is sent to cgi-bin / index.py by the POST method.
It's like that.
A page like the one below will be created.
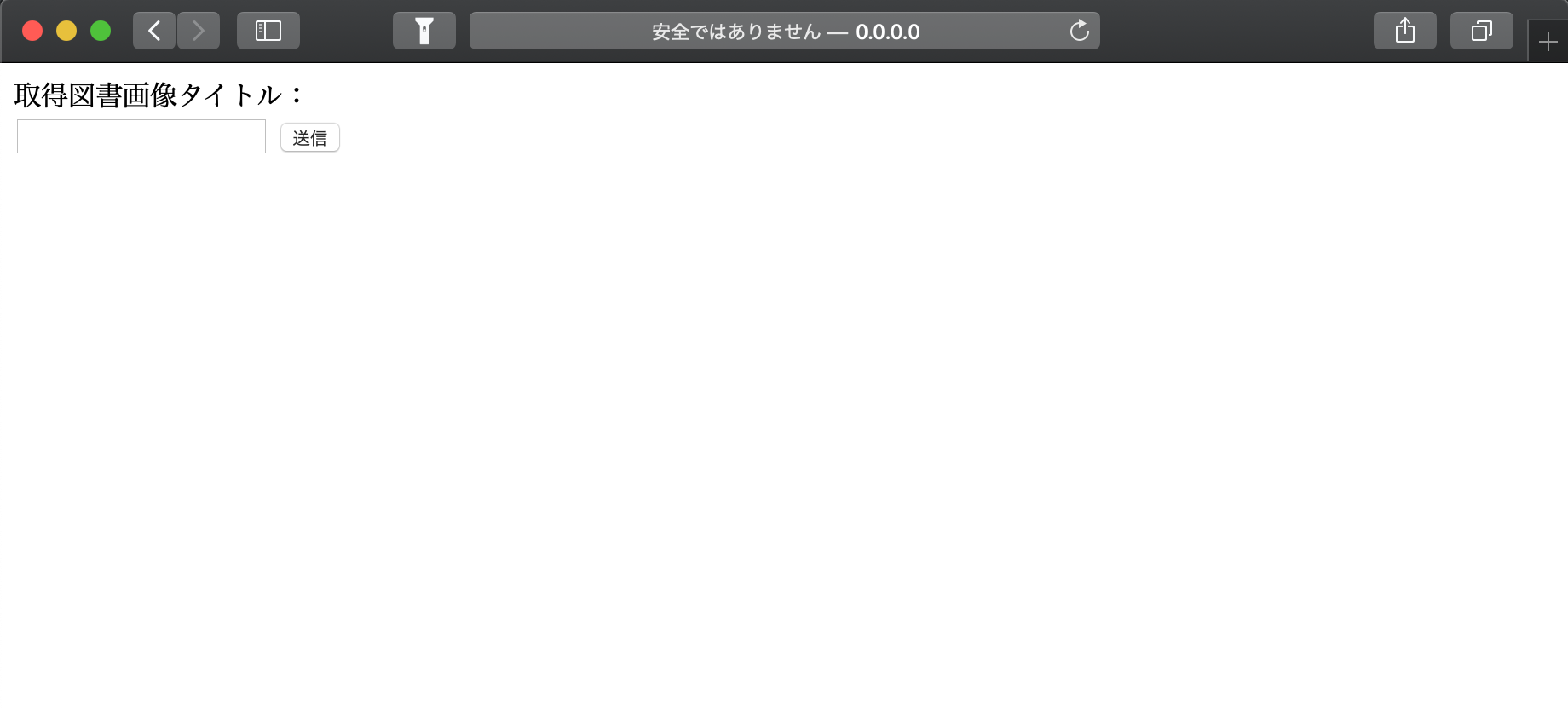
The data entered in the text box will be sent to index.py when you press the [Send] button.
4. Create server.py
You will need it to set up a server for verification locally.
server.py
import http.server
http.server.test(HandlerClass=http.server.CGIHTTPRequestHandler)
When you start the Python file created in Terminal, the local server will start up.
With the local server up
http://0.0.0.0:8000/
When you access, you should see the index.html you just saw.
Terminal
$ python server.py
Serving HTTP on 0.0.0.0 port 8000 (http://0.0.0.0:8000/) ...
- By the way, it is command + C to stop the local server.
5. Create index.py
Use the data sent from index.html to send a request for the Google Book Search API.
index.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import cgi #Import CGI module
import cgitb
import sys
import requests
import json
#Book search API template
api = "https://www.googleapis.com/books/v1/volumes?q={title}&maxResults=10&startIndex=0"
#Since it is used for debugging, it is not described in the production environment.
cgitb.enable()
#Get the form data entered by the user
form = cgi.FieldStorage()
#Header for writing HTML
print("Content-Type: text/html; charset=UTF-8")
print("")
#If no form data has been entered
if "text" not in form:
print("<h1>Error!</h1>")
print("<br>")
print("Enter the text!")
print("<a href='/'><button type='submit'>Return</button></a>")
sys.exit() # index.End of py
text = form.getvalue("text") #Get the value of text data
url = api.format(title=text) #Book search api search word{title}Apply the input text to
response = requests.get(url) #Throw a request
data = json.loads(response.text) #Convert response to json format
#Reflect the response in html
print(data['items'][0]['volumeInfo']['title'])
print("<br>")
print("<img src=" + data['items'][0]['volumeInfo']['imageLinks']['thumbnail'] + ">")
print("<br>")
print("<a href='/'><button type='submit'>Return</button></a>")
I've added a lot in the comments, but I'll explain it.
↓ This is the URL of the Google Books API.
https://www.googleapis.com/books/v1/volumes?q=いちご100&maxResults=10&startIndex=0
Enter the name of the book you want to search after ** q = ** and it will return a related response.
You can easily check it using curl.
Terminal
$ curl https://www.googleapis.com/books/v1/volumes?q=Strawberry 100&maxResults=10&startIndex=0
"kind": "books#volumes",
"totalItems": 2836,
"items": [
{
"kind": "books#volume",
"id": "vWSUDwAAQBAJ",
"etag": "b/w9qaxsyy4",
"selfLink": "https://www.googleapis.com/books/v1/volumes/vWSUDwAAQBAJ",
"volumeInfo": {
"title": "Strawberry 100% monochrome version [Free for a limited time] 2",
"authors": [
"Mizuki Kawashita"
],
"publisher": "Shueisha",
"publishedDate": "2002-10-04",
"description": "[Spring Man!!Free for a limited time!!/ Junpei Manaka suddenly lost his love maze! A super youth romantic comedy led by strawberry pants! ] * This is a free trial version for a limited time until May 8, 2019. It will not be available after May 9, 2019. Nishino and Tojo, the feeling of the middle swaying between them. What do you really like about Nishino? Or is it Tojo? On the day of the examination, when I was greeted without studying at all, the entrance of the strawberry-patterned labyrinth, a phantom beautiful girl was in front of me ...!!What to do in the middle!?",
"industryIdentifiers": [
{
"type": "OTHER",
"identifier": "PKEY:088733268733043155P5"
}
],
"readingModes": {
"text": true,
"image": false
},
"pageCount": 188,
"printType": "BOOK",
"categories": [
"Comics & Graphic Novels"
],
"maturityRating": "NOT_MATURE",
"allowAnonLogging": false,
"contentVersion": "1.2.2.0.preview.2",
"panelizationSummary": {
"containsEpubBubbles": true,
"containsImageBubbles": true,
"epubBubbleVersion": "99b0fa95624a43e9_A",
"imageBubbleVersion": "99b0fa95624a43e9_A"
},
"imageLinks": {
"smallThumbnail": "http://books.google.com/books/content?id=vWSUDwAAQBAJ&printsec=frontcover&img=1&zoom=5&source=gbs_api",
"thumbnail": "http://books.google.com/books/content?id=vWSUDwAAQBAJ&printsec=frontcover&img=1&zoom=1&source=gbs_api"
},
"language": "ja",
"previewLink": "http://books.google.co.jp/books?id=vWSUDwAAQBAJ&dq=%E3%81%84%E3%81%A1%E3%81%94100&hl=&cd=1&source=gbs_api",
"infoLink": "http://books.google.co.jp/books?id=vWSUDwAAQBAJ&dq=%E3%81%84%E3%81%A1%E3%81%94100&hl=&source=gbs_api",
"canonicalVolumeLink": "https://books.google.com/books/about/%E3%81%84%E3%81%A1%E3%81%94100_%E3%83%A2%E3%83%8E%E3%82%AF%E3%83%AD%E7%89%88_%E6%9C%9F%E9%96%93%E9%99%90.html?hl=&id=vWSUDwAAQBAJ"
},
"saleInfo": {
"country": "JP",
"saleability": "NOT_FOR_SALE",
"isEbook": false
},
"accessInfo": {
"country": "JP",
"viewability": "NO_PAGES",
"embeddable": false,
"publicDomain": false,
"textToSpeechPermission": "ALLOWED",
"epub": {
"isAvailable": true
},
"pdf": {
"isAvailable": true
},
Abbreviation------------------------------------------------------
The long response as described above is stored in response,
In data, response is converted to JSON type and stored.
This time, I want to use [title] and [thumbnail] from them, so
data['items'][0]['volumeInfo']['title']
data['items'][0]['volumeInfo']['imageLinks']['thumbnail']
Access as follows and retrieve the required data.
By changing the value of [0] to [1] [2]
You can change the search result target to be retrieved.

↓↓↓

Completion ○ △ □
** Q2. Addictive points **
When you press the send button,
FileNotFoundError: [Errno 2] No such file or directory: '/Users/hoge/project/cgi-bin/index.py'
Error is displayed and the search results are not displayed
** A2. Solution **
/Users/hoge/project/cgi-bin/index.py existed.
The first line of index.py was incorrect
× #!usr/bin/env python3
○ #!/usr/bin/env python3
** Q3.requests cannot be imported **
import requests
An error occurs at the location of
** A3. Solution **
This article was very helpful.
https://qiita.com/Kent_recuca/items/349586e9c034535f2991
In Python sys.path
Resolved by adding the path where requests are installed
Summary
I used to create a web app using Spring Boot,
Compared to that, I feel that the folder structure and environment construction are easier and can be moved immediately.
I knew it was used in the field of machine learning, but I was surprised that it was also used in the Web environment.
Since I was new to Python,
Why the error happens after the #, which should be a comment
Why is index.html displayed when I start the local server?
There are still many mysteries, but I would like to study and deepen my understanding.