I tried to implement Harry Potter sort hat with CNN
background
I often hear this kind of conversation. "You really look like Slytherin." "Isn't it like Gryffindor?" "What is a huffle puff?" Certainly there are some things that can be understood. I think I said in the work that the dormitory grouping in Harry Potter is important in the first place, but if the spirit affects the body, the characteristics of the grouping will also appear in the face. Isn't it? If so, there should be a feature amount for each dormitory on the face! Good learning! Motivation such as. The following is a personal subjective grouping forecast.


And there is no malicious intent.
Execution environment
- Mac OS X 10.10.5 (Yosemite)
- Python 2.7.13_0
- Chainer 1.20.0.1_0
- Open CV 3.2.0_0 (+contrib+java+python27+qt4+vtk)
Purpose
When an image showing a person's face is input, a grouping neural network that returns the output of which dormitory the face grouping result is is constructed. There are four types of dormitories: Gryffindor, Raven Claw, Hufflepuff, and Slytherin, so the neural network is a four-class classifier. The conceptual diagram of the entire grouping neural network to be constructed is shown below.

In the next section, we will focus on data set creation and neural network model construction in learning.
Method
As mentioned for the purpose, this section describes data set creation and neural network model configuration.
Data set creation
A data set was created using the previous Image collection Python script for creating a data set used for machine learning. Collect character names and actor names belonging to each dormitory as a query. Finally, the image of the corresponding character was manually judged and stored under the directory of each dormitory. Below are some examples of collections for each dormitory.

The image size was 100 x 100 pixels, and the number of images in each dormitory was 50, for a total of 200 images. Obviously, there are many Westerners, and there is a great deal of bias depending on the character. Especially Raven Claw and Huffle Puff didn't get together at all ... too few ... Twenty randomly selected sheets were used as test data for learning.
Model configuration
Since the tasks are classified into 4 classes, I thought that it was not necessary to increase the scale so much, but I referred to some Alexnet. The model configuration is shown below.
model.py
class Model(Chain):
def __init__(self):
super(Model, self).__init__(
conv1=L.Convolution2D(3, 128, 7, stride=1),
bn2=L.BatchNormalization(128),
conv3=L.Convolution2D(128, 256, 5, stride=1),
bn4=L.BatchNormalization(256),
conv5=L.Convolution2D(256, 384, 3, stride=1),
bn6=L.BatchNormalization(384),
fc7=L.Linear(6144, 8192),
fc8=L.Linear(8192, 1024),
fc9=L.Linear(1024, 4),
)
def __call__(self, x, train=True):
h = F.max_pooling_2d(self.bn2(F.relu(self.conv1(x))), 3, stride=3)
h = F.max_pooling_2d(self.bn4(F.relu(self.conv3(h))), 3, stride=3)
h = F.max_pooling_2d(self.bn6(F.relu(self.conv5(h))), 2, stride=2)
h = F.dropout(F.relu(self.fc7(h)), train=train)
h = F.dropout(F.relu(self.fc8(h)), train=train)
y = self.fc9(h)
return y
class Classifier(Chain):
def __init__(self, predictor):
super(Classifier, self).__init__(predictor=predictor)
self.train = True
def __call__(self, x, t, train=True):
y = self.predictor(x, train)
self.loss = F.softmax_cross_entropy(y, t)
self.acc = F.accuracy(y, t)
return self.loss
The results of training using the above data set and model will be described in the next section.
result
This section describes the learning transition of the learner and the result of the implemented grouping neural network.
Model learning transition
There are a total of 200 data sets, of which 180 are learning data and 20 are test data. The transition of Error Rate (1-Accuracy Rate) of learning and testing when the number of epochs is 100 is shown below.

Since the lowest test_error was 0.15, it can be said that this model showed 85% accuracy in the 4-class classification.
Grouping neural network execution result
The result when the actual image is input to the grouping neural network incorporating the trained model is shown.


I don't know the answer, but for the time being, I was able to confirm the desired output for the input! As expected, Hiroshi Abe was grouped into Gryffindor and Ariyoshi was grouped into Slytherin, while Gacky and Becky were grouped in exactly the opposite way. But Slytherin Gacky isn't bad either. I want to be bullied. It's a little fun, so next I searched for an image that can judge a large number of people at once and entered it.
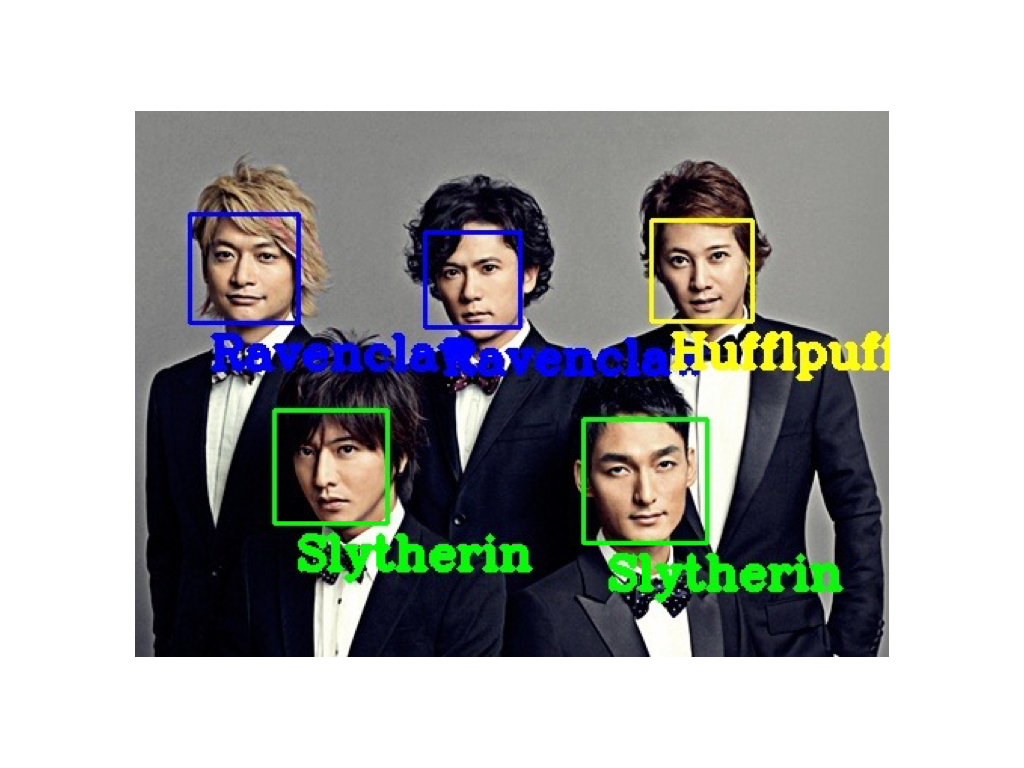
When I entered the former national idol group SMAP (Sports Music Assemble People), I got this result. Even a large number of people can go at once! Moreover, the result is quite convincing! Lol I played around with it, but it's fun because I don't have to take responsibility for accuracy because the answer isn't the answer in the first place. Below are just a few simple ways to play.
how to play
Source code for grouping neural networks: GitHub In addition, the model trained this time is placed in here. As a simple usage, you can play by putting the learned model you dropped in the cloned directory and executing the following command. Also note that the face recognition part uses OpenCV's haarcascade, so create a haarcascade directory. It is necessary to put a face recognition trained model (such as haarcascade_frontalface_default.xml) directly under it. You can rewrite the path that references the model in your code.
$ python main.py -i ImagePath -m ./LearnedModel.model -p 1
Also, as a point to note when playing, if the first face recognition is successful, the grouping result will be labeled for each face, so you have to be careful to input the image of the face that gets caught in the face recognition of OpenCV. It doesn't become. The accuracy of face recognition also depends on the trained model, so you should try various things without giving up even if you make a mistake once.
Consideration
The number of learning data greatly affects the learning results, but this time the actors in each dormitory appearing in the movie were too biased, so we could not collect a satisfactory number. Even so, the fact that the correct answer rate is as high as 85% may mean that we have grasped some characteristics of each dormitory. In terms of the number of human samples, it is not strange that the same face is included in the validation, so it seems that about 85% will be taken for granted ... In addition, although AlexNet was used as a reference for the model configuration this time, the input image is assumed to be 100 x 100, so we decided that it was not necessary to make the model with such a high degree of freedom, so we reduced the convolution layer. Furthermore, the generalization performance may have improved if the kernel made the 7x7 and 5x5 layers a little deeper. I haven't tuned it so seriously, so I can still expect an improvement in accuracy if I do a random search.
Ariyoshi was somehow satisfied with Slytherin. By the way, I was Gryffindor. I did it.
Recommended Posts