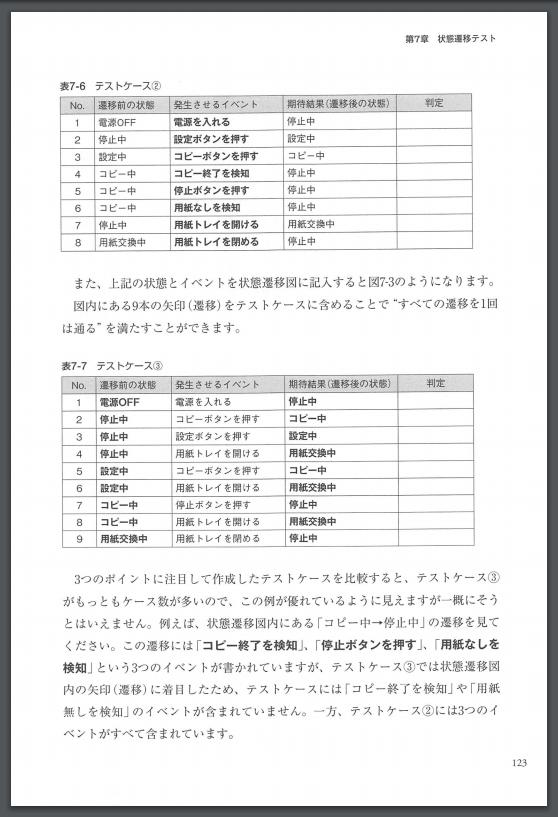
The table in this is not OCR processed ** just an image **, so it is not recognized as a character, let alone a table.
Therefore, of course, it cannot be treated as table data as it is. Then, is there no choice but to give up and steadily tabulate the data? No, ** don't give up! ** **
How to extract table data from an image
In fact, even from such images (jpg, png, pdf, etc.), the table can be extracted as data in the next step.
Preparation. Register for an account on Microsoft OneDrive (free) 0. Convert image files (jpg, png, etc.) to pdf files (this step is not necessary for PDF from the beginning)
- Save the PDF file to OneDrive, convert it to Word and apply OCR processing
- Save OCR processed Word as PDF
- Extract the table in PDF with Python
I will use Word on the way, but since I use free Office Online, it is okay if Microsoft Word is not installed on my PC.
Then, this time, I will explain using the PDF file of ↓.
(
If you want to extract a table from an image file (jpg, png, etc.), first convert it to a PDF file. There is also a free web service that converts image files to PDF, but the simplest is [Right-click the image file-> Print-> Select "Microcoft Print to PDF" on the printer to print].
Advance preparation. Register an account on OneDrive
Register an account on Microsoft OneDrive. Free.
[Get a Microsoft account] (https://www.microsoft.com/ja-jp/office/homeuse/onedrive-guide.aspx)
1. Save the PDF file to OneDrive
Upload the target PDF file to OneDrive.
Right-click on the file and select Open.
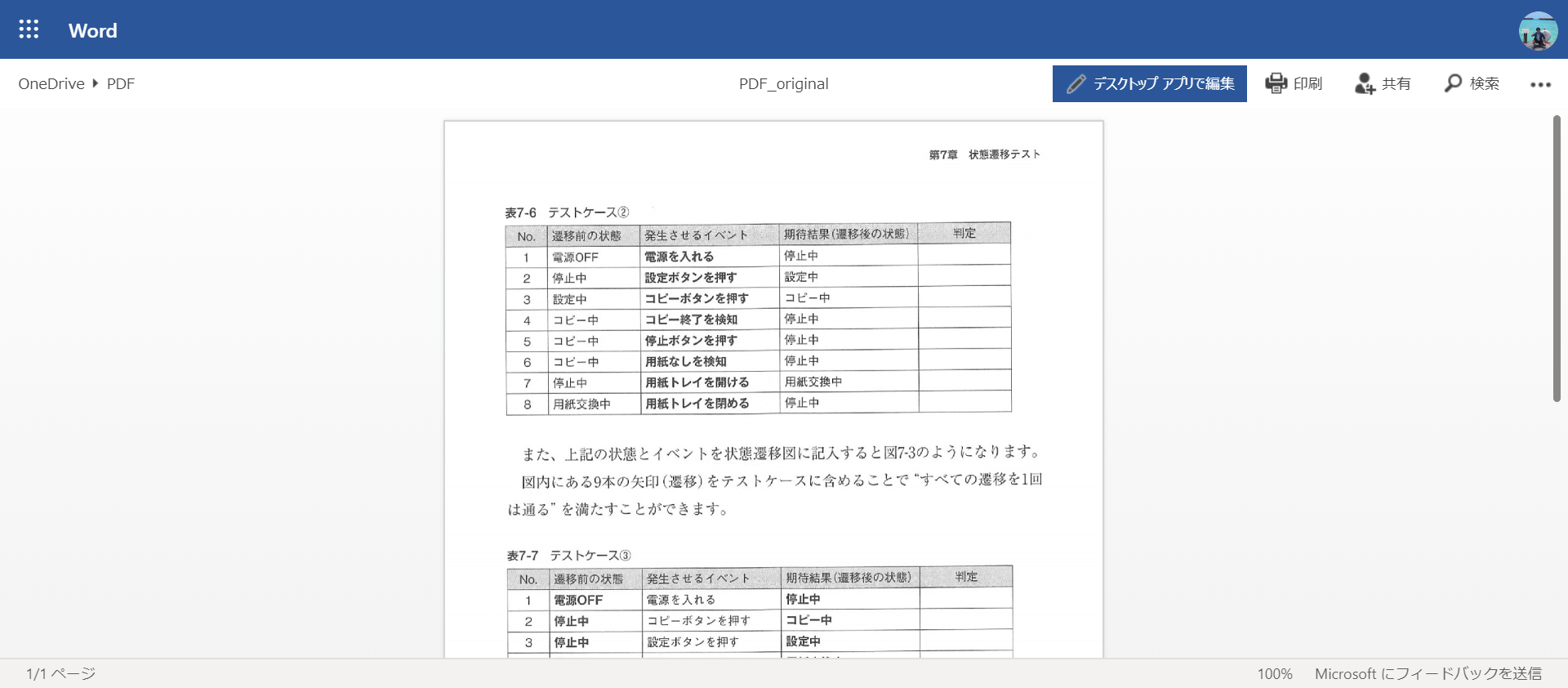
At this point, if you try to select around the table, you can select the characters as text. The table structure is also recognized.
Press the "Edit with Desktop App" button. Then you will be asked if you want to convert the file, so press the "Convert" button.
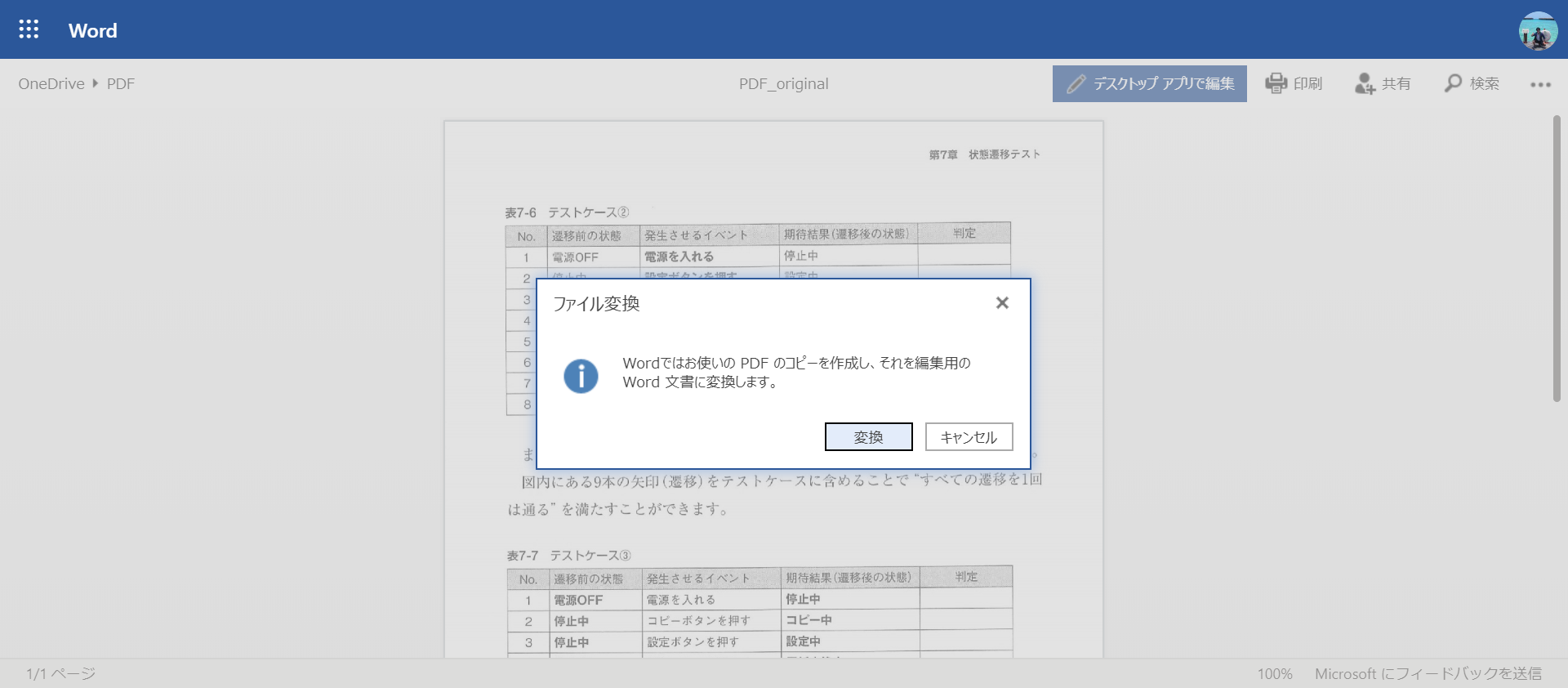
Then the conversion will take place. When the conversion is complete, a confirmation screen will appear, so press "Edit".
This will open Word in your browser. It is properly converted as table data.
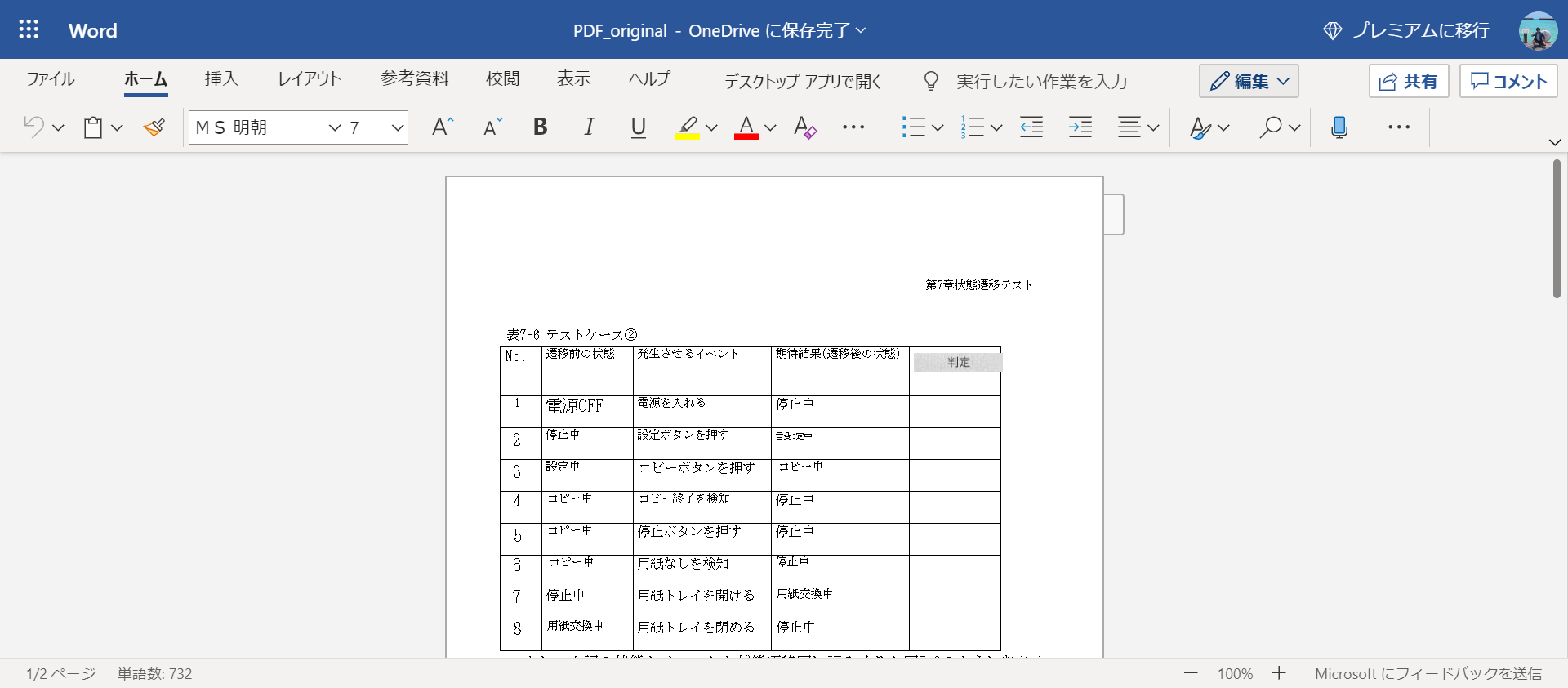
There may be some places where the characters are not recognized correctly, so if you can fix it at this point, fix it manually. In this case, "Copy" may be "Coby", but the conversion is almost correct. It is quite a recognition accuracy!
2. Save OCR processed Word as PDF
PDF files are easier to handle in Python than Word files, so convert them to PDF and download.
Select "File" in the upper left and select Save As → Download as PDF.

3. Extract the table in PDF with Python
Let's open the downloaded PDF file. Unlike the original PDF, the table is properly recognized as a table. It's bad to see the font because it's big or small, but you don't have to worry because it will be extracted as a pandas DataFrame.
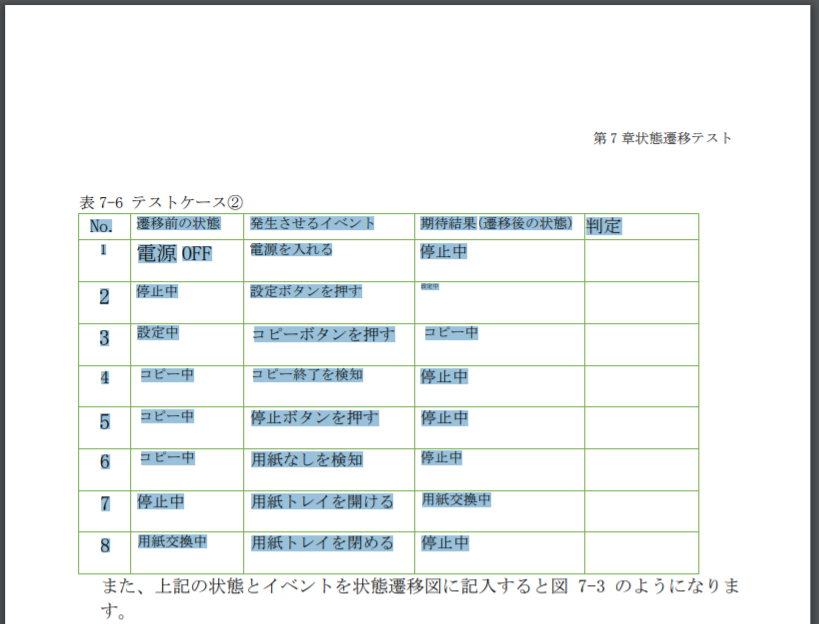
Now that you've come this far, the rest is a simple table using Python using the method introduced in the article "Extract the table in PDF with Python". Can be extracted.
python
import pandas as pd
import tabula
# lattice=True to determine cells by table axis
dfs = tabula.read_pdf("PDF_ocr.pdf", lattice=True, pages='1')
for df in dfs:
display(df)
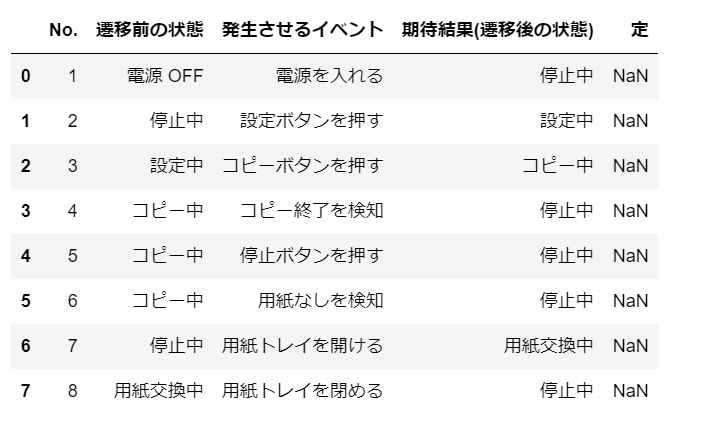
Execution result
Recommended Posts