Quick web scraping with Python (while supporting JavaScript loading)
Introduction
It's often the case that you want to extract a specific element from a web page and go to it. (I want to watch the inventory and price of a certain product on an EC site every 5 minutes, I want to extract the text accurately for document classification, etc.) Such element extraction is sometimes called web scraping, and Python is also useful in such cases.
By the way, there is Crawler / Scraping Advent Calendar 2014, which is perfect for that purpose, and the following articles are well organized. (I noticed its existence a while ago) http://orangain.hatenablog.com/entry/scraping-in-python
Let's try it first
As mentioned at the end of the above article, `requests``` and `lxml``` are generally sufficient when scraping with Python.
pip install requests
pip install lxml
Now, let's extract the text part from the following page of TV Asahi News. http://news.tv-asahi.co.jp/news_politics/articles/000041338.html
First, let's see how the page is organized. In Chrome, there is Developer Tools as standard as shown below (Firebug in Firefox), and when you start it, click the magnifying glass icon and move the mouse cursor to the part you want to extract, and you can easily hit the target element You can see how the page structure is.
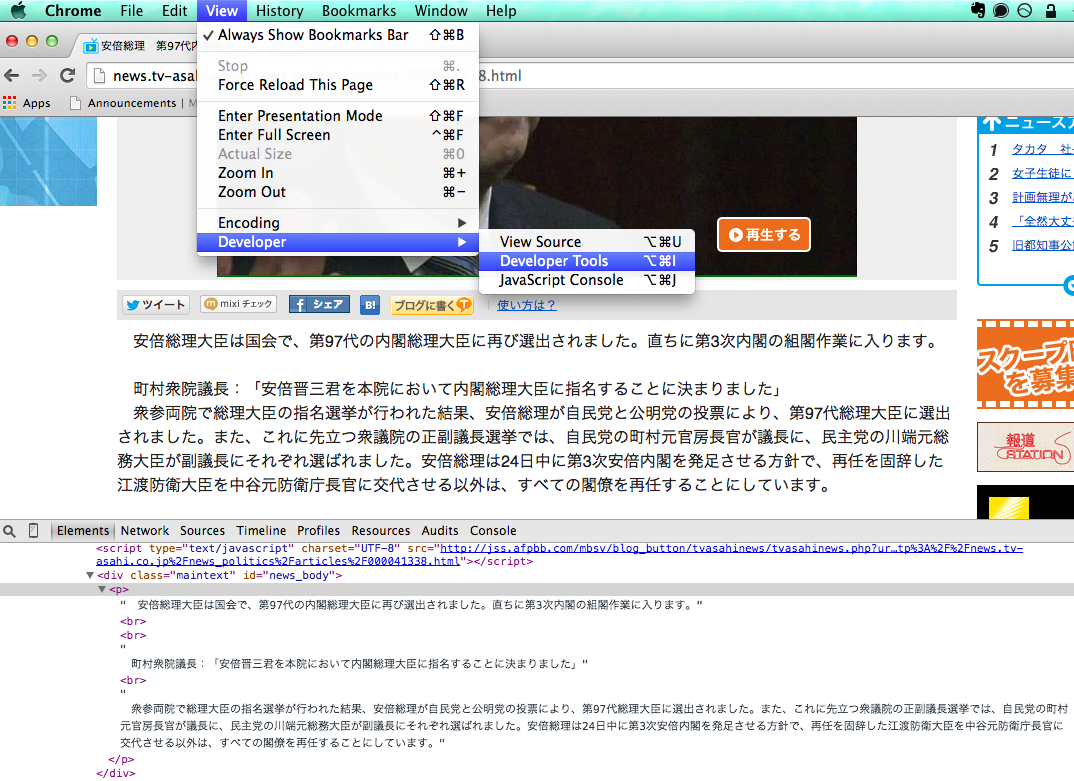
<div class="maintext" id="news_body">Under the tag<p>You can see that the desired sentence is further below the tag.
This location can be expressed as `` `# news_body> p``` using the CSS selector, so the scraping code that finally extracts this part of the text can be written as:
cf. Summary of CSS selectors http://weboook.blog22.fc2.com/blog-entry-268.html
import lxml.html
import requests
target_url = 'http://news.tv-asahi.co.jp/news_politics/articles/000041338.html'
target_html = requests.get(target_url).text
root = lxml.html.fromstring(target_html)
#text_content()The method gets all the text below that tag
root.cssselect('#news_body > p').text_content()
If Import Error: cssselect seems not to be installed.
If you get angry, you can do `` `pip install cssselect```.
As you can see, it's very easy.
Load JavaScript
The next tricky part is the part that is rendered in JavaScript. Looking at it with Developer Tools as before, I think that it can be taken in the same way, but in fact this is the result of loading JavaScript and rendering it.

The html before loading JavaScript is simply like this.
<!--related news-->
<div id="relatedNews"></div>
So even if you try to analyze the html obtained by requests as it is, it will not work. That's where selenium and PhantomJS come in.
pip install selenium and PhantomJS[around here](http://tips.hecomi.com/entry/20121229/1356785834)Please install it referring to.
Then the version that loads JavaScript looks like this.
After getting html through selenium & PhantomJS, the flow is the same.
```py
import lxml.html
from selenium import webdriver
target_url = 'http://news.tv-asahi.co.jp/news_politics/articles/000041338.html'
driver = webdriver.PhantomJS()
driver.get(target_url)
root = lxml.html.fromstring(driver.page_source)
links = root.cssselect('#relatedNews a')
for link in links:
print link.text
Execution result
The 3rd Abe Cabinet will be established soon. Only the Minister of Defense will be replaced.
Shinzo Abe nominated as the 97th Prime Minister of the House of Representatives plenary session
Today's special session of the Diet convenes the third Abe Cabinet at night
Minister of Defense Eto declines reappointment to establish the third Abe Cabinet
"A fruitful year" Prime Minister Abe looks back on this year
Summary
As mentioned above, not only normal html pages but also pages with JavaScript rendering could be scraped quickly and easily. When you actually scrape various sites, you often have trouble with character code problems, but if you can do web scraping, you can automate various tasks, so in various situations It is useful for me personally. Have a nice Christmas and web scraping life.
Recommended Posts