Face recognition of anime characters with Keras
Introduction
I referred to this article Classifying anime faces by deep learning with Keras I was able to make a learning model and check the correct answer rate, but what I wanted to do was to input the image of the anime character I picked up on the net and determine it, so this article includes that part as well. I am writing.
data set
The dataset used for learning was obtained from animeface-character-dataset. Unzip the compressed file animeface-character-dataset and leave only thumb in the folder.
Data set preprocessing
Images are resized to 32x32 using opencv, and the matrix of all images (14490) is saved to another file using save () of numpy. This saves you from having to deal with images every time and makes the execution speed a little faster. Store the correct label of the image in another file.
dataset_predisporsal.py
import os
import numpy as np
import cv2 as cv
data_dir_path = "./animeface-character-dataset/thumb/"
tmp = os.listdir(data_dir_path)
tmp=sorted([x for x in tmp if os.path.isdir(data_dir_path+x)])
dir_list = tmp
X_target=[]
for dir_name in dir_list:
file_list = os.listdir(data_dir_path+dir_name)
for file_name in file_list:
if file_name.endswith('.png'):
image_path=str(data_dir_path)+str(dir_name)+'/'+str(file_name)
image = cv.imread(image_path)
image = cv.resize(image, (32, 32))
image = image.transpose(2,0,1)
image = image/255.
X_target.append(image)
anime_class=[]
count=0
for dir_name in dir_list:
file_list = os.listdir(data_dir_path+dir_name)
for file_name in file_list:
if file_name.endswith('.png'):
anime_class.append(count)
count+=1
anime_arr2=np.array(anime_class)
np.save('anime_face_target.npy',anime_arr2)
anime_arr=np.array(X_target)
np.save('anime_face_data.npy',anime_arr)
Image matrix (14490,3,28,28) in anime_face_data.npy Correct label for anime_face_target.npy (14490,) Is saved.
Model building and learning with Keras
The two npy files created in the pre-processing are read and trained.
anime_face.py
import numpy as np
np.random.seed(20160715) #Fixed seed value
from keras.layers.convolutional import Convolution2D
from keras.layers.core import Activation
from keras.layers.core import Dense
from keras.models import Sequential
from keras.callbacks import EarlyStopping
from keras.callbacks import LearningRateScheduler
from keras.optimizers import Adam
from keras.optimizers import SGD
import sklearn.cross_validation
X_test=np.load('anime_face_data.npy')
Y_target=np.load('anime_face_target.npy')
a_train, a_test, b_train, b_test = sklearn.cross_validation.train_test_split(X_test,Y_target)
model = Sequential()
model.add(Convolution2D(96, 3, 3, border_mode='same', input_shape=(3, 32, 32)))
model.add(Activation('relu'))
model.add(Convolution2D(128, 3, 3))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(1024))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(203))
model.add(Activation('softmax'))
init_learning_rate = 1e-2
opt = SGD(lr=init_learning_rate, decay=0.0, momentum=0.9, nesterov=False)
model.compile(loss='sparse_categorical_crossentropy', optimizer=opt, metrics=["acc"])
early_stopping = EarlyStopping(monitor='val_loss', patience=3, verbose=0, mode='auto')
lrs = LearningRateScheduler(0.01)
hist = model.fit(a_train,b_train,
batch_size=128,
nb_epoch=50,
validation_split=0.1,
verbose=1)
model_json_str = model.to_json()
open('anime_face_model.json', 'w').write(model_json_str)
model.save_weights('anime_face_model.h5')
score=model.evaluate(a_test, b_test, verbose=0)
print(score[1])
The result was a correct answer rate of about 55%. I will not touch on how to increase the accuracy rate this time.
model_json_str = model.to_json()
open('anime_face_model.json', 'w').write(model_json_str)
model.save_weights('anime_face_model.h5')
This part is important and saves the training model and training results in anime_face_model.json and nime_face_model.h5 respectively. Now you can reuse the learning model and learning results. It's a moment when you run it. Now the main subject is.
Determine the original image using the learning results
The original image used this time is "Yagami Hayate" (yagami.png) from Magical Girl Lyrical Nanoha.

load_anime_face.py
import numpy as np
from keras.models import model_from_json
from keras.utils import np_utils
from keras.optimizers import SGD
import sklearn.cross_validation
import cv2 as cv
np.random.seed(20160717)
X_test=np.load('anime_face_data.npy')
Y_target=np.load('anime_face_target.npy')
model = model_from_json(open('anime_face_model.json').read())
model.load_weights('anime_face_model.h5')
init_learning_rate = 1e-2
opt = SGD(lr=init_learning_rate, decay=0.0, momentum=0.9, nesterov=False)
model.compile(loss='sparse_categorical_crossentropy', optimizer=opt, metrics=["acc"])
image = cv.imread('yagami.png')
image = cv.resize(image, (32, 32))
image = image.transpose(2,0,1)
image = image/255.
image=image.reshape(1,3,32,32)
for i in range(202):
sample_target=np.array([i])
score = model.evaluate(image, sample_target, verbose=0)
if score[1]==1.0:
break
print(i)
It was output as 39. This number will be the first number in the file name in thumb.
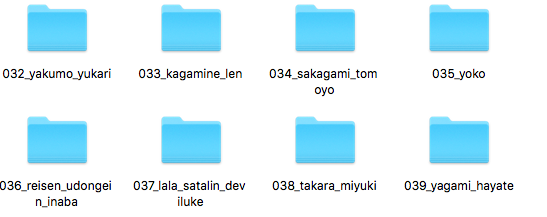
Therefore, No. 39 Yagami was able to answer the question correctly. However, since the correct answer rate is 55%, it is quite often incorrect.
in conclusion
I wrote the code and processing contents without any explanation, but now I can identify the character by inputting the original image. Even if you look only at the correct answer rate, you don't really feel it, so when you input a single image and get the result, it makes me feel like I've done it for a beginner in machine learning. If you have any questions or rushes, I would be grateful if you could comment.
It's easy, but that's it.
Recommended Posts