[Python] Habituez-vous à Keras lors de la mise en œuvre de l'apprentissage amélioré (DQN)
introduction
Cet article me rappelle que j'étais accro à la personnalisation des fonctions d'objectifs, à l'ajout d'optimiseurs, à plusieurs entrées, etc. tout en essayant d'implémenter l'apprentissage amélioré (DQN) à l'aide de Keras. C'est ce que j'ai laissé derrière moi. Par conséquent, il s'agit d'un article Keras Tips pour les débutants plutôt que d'un article de commentaire sur DQN.
Environnement d'exécution
Python3.5.2 Keras 1.2.1 tensorflow 0.12.1
Qu'est-ce que DQN
Cela fait plus de deux ans que DQN (DeepQ Network) a été annoncé par DeepMind, il y a donc des articles de commentaires et des exemples d'implémentation partout, donc je ne pense pas que des explications détaillées soient nécessaires ici. Je vais. En gros, cependant, il s'agit d'une méthode d'apprentissage qui permet d'estimer la valeur Q directement à partir d'une image en mouvement en se rapprochant de la partie fonction Q de la méthode d'apprentissage améliorée appelée Q-Learning par deep learning. En tant que théorie du DQN
- Renforcer l'apprentissage de zéro à profond
- Renforcer l'apprentissage à partir de Python
- J'ai essayé de confronter l'intelligence artificielle de toutes mes forces (Théorie) [Niko Niko Video]
- Histoire de DQN + Deep Q-Network écrite dans Chainer
Les articles de commentaires ici sont très polis et faciles à comprendre, alors jetez un œil là-bas. Similaire à d'autres études d'apprentissage en profondeur. La recherche sur l'apprentissage par renforcement a progressé à grands pas ces dernières années, et le DQN annoncé en 2013 n'est pas la dernière méthode, mais comme l'algorithme est simple, facile à comprendre et facile à mettre en œuvre, nous nous en occuperons cette fois.
Qu'est-ce que Keras
Keras est une bibliothèque de wrapper d'apprentissage en profondeur basée sur Theano et TensorFlow. Grâce à Theano et TensorFlow, il est devenu beaucoup plus facile d'entrer dans le deep learning, mais il est encore difficile d'écrire l'algorithme. Ainsi, Keras est une librairie qui permet d'écrire une structure de réseau assez simplement. Même les débutants en apprentissage automatique comme moi peuvent écrire du code relativement facilement. Pour ceux qui sont nouveaux dans Keras, j'ai écrit la partie de base plus tôt dans l'article Prédiction de l'onde sinusale utilisant RNN dans la bibliothèque d'apprentissage en profondeur Keras. , Si cela ne vous dérange pas, veuillez le voir.
Implémentation DQN dans Keras (Tensorflow)
Il existe de nombreux articles expliquant l'implémentation de DQN dans Keras et Tensorflow.
- Implémenter DQN (version complète) avec Tensorflow
- DQN avec l'insecte d'intelligence artificielle TensorFlow dans le jardin
- Implémenter DQN avec Keras, TensorFlow et OpenAI Gym
- Implémentation ultra-simple de DQN (Deep Q Network) avec TensorFlow ~ Introduction ~
- Écrire Reversi AI avec Keras + DQN
- Je veux que DQN Puniki frappe un home run
Donc, si vous connaissez Keras et que vous souhaitez voir l'implémentation DQN, je pense que vous devriez lire l'article ci-dessus.
De plus, la mise en œuvre de l'algorithme est bonne et je souhaite essayer rapidement un apprentissage amélioré avec Keras! Pour ceux qui le disent, il existe une bibliothèque spéciale de keras pour un apprentissage amélioré appelé keras-rl, alors jetez-y un œil. À propos de l'utilisation [Python] Apprentissage amélioré (DQN) facile à essayer avec Keras-RL Je pense que l'article de est utile.
Implémentons DQN avec Keras très simplement
J'ai fait une longue introduction, mais c'est le sujet principal. Cette fois, en m'habituant à Keras, je pense qu'il est plus facile de comprendre si je modifie ce qui a été initialement implémenté dans Tensorflow, donc j'utiliserai celui qui a déjà été implémenté et publié dans Tensorflow. Le titre du chapitre reste le même, mais ALGO GEEKS's Ultra-simple TensorFlow DQN (Deep) Essayez d'implémenter Q Network) ~ Introduction ~ J'ai emprunté le code donné dans Faire. C'est une implémentation très compacte et facile à comprendre, et comme le temps d'apprentissage est court et que les résultats peuvent être vus immédiatement, nous allons le convertir en Keras.
Le code implémenté cette fois-ci est donné dans github.
Jeu

(État après avoir tourné 1000 époque)
L'environnement d'apprentissage est très simple, et comme le montre la figure, il s'agit d'un jeu dans lequel vous attrapez les balles qui tombent l'une après l'autre dans le carré 8x8 avec la barre du bas. Lors de la mise en œuvre de cette fois, les règles ont été légèrement modifiées par rapport au site d'origine.
-
- 1 récompense pour avoir attrapé le ballon --Si vous laissez tomber la balle -1 récompense
- Trois types d'actions (1: se déplacer vers la droite, 0: ne pas bouger, -1: se déplacer vers la gauche)
- L'endroit où la balle tombe est aléatoire, l'intervalle est de 4 images --Le jeu est terminé lorsque vous laissez tomber la balle
Il est.
Récrire
Dans tensorflow
# input layer (8 x 8)
self.x = tf.placeholder(tf.float32, [None, 8, 8])
# flatten (64)
x_flat = tf.reshape(self.x, [-1, 64])
# fully connected layer (32)
W_fc1 = tf.Variable(tf.truncated_normal([64, 64], stddev=0.01))
b_fc1 = tf.Variable(tf.zeros([64]))
h_fc1 = tf.nn.relu(tf.matmul(x_flat, W_fc1) + b_fc1)
# output layer (n_actions)
W_out = tf.Variable(tf.truncated_normal([64, self.n_actions], stddev=0.01))
b_out = tf.Variable(tf.zeros([self.n_actions]))
self.y = tf.matmul(h_fc1, W_out) + b_out
# loss function
self.y_ = tf.placeholder(tf.float32, [None, self.n_actions])
self.loss = tf.reduce_mean(tf.square(self.y_ - self.y))
# train operation
optimizer = tf.train.RMSPropOptimizer(self.learning_rate)
self.training = optimizer.minimize(self.loss)
# saver
self.saver = tf.train.Saver()
# session
self.sess = tf.Session()
self.sess.run(tf.global_variables_initializer())
C'était.

Dans le DQN d'origine, après avoir pris en sandwich 3 couches Conv, Relu est appliqué par couplage complet, mais cette fois le nombre de pixels est petit à 8x8, et le calque Conv prend du temps à apprendre, donc comme ça Je pense que c'est devenu. Si vous réécrivez ceci avec Keras
self.model = Sequential()
self.model.add(InputLayer(input_shape=(8, 8)))
self.model.add(Flatten())
self.model.add(Dense(32, activation='relu'))
self.model.add(Dense(self.n_actions))
optimizer=RMSprop(lr=self.learning_rate)
self.model.compile(loss='mean_squared_error',
optimizer=optimizer,
metrics=['accuracy'])
On dirait. La meilleure chose à propos de Keras est que le code qui compose le réseau est assez simple. Vous avez maintenant un modèle qui génère 3 valeurs Q en fonction de chaque action lorsque vous entrez 8x8 pixels d'écran de jeu.
Utilisez la fonction prédire pour obtenir la valeur Q
def Q_values(self, states):
res = self.model.predict(np.array([states]))
return res[0]
C'est bon, et la partie mémoire d'expérience est
# training
self.model.fit(np.array(state_minibatch), np.array(y_minibatch), batch_size=minibatch_size,nb_epoch=1,verbose=0)
Il devient. La sauvegarde et le chargement du modèle sont
def load_model(self, model_path=None):
yaml_string = open(os.path.join(f_model, model_filename)).read()
self.model = model_from_yaml(yaml_string)
self.model.load_weights(os.path.join(f_model, weights_filename))
self.model.compile(loss='mean_squared_error',
optimizer=RMSProp(lr=self.learning_rate),
metrics=['accuracy'])
def save_model(self, num=None):
yaml_string = self.model.to_yaml()
model_name = 'dqn_model{0}.yaml'.format((str(num) if num else ''))
weight_name = 'dqn_model_weights{0}.hdf5'.format((str(num) if num else ''))
open(os.path.join(f_model, model_name), 'w').write(yaml_string)
self.model.save_weights(os.path.join(f_model, weight_name))
On dirait. C'est compact.
Étant donné que cette mise en œuvre mettait l'accent sur la clarté et la compacité, il existe quelques différences par rapport au DQN d'origine.
--Il n'y a pas de réseau cible
- Pas d'écrêtage avec fonction de perte
- N'utilisez pas de convolution dans le réseau
- J'utilise RMS Prop normal comme optimiseur, pas RMS Prop Graves recommandé par DQN
- (Commencez à apprendre après avoir rempli la mémoire de relecture)
- (Diminuez au hasard le taux de sélection d'action de 1 quelle que soit la valeur Q)
Cette fois, je vais vous expliquer ces points et les points que je suis resté bloqué lors de la mise en œuvre avec Keras.
Conseils 1: Copiez le modèle
Dans DQN, afin de ne pas surestimer l'action sélectionnée, une mesure est prise pour séparer le modèle utilisé lors de l'exécution de la mémoire d'expérience (évaluation de l'action) et lors de la sélection de la sélection d'action. Dans l'article original [1], les deux utilisaient le même modèle, et dans l'article de 2015 [2] publié dans la nature, les deux étaient séparés et un nouveau réseau cible a été introduit. Cela créera un signal enseignant en utilisant les anciens paramètres, l'explication ici est
introduction to double deep Q-learning
Il est expliqué d'une manière très facile à comprendre, alors jetez-y un œil.
Du côté de l'implémentation, une fois toutes les quelques images, vous devez copier le modèle utilisé pour la sélection des actions et le transmettre au modèle cible. Que faire avec Keras
from keras.models import model_from_config
def clone_model(model, custom_objects={}):
config = {
'class_name': model.__class__.__name__,
'config': model.get_config(),
}
clone = model_from_config(config, custom_objects=custom_objects)
clone.set_weights(model.get_weights())
return clone
self.target_model = clone_model(self.model)
Vous pouvez copier en transmettant le modèle et le poids au nouveau modèle, respectivement.
cependant,
import copy
self.target_model = copy.copy(self.model)
##deepcopy génère une erreur
# self.target_model = copy.deepcopy(self.model)
Il semble que le modèle et les paramètres soient copiés même avec la fonction de copie standard (je ne pouvais pas le trouver officiellement), mais le comportement est un peu effrayant, donc la méthode précédente est meilleure.
Cette fois, clone_model est utilisé pour copier périodiquement le modèle actuel dans target_model, et target_model est utilisé lors de l'évaluation et de la mise à jour de la valeur Q. (En passant, dans la version améliorée de DQN, DDQN, la valeur Q obtenue en plaçant l'état dans le modèle cible correspond à A à la recherche de `` l'action qui prend la valeur Q maximale obtenue en mettant l'état dans le modèle courant '' (A). J'utilise ce que je fais)
def Q_values(self, states, isTarget=False):
model = self.target_model if isTarget else self.model
res = model.predict(np.array([states]))
return res[0]
def store_experience(self, states, action, reward, states_1, terminal):
self.D.append((states, action, reward, states_1, terminal))
return (len(self.D) >= self.replay_memory_size)
def experience_replay(self):
state_minibatch = []
y_minibatch = []
action_minibatch = []
# sample random minibatch
minibatch_size = min(len(self.D), self.minibatch_size)
minibatch_indexes = np.random.randint(0, len(self.D), minibatch_size)
for j in minibatch_indexes:
state_j, action_j, reward_j, state_j_1, terminal = self.D[j]
action_j_index = self.enable_actions.index(action_j)
y_j = self.Q_values(state_j)
if terminal:
y_j[action_j_index] = reward_j
else:
if not self.use_ddqn:
v = np.max(self.Q_values(state_j_1, isTarget=True))
else: # for DDQN
v = self.Q_values(state_j_1, isTarget=True)[action_j_index]
y_j[action_j_index] = reward_j + self.discount_factor * v
state_minibatch.append(state_j)
y_minibatch.append(y_j)
action_minibatch.append(action_j_index)
# training
self.model.fit(np.array(state_minibatch), np.array(y_minibatch), verbose=0)
Tips2: Personnalisation de la fonction de perte
Dans l'exemple précédent, nous avons simplement utilisé'mean_squared_error ', mais dans DQN, afin d'améliorer la stabilité de l'apprentissage, la valeur de l'erreur' target - Q (s, a; θ) 'est modifiée de -1 à 1. Clip dans la gamme de. Cette zone
Implémentation de DQN avec Keras, TensorFlow et OpenAI Gym
Il est expliqué d'une manière très facile à comprendre, alors jetez-y un œil.
Keras fournit plusieurs types de fonctions de perte par défaut, et vous pouvez les utiliser simplement en écrivant un nom comme `` mean_squared_error '', mais il y a des moments où vous voulez définir votre propre fonction de perte comme cette fois.
Bien sûr, Keras a un moyen de le faire (même si c'est un peu délicat).
def loss_func(y_true, y_pred):
error = tf.abs(y_pred - y_true)
quadratic_part = tf.clip_by_value(error, 0.0, 1.0)
linear_part = error - quadratic_part
loss = tf.reduce_sum(0.5 * tf.square(quadratic_part) + linear_part)
return loss
self.model.compile(loss=loss_func, optimizer='rmsprops', metrics=['accuracy'])
Vous pouvez définir votre propre fonction de perte comme ceci (y_true est les données de l'enseignant et y_pred est la sortie du modèle). Cette fonction est utilisée lors de l'appel de model.fit ou model.evaluate.
[Référence] Comment utiliser une fonction d'objectif personnalisée pour un modèle? # 369
C'est un peu délicat car il est très difficile d'introduire des paramètres externes autres que y_true et y_pred dans la fonction de perte.
Dans cet exemple, comme valeur à affecter à y_true dans la mémoire d'expérience, la liste de valeurs Q de sortie du modèle actuel est affectée telle quelle (seule la pièce avec mise à jour est mise à jour) ([1.2, 0.5, 0.1] -> [1.3". , 0.5, 0.1] ), La différence de valeur absolue par rapport à la liste de valeurs Q de sortie du modèle actuel est prise dans la fonction de perte. Par conséquent, dans ʻerror, la valeur ne reste que dans la partie mise à jour, et les autres sont 0 ([1,3, 0,5, 0,1] - [1,2, 0,5, 0,1] = [0,1, 0, 0]`. ). En fin de compte, seule la pièce mise à jour affecte la valeur de la perte et aucune autre variable externe n'est nécessaire.
Cependant, transmettez le signal de l'enseignant (valeur de mise à jour uniquement) («1.3»), la sortie du modèle («[1.2, 0.5, 0.1]») et l'action de sélection («0») à la fonction de perte, et calculez la valeur de perte à partir de celles-ci dans le modèle. Dès que vous essayez de calculer, cela devient gênant. Dans Tensorflow
state = tf.placeholder(tf.float32, [None, 8, 8]) #Statut
a = tf.placeholder(tf.int64, [None]) #action
supervisor = tf.placeholder(tf.float32, [None]) #Signal de l'enseignant
output = self.inference(state)
loss = lossfunc(output, supervisor)
...
loss_val = sess.run(loss, feed_dict={
self.state: np.float32(np.array(state_batch),
self.action: action_batch,
self.super_visor: y_batch
})
def lossfunc(self, a, output, supervisor)
a_one_hot = tf.one_hot(a, self.num_actions, 1.0, 0.0) #Convertir le comportement en un vecteur chaud
q_value = tf.reduce_sum(tf.mul(output, a_one_hot), reduction_indices=1) #Calcul de la valeur Q du comportement
#Clip d'erreur
error = tf.abs(supervisor - q_value)
quadratic_part = tf.clip_by_value(error, 0.0, 1.0)
linear_part = error - quadratic_part
loss = tf.reduce_mean(0.5 * tf.square(quadratic_part) + linear_part) #Fonction d'erreur
C'est très simple, mais cela ne fonctionne pas dans Keras. Ce qu'il faut faire est de créer un modèle qui prend y_true, y_pred et d'autres fonctions externes comme entrées et génère la valeur de perte.
Tips3: plusieurs entrées, plusieurs sorties
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers import Lambda, Input
losses = {'loss': lambda y_true, y_pred: y_pred, #dummy loss func
'main_output': lambda y_true, y_pred: K.zeros_like(y_pred)}
def customized_loss(args):
import tensorflow as tf
y_true, y_pred, action = args
a_one_hot = tf.one_hot(action, K.shape(y_pred)[1], 1.0, 0.0)
q_value = tf.reduce_sum(tf.mul(y_pred, a_one_hot), reduction_indices=1)
error = tf.abs(q_value - y_true)
quadratic_part = tf.clip_by_value(error, 0.0, 1.0)
linear_part = error - quadratic_part
loss = tf.reduce_sum(0.5 * tf.square(quadratic_part) + linear_part)
return loss
...
def init_model(self):
state_input = Input(shape=(1, 8, 8), name='state')
action_input = Input(shape=[None], name='action', dtype='int32')
x = Flatten()(state_input)
x = Dense(32, activation='relu')(x)
y_pred = Dense(3, activation='linear', name='main_output')(x)
y_true = Input(shape=(1, ), name='y_true')
loss_out = Lambda(customized_loss, output_shape=(1, ), name='loss')([y_true, y_pred, action_input])
self.model = Model(input=[state_input, action_input, y_true], output=[loss_out, y_pred])
self.model.compile(loss=losses,
optimizer=RMSprop(lr=self.learning_rate),
metrics=['accuracy'])
slef.init_model()
...
res = model.predict({'state': np.array([states]),
'action': np.array([0]), #dummy
'y_true': np.array([[0] * self.n_actions]) #dummy
})
return res[1][0]
...
self.model.fit({'action': np.array(action_minibatch),
'state': np.array(state_minibatch),
'y_true': np.array(y_minibatch)},
[np.zeros([minibatch_size]),
np.array(y_minibatch)],
batch_size=minibatch_size,
nb_epoch=1,
verbose=0)
... extrêmement gênant. Keras a un mécanisme assez simple par défaut, mais si vous essayez de faire quelque chose qui s'écarte de cela, cela deviendra immédiatement gênant.
Ce qui a changé, c'est que
--Une nouvelle action_input a été ajoutée à l'entrée --y_true est également traité comme une entrée (trois entrées) --Lambda utilisé pour la définition de la couche originale est utilisé pour calculer la perte --La valeur de perte et la valeur Q sont sorties en sortie.
C'est un point. C'est dur. Ceci est inévitable tant qu'il n'est pas possible de faire des personnalisations majeures telles que la modification des arguments de la fonction de perte. À propos, cette méthode est décrite dans l'exemple officiel de Keras (https://github.com/fchollet/keras/blob/master/examples/image_ocr.py).
Comme un point
- En utilisant Lambda, vous pouvez concevoir librement l'entrée, le traitement dans la couche et la forme de la sortie. --L'entrée et la sortie sont nommées en utilisant le nom et sont utilisées pour la prédiction et l'ajustement.
- Lorsqu'il y a plusieurs sorties, la fonction de perte peut être appliquée à chacune.
- Puisque la valeur de perte est incluse dans la sortie du modèle, la fonction de perte spécifiée dans model.compile peut être une valeur fictive, la fonction à appliquer à la valeur de perte produit la valeur telle qu'elle est et la fonction à appliquer à la valeur Q renvoie toujours 0. Il est devenu. --Spécifiez une valeur fictive pour l'entrée qui n'est pas utilisée lors de l'appel de predict (inutile?), Et traitez le signal de l'enseignant comme une entrée lors de l'appel de fit.
Quel endroit, comme. Pour être honnête, il existe une théorie selon laquelle il vaut mieux utiliser Tensorflow que d'écrire comme ça, mais si vous écrivez uniquement avec Keras, en sera-t-il ainsi? Vous pouvez également utiliser Keras pour l'ensemble de modèles et Tensorflow pour le reste.
Tips4: Changer d'optimiseur
Comme l'article est devenu plus long que prévu, je vais omettre une explication détaillée (peut-être l'ajouterai-je plus tard?), Mais dans DQN, on dit que les performances sont susceptibles de sortir si RMS Prop Graves est utilisé comme optimiseur au lieu de l'habituel RMS Prop. Je suis un débutant en apprentissage automatique, donc je ne sais pas pourquoi c'est plus rapide quand je regarde la formule (s'il vous plaît dites-moi ...), mais si c'est plus rapide à apprendre, je veux vraiment l'utiliser (sauf pour les papiers DQN + RNN, etc.) Il semble que vous utilisez l'optimiseur de). Cependant, bien que ce RMS PopsGraves soit inclus dans Chainer par défaut, il n'est pas inclus dans Tensorflow et Keras (je ne l'ai pas essayé, mais il est peut-être possible de l'utiliser avec Keras en arrière-plan Chainer). Par conséquent, vous devez implémenter vous-même l'optimiseur. Version Tensorflow
Implémentation de DQN (version complète) avec Tensorflow
Veuillez vous référer à l'explication détaillée ici. Il peut être implémenté en regardant la formule dans l'article [3].
La différence de transition de la valeur de perte lorsque l'époque est répétée est la suivante.
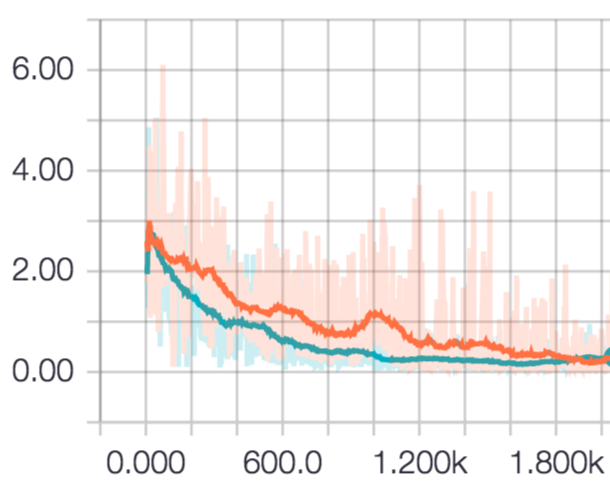
Le rouge est RMSProp et le bleu est RMSPropGraves. Au début, RMS PopGraves semblait être supérieur, mais après avoir tourné 2000 fois, les deux se sont installés au même niveau. C'est peut-être parce que la tâche était facile.
Dans Keras, la définition de l'optimiseur se trouve entièrement dans https://github.com/yukiB/keras/blob/master/keras/optimizers.py, il semble donc bon de la réécrire. Concernant WIP, je vais donner le code à github.
Essayez dans un jeu un peu plus compliqué
Puisque les performances du modèle Oita auraient dû s'améliorer jusqu'à présent, augmentons le nombre de pixels et ajoutons trois couches Conv avant le couplage complet.

Le résultat de tourner 1000 fois est le suivant.

Ensuite, faisons un jeu un peu plus compliqué et utilisons le même modèle pour l'apprentissage. J'ai facilement implémenté un jeu appelé CAVE, auquel j'ai beaucoup joué à l'époque Garakei, avec matplotlib. Il s'agit d'un jeu dans lequel le gars qui monte lorsque le bouton est enfoncé et qui descend lorsque le bouton est relâché est avancé pour ne pas frapper le mur autant que possible.
L'écran de jeu est de 48x48, utilisant le réseau (couche Conv3 + Relu entièrement connecté) créé précédemment,
--Entrée: sous-échantillonné les 4 dernières images
- Sortie: entrée de bouton (ON, OFF)
Je l'ai fait ainsi.
En conséquence, j'ai rarement frappé les murs supérieurs et inférieurs, mais je n'ai pas beaucoup appris sur la manière d'éviter les blocages en cours de route et mon score ne s'est pas amélioré. Pour le moment, 4 trames sont prises comme données d'entrée, mais il est possible que des données de trame plus rétroactives soient efficaces en fonction de la relation de position entre les blocs, il peut donc être préférable de considérer DQN etc. combiné avec LSTM. ne pas. J'en reparlerai la prochaine fois

(C'est dangereux car le temps s'est écoulé indéfiniment rien qu'en regardant les résultats d'apprentissage)
en conclusion
Cette fois, lors de la construction d'un DQN avec Keras, j'ai choisi les endroits où les débutants sont susceptibles de trébucher. J'ai eu affaire à DQN cette fois parce que c'était mon premier apprentissage de renforcement, mais je suis assez en retard (la combinaison DDQN et LSTM est toujours active), donc la prochaine fois, j'aimerais utiliser A3C, etc. Je pense.
Le code pour cette heure peut être trouvé à ici.
Les références
[1] V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves I. Antonoglou, D. Wierstra, M. Riedmiller. “Playing Atari with Deep Reinforcement Learning” arXiv:1312.5602, 2013. [2] V. Mnih, et al. “Human-level control through deep reinforcement learning” nature, 2015. [3] Alex Graves, “Generating Sequences With Recurrent Neural Networks” arXiv preprint arXiv http://arxiv.org/abs/1308.0850
Recommended Posts