Arbre de décision (load_iris)
■ Présentation
Cette fois, nous résumerons le diagramme d'implémentation de l'arbre de décision.
[Lecteurs cibles]
・ Ceux qui veulent apprendre le code de base dans l'arbre de décision
・ Je ne connais pas la théorie en détail, mais ceux qui veulent voir l'implémentation et donner une image, etc.
1. Préparation du module
Tout d'abord, importez les modules requis.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import plot_tree
## 2. Préparation des données Utilisez le jeu de données load_iris.
iris = load_iris()
X, y = iris.data[:, [0, 2]], iris.target
print(X.shape)
print(y.shape)
# (150, 2)
# (150,)
Divisez en données de train et de test.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 123)
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_train.shape)
# (105, 2)
# (105,)
# (45, 2)
# (45,)
Dans l'arbre de décision, les caractéristiques individuelles sont traitées indépendamment et la division des données est indépendante de l'échelle.
Aucune normalisation ou standardisation n'est requise.
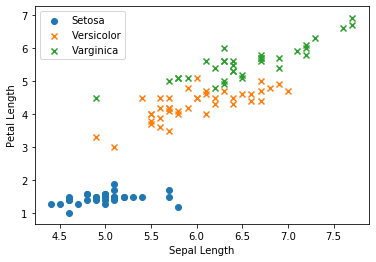
3. Visualisation des données
Avant de modéliser, traçons les données.
fig, ax = plt.subplots()
ax.scatter(X_train[y_train == 0, 0], X_train[y_train == 0, 1],
marker = 'o', label = 'Setosa')
ax.scatter(X_train[y_train == 1, 0], X_train[y_train == 1, 1],
marker = 'x', label = 'Versicolor')
ax.scatter(X_train[y_train == 2, 0], X_train[y_train == 2, 1],
marker = 'x', label = 'Varginica')
ax.set_xlabel('Sepal Length')
ax.set_ylabel('Petal Length')
ax.legend(loc = 'best')
plt.show()
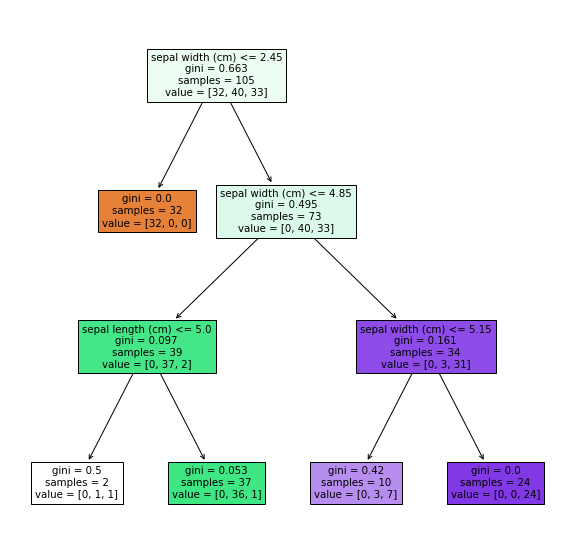
4. Créez un modèle
Créez un modèle de l'arbre de décision.
tree = DecisionTreeClassifier(max_depth = 3)
tree.fit(X_train, y_train)
'''
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=3, max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort='deprecated',
random_state=None, splitter='best')
'''
En même temps, je vais également le visualiser.
fig, ax = plt.subplots(figsize=(10, 10))
plot_tree(tree, feature_names=iris.feature_names, filled=True)
plt.show()
5. Sortie de la valeur prévue
Faites des prédictions pour les données de test.
y_pred = tree.predict(X_test)
print(y_pred[:10])
print(y_test[:10])
# [2 2 2 1 0 1 1 0 0 1]
# [1 2 2 1 0 2 1 0 0 1]
0:Setosa 1:Versicolor 2:Verginica
6. Évaluation des performances
Trouvez le taux de réponse correct dans cette prédiction de classification.
print('{:.3f}'.format(tree.score(X_test, y_test)))
# 0.956
## ■ Enfin Cette fois, en nous basant sur les étapes 1 à 6 ci-dessus, nous avons créé et évalué un modèle de l'arbre de décision. Nous espérons qu'il sera utile aux débutants.
## ■ Références ・ [Nouveau manuel d'analyse de données utilisant Python](https://www.shoeisha.co.jp/book/detail/9784798158341)
Recommended Posts