First Anime Face Recognition with Chainer
I wanted to try deep learning, but with Caffe, I was frustrated without feeling like "writing", but chainer appeared, so I decided to give it a try.
Anyway, I'll try anime face recognition, which I've always wanted to do. Actually, I would like to try face detector + character classification by face, but first I aim to classify faces and others.
By the way, when it comes to face recognition in anime, there is a OpenCV + cascade detector, and it recognizes it quite nicely. But,
――In principle, you can't recognize anything other than the face from the front. ――It is not detected even if it is tilted a little.
Since there are problems such as, I would like to improve the detection accuracy somehow.
Step1: Test image preparation
I decided to prepare it myself, considering using it for other tasks as well. It takes about 20 hours. Poyo-n.
policy
- Use OpenCV and lbpcascade_animeface to cut out a face from an anime frame.
- Except for the misrecognized image from there, put it in the correct answer set.
- Using OpenCV again, extract the frame where the face was not recognized.
- From the image in 3., search for the one that actually shows the face, cut out the target face, and add it to the correct answer set.
- Randomly crop the rest from the frame without the face and add it to the incorrect answer set.
- Rotate each image 90 degrees, 180 degrees, 270 degrees to multiply the data by a factor of four.
- Due to the design of the network, it was necessary to have the same input size, so converted to 64x64.
Training set
--110,525 (34,355 face data, 76,170 other images) --Angel Beats !, Kill Me Baby, Feast ... etc. ――I intended to select the one that seems to have a different pattern.
Validation set
―― 8,525 sheets (face data 3,045 sheets, other images 5,480 sheets) --Kin Mosa
I don't like the fact that the ratio of the training set and the validation set is not the same, but I will move on for the time being.
Image sample
--Face image

- The entire

Step2: Create a learner
CNN
network/frgnet64.py
import chainer
import chainer.functions as F
class FrgNet64(chainer.FunctionSet):
insize = 64
def __init__(self):
super(FrgNet64, self).__init__(
conv1 = F.Convolution2D(3, 96, 5, pad=2),
bn1 = F.BatchNormalization(96),
conv2 = F.Convolution2D(96, 128, 5, pad=2),
bn2 = F.BatchNormalization(128),
conv3 = F.Convolution2D(128, 256, 3, pad=1),
conv4 = F.Convolution2D(256, 384, 3, pad=1),
fc5 = F.Linear(18816, 2048),
fc6 = F.Linear(2048, 2),
)
def forward_but_one(self, x_data, train=True):
x = chainer.Variable(x_data, volatile=not train)
h = F.max_pooling_2d(F.relu(self.bn1(self.conv1(x))), 5, stride=2)
h = F.max_pooling_2d(F.relu(self.bn2(self.conv2(h))), 5, stride=2)
h = F.max_pooling_2d(F.relu(self.conv3(h)), 3, stride=2)
h = F.leaky_relu(self.conv4(h), slope=0.2)
h = F.dropout(F.leaky_relu(self.fc5(h), slope=0.2), train=train)
return self.fc6(h)
def calc_confidence(self, x_data):
h = self.forward_but_one(x_data, train=False)
return F.softmax(h)
def forward(self, x_data, y_data, train=True):
""" You must subtract the mean value from the data before. """
y = chainer.Variable(y_data, volatile=not train)
h = self.forward_but_one(x_data, train=train)
return F.softmax_cross_entropy(h, y), F.accuracy(h, y)
- If the number of fully connected layers is three, the accuracy may be slightly improved, but the processing speed has dropped considerably, so we did not use it.
Learning code
network/manager.py
import numpy as np
import time
import six
from util import loader
from chainer import cuda, optimizers
class NetSet:
def __init__(self, meanpath, model, gpu=-1):
self.mean = loader.load_mean(meanpath)
self.model = model
self.gpu = gpu
self.insize = model.insize
if gpu >= 0:
cuda.init(gpu)
self.model.to_gpu()
def calc_max_label(self, prob_arr):
h, w = prob_arr.shape
labels = [0] * h
for i in six.moves.range(0, h):
label = prob_arr[i].argmax()
labels[i] = (label, prob_arr[i][label])
return labels
def forward_data_seq(self, dataset, batchsize):
sum_loss = 0
sum_accuracy = 0
for i in range(0, len(dataset), batchsize):
mini_dataset = dataset[i:i+batchsize]
x_batch, y_batch = self.create_minibatch(mini_dataset)
loss, acc = self.forward_minibatch(x_batch, y_batch)
loss_data = loss.data
acc_data = acc.data
if self.gpu >= 0:
loss_data = cuda.to_cpu(loss_data)
acc_data = cuda.to_cpu(acc_data)
sum_loss += float(loss_data) * len(mini_dataset)
sum_accuracy += float(acc_data) * len(mini_dataset)
return sum_loss, sum_accuracy
def forward_minibatch(self, x_batch, y_batch, train=False):
if self.gpu >= 0:
x_batch = cuda.to_gpu(x_batch)
y_batch = cuda.to_gpu(y_batch)
return self.model.forward(x_batch, y_batch, train=False)
def create_minibatch(self, dataset):
minibatch = np.ndarray(
(len(dataset), 3, self.insize, self.insize), dtype=np.float32)
minibatch_label = np.ndarray((len(dataset),), dtype=np.int32)
for idx, tuple in enumerate(dataset):
path, label = tuple
minibatch[idx] = loader.load_image(path, self.mean, False)
minibatch_label[idx] = label
return minibatch, minibatch_label
def create_minibatch_random(self, dataset, batchsize):
if dataset is None or len(dataset) == 0:
return self.create_minibatch([])
rs = np.random.random_integers(0, high=len(dataset) - 1, size=(batchsize,))
minidataset = []
for idx in rs:
minidataset.append(dataset[idx])
return self.create_minibatch(minidataset)
train/batch.py
import numpy as np
import sys
import time
import six
import six.moves.cPickle as pickle
from util import loader, visualizer
from chainer import cuda, optimizers
from network.manager import NetSet
class Trainer(NetSet):
""" Network utility class """
def __init__(self, trainlist, validlist, meanpath, model,
optimizer, weight_decay=0.0001, gpu=-1):
super(Trainer, self).__init__(meanpath, model, gpu)
self.trainset = loader.load_image_list(trainlist)
self.validset = loader.load_image_list(validlist)
self.optimizer = optimizer
self.wd_rate = weight_decay
if gpu >= 0:
cuda.init(gpu)
self.model.to_gpu()
optimizer.setup(model.collect_parameters())
def train_random(self, batchsize, lr_decay=0.1, valid_interval=500,
model_interval=10, log_interval=100, max_epoch=100):
epoch_iter = 0
if batchsize > 0:
epoch_iter = len(self.trainset) // batchsize + 1
begin_at = time.time()
for epoch in six.moves.range(1, max_epoch + 1):
print('epoch {} starts.'.format(epoch))
train_duration = 0
sum_loss = 0
sum_accuracy = 0
N = batchsize * log_interval
for iter in six.moves.range(1, epoch_iter):
iter_begin_at = time.time()
x_batch, y_batch = self.create_minibatch_random(self.trainset, batchsize)
loss, acc = self.forward_minibatch(x_batch, y_batch)
train_duration += time.time() - iter_begin_at
if epoch == 1 and iter == 1:
visualizer.save_model_graph(loss, 'graph.dot')
visualizer.save_model_graph(loss, 'graph.split.dot', remove_split=True)
print('model graph is generated.')
sum_loss += float(cuda.to_cpu(loss.data)) * batchsize
sum_accuracy += float(cuda.to_cpu(acc.data)) * batchsize
if iter % log_interval == 0:
throughput = batchsize * iter / train_duration
print('training: iteration={:d}, mean loss={:.8f}, accuracy rate={:.6f}, learning rate={:f}, weight decay={:f}'
.format(iter + (epoch - 1) * epoch_iter, sum_loss / N, sum_accuracy / N, self.optimizer.lr, self.wd_rate))
print('epoch {}: passed time={}, throughput ({} images/sec)'
.format(epoch, train_duration, throughput))
sum_loss = 0
sum_accuracy = 0
if iter % valid_interval == 0:
N_test = len(self.validset)
valid_begin_at = time.time()
valid_sum_loss, valid_sum_accuracy = self.forward_data_seq(self.validset, batchsize, train=False)
valid_duration = time.time() - valid_begin_at
throughput = N_test / valid_duration
print('validation: iteration={:d}, mean loss={:.8f}, accuracy rate={:.6f}'
.format(iter + (epoch - 1) * epoch_iter, valid_sum_loss / N_test, valid_sum_accuracy / N_test))
print('validation time={}, throughput ({} images/sec)'
.format(valid_duration, throughput))
sys.stdout.flush()
self.optimizer.lr *= lr_decay
self.wd_rate *= lr_decay
if epoch % model_interval == 0:
print('saving model...(epoch {})'.format(epoch))
pickle.dump(self.model, open('model-' + str(epoch) + '.dump', 'wb'), -1)
print('train finished, total duration={} sec.'
.format(time.time() - begin_at))
pickle.dump(self.model, open('model.dump', 'wb'), -1)
def forward_data_seq(self, dataset, batchsize, train=True):
sum_loss = 0
sum_accuracy = 0
for i in range(0, len(dataset), batchsize):
mini_dataset = dataset[i:i+batchsize]
x_batch, y_batch = self.create_minibatch(mini_dataset)
loss, acc = self.forward_minibatch(x_batch, y_batch, train)
loss_data = loss.data
acc_data = acc.data
if self.gpu >= 0:
loss_data = cuda.to_cpu(loss_data)
acc_data = cuda.to_cpu(acc_data)
sum_loss += float(loss_data) * len(mini_dataset)
sum_accuracy += float(acc_data) * len(mini_dataset)
return sum_loss, sum_accuracy
def forward_minibatch(self, x_batch, y_batch, train=True):
if self.gpu >= 0:
x_batch = cuda.to_gpu(x_batch)
y_batch = cuda.to_gpu(y_batch)
if train:
self.optimizer.zero_grads()
loss, acc = self.model.forward(x_batch, y_batch, train)
if train:
loss.backward()
self.optimizer.weight_decay(self.wd_rate)
self.optimizer.update()
return loss, acc
util/loader.py
import os
import numpy as np
import six.moves.cPickle as pickle
from PIL import Image
### functions to load files, such as model.dump, images, and mean file.
def unpickle(filepath):
return pickle.load(open(filepath, 'rb'))
def load_model(filepath):
""" load trained model.
If the model is trained on GPU, then you must initialize cuda-driver before.
"""
return unpickle(filepath)
def load_mean(filepath):
""" load mean file
"""
return unpickle(filepath)
def load_image_list(filepath):
""" load image-file list. Image-file list file consists of filepath and the label.
"""
tuples = []
for line in open(filepath):
pair = line.strip().split()
if len(pair) == 0:
continue
elif len(pair) > 2:
raise ValueError("list file format isn't correct: [filepath] [label]")
else:
tuples.append((pair[0], np.int32(pair[1])))
return tuples
def image2array(img):
return np.asarray(img).transpose(2, 0, 1).astype(np.float32)
def load_image(path, mean, flip=False):
image = image2array(Image.open(path))
image -= mean
if flip:
return image[:, :, ::-1]
else:
return image
Since main.py is messy, I will extract only the training part.
main.py
### a function for training.
def train(trainlist, validlist, meanpath, modelname, batchsize, max_epoch=100, gpu=-1):
model = None
if modelname == "frg64":
model = FrgNet64()
elif modelname == "frg128":
model = FrgNet128()
optimizer = optimizers.MomentumSGD(lr=0.001, momentum=0.9)
trainer = batch.Trainer(trainlist, validlist, meanpath, model,
optimizer, 0.0001, gpu)
trainer.train_random(batchsize, lr_decay=0.97, valid_interval=1000,
model_interval=5, log_interval=20, max_epoch=max_epoch)
Learning basically uses GPU, and because the image size is small, the CPU side is not written for multithreading.
Step3: Learning
Parameters
| Parameters | Set value | Remarks |
|---|---|---|
| learning rate | 0.001 | 0 for every 1 epoch.Multiply 97 |
| Mini batch size | 10 | |
| Weight attenuation | 0.0001 | Every time epoch elapses, the coefficient λ becomes 0..Multiply 97 |
| momentum | 0.9 | Default value of chainer |
――I tried to lower the learning rate when the change in the error became flat, but I stopped it because the error for the validation set did not converge well. ――I tried the mini-batch size at 100 at first, but I made it smaller because the error between the training set and the validation set was large. ――The weight attenuation coefficient could have been fixed, but I was worried that the learning rate and the value would eventually reverse, so I am gradually reducing it.
environment
| Version etc. | |
|---|---|
| GPU | GeForce GTX TITAN X |
| Python | Python 3.4.3 |
result
Time required
It took less than 3 hours in total and the training error was almost 0, so it ended with epoch 30. Image processing speed is approximately
--During training 560 sheets / sec --Validating 780 sheets / sec
was.
error
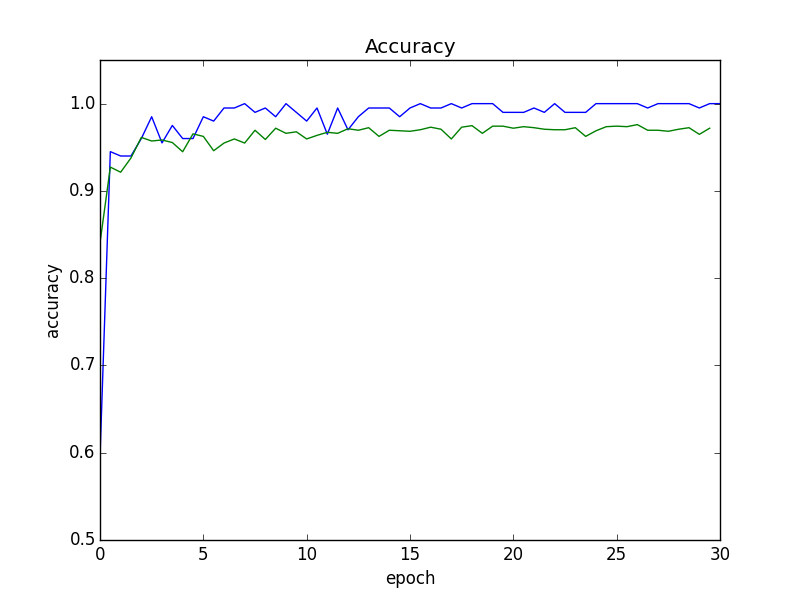
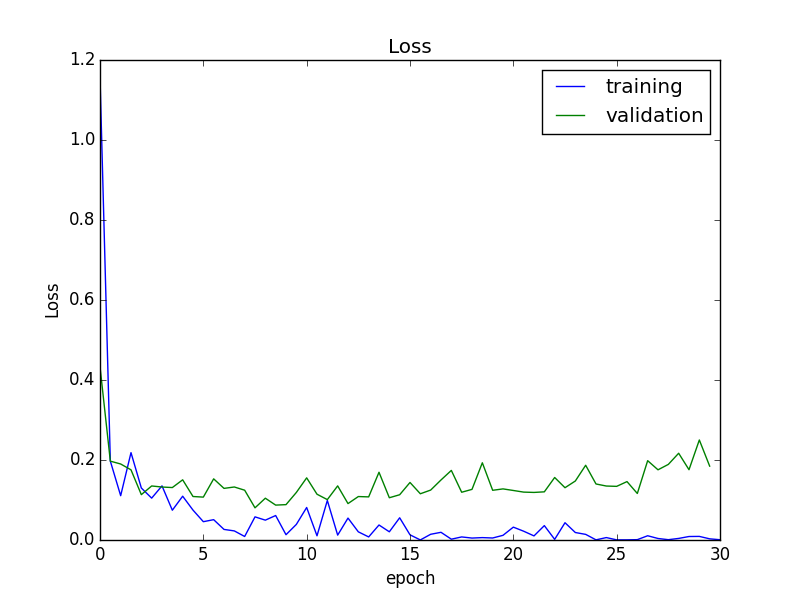
From the middle, the recognition accuracy has almost converged, but the error for the validation set has increased slightly. Therefore, in the following experiments, we will use the model at the end of epoch 15, which has the smallest error.
This model had a recognition accuracy of 95.5% for the validation set. Below is an example of a failing case.
Misrecognition example
Cases that are mistakenly recognized as faces

It seems that some test data is defective (labeling mistake). ..
Case where the face cannot be recognized

There is some data that the face is not cut out neatly, but I feel that he is making a mistake in a dignified manner, so I am a little worried ...
Step4: Input actual data
Cut out the image in the Sliding Window and put it in the trained Network. If you simply cut it out, it will be a considerable number of sheets, so after reducing the width of the image to 512,
--Aspect ratio 1: 1 -(size, stride) has 3 patterns of (48, 16), (72, 24), (144, 48)
I cut it out with and resized it to the same size as 64x64 during training. (In the image at hand, there are 630 ways in total) (Corrected on August 8, 2015)
Also, if you can put it in the Network and extract the area that is a candidate for the face, sift the area based on IoU (Intersection over Union)> = 30%, and the output value (probability) of the Network is the maximum. I'm selecting one. (I don't know if the absolute value of this value is meaningful) IoU with areas other than the face is not considered in particular.
Experiment
It is posted in comparison with the result of trying with OpenCV + lbpcascade_animeface. However, the results can change depending on the parameters, so I don't think it's necessarily a fair comparison. (The top is CNN and the bottom is the image detected by OpenCV) The average execution time was about 0.8 seconds for CNN (GPU) and about 0.35 seconds for OpenCV (CPU).
First of all, from the image that could be recognized by both OpenCV and this CNN. As expected, the position of anime face looks accurate.

 © Yui Hara / Houbunsha / Kiniro Mosaic Production Committee
© Yui Hara / Houbunsha / Kiniro Mosaic Production Committee
Next is the image with a profile that I was aiming for this time. The position of the frame is delicate, but I can recognize the profile that was not taken by OpenCV. However, there is a strange frame between Alice and Shinobu. ..

 © Yui Hara / Houbunsha / Kiniro Mosaic Production Committee
© Yui Hara / Houbunsha / Kiniro Mosaic Production Committee
Finally,

 © Koi / Houbunsha / Is the Order a Rabbit Committee?
© Koi / Houbunsha / Is the Order a Rabbit Committee?
Ah, the bin, the bin is detected. .. Of course, OpenCV detected it more accurately. sad
Summary
As a feeling, I feel that the number of cases that can be picked up is much higher than that of the OpenCV version, but at the same time, I got the impression that the rate of misrecognizing parts other than the face as a face has also increased. Based on that ...
What worked
- Proliferation of training data ――When I added rotation to the image and propagated the data, the convergence speed increased dramatically. After all, I realized that the amount of data is important.
- Mini batch size adjustment ――When I was updating the parameters by feeding 100 sheets at a time, the training error converged, but the validation error soon leveled off. However, when I reduced it to 10, the accuracy of validation increased by about 2pt, which gives the impression that it was effective as it was.
Improvement points, reflection, etc.
-
Detector --Detection is a simple Sliding Window, so it takes a considerable amount of time. To avoid this, we limit the size of the cropped image, but in this case, the face that fills the screen cannot be detected. .. ――This time it's face detection, so I don't think it's a big problem, but the aspect ratio is fixed at 1: 1. ――I feel that I should have used position-labeled data from the beginning.
-
Training data ――After all, I feel that the absolute amount was still small. --The incorrect data (quality) may not have been enough. I randomly cropped from an image without a face, but there were many images where the object itself was hardly reflected and the boundary of the object was not captured, so I think that it was still weak as data. .. The high false positive rate is probably due to its influence.
next··
I wonder if I would like to make a detector with the data with the position label. With the current method, even if the accuracy comes out, the speed does not come out, so I would like to try around SPP-net.
Source code
Since the version of chainer has changed and it does not work, I uploaded the corrected code to Github. https://github.com/homuler/pyon2-detector/
Recommended Posts