Arbre de décision et forêt aléatoire
Qu'est-ce qu'un arbre de décision?
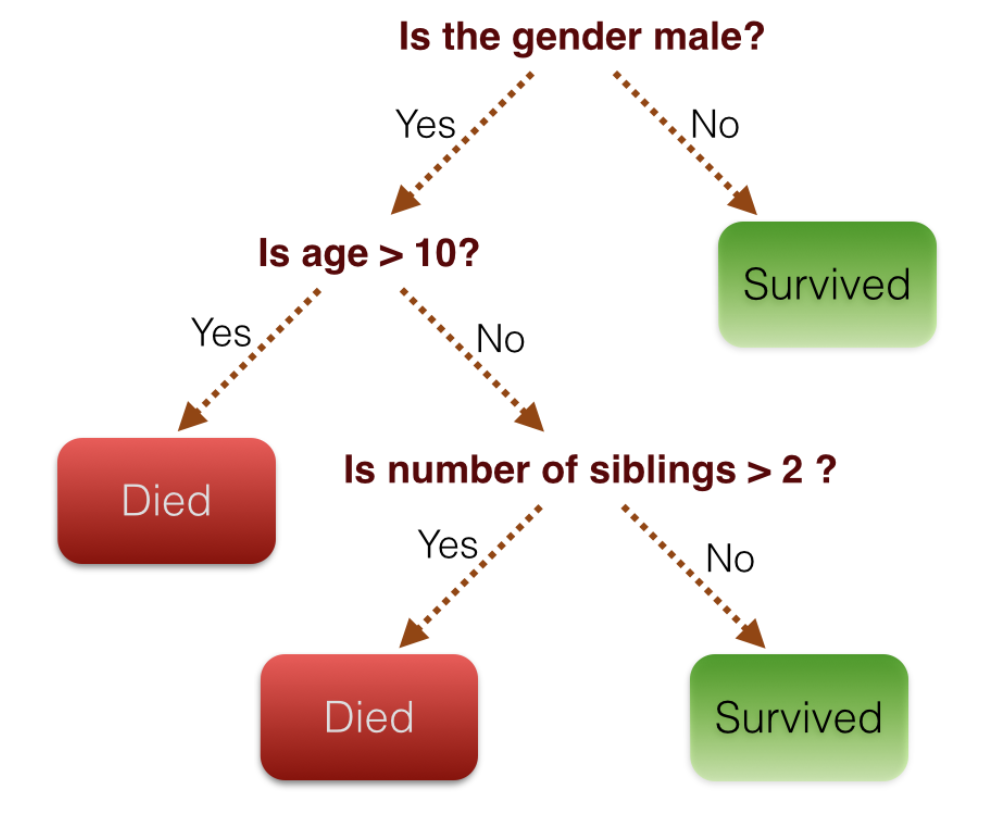
Méthode de calcul de la probabilité d'appartenance à la variable objective en combinant plusieurs variables explicatives. L'image ci-dessous calcule la probabilité en fonction de son appartenance à des conditions telles que Oui / Non.
Qu'est-ce que Random Forest?
Random Forest est l'une des méthodes d'apprentissage d'ensemble (classificateurs composés en collectant plusieurs classificateurs). Étant donné que plusieurs arbres de décision sont collectés et utilisés, les arbres sont collectés et utilisés comme forêt.
Essayez-le (arbre de décision dans sklearn)
Données prêtes
Préparez des données créées au hasard.
{get_dummy_dataset.py}
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn
%matplotlib inline
from sklearn.datasets import make_blobs #Pour générer des données factices
X, y = make_blobs(n_samples=500, centers=4, random_state=8, cluster_std=2.4)
# n_samples:Nombre de centres d'échantillonnage:Nombre de points centraux aléatoire_state:cluster de valeurs de départ_std:Degré de variation
Aperçu des données
{display_dummy_dataset.py}
plt.figure(figsize =(10,10))
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='jet')
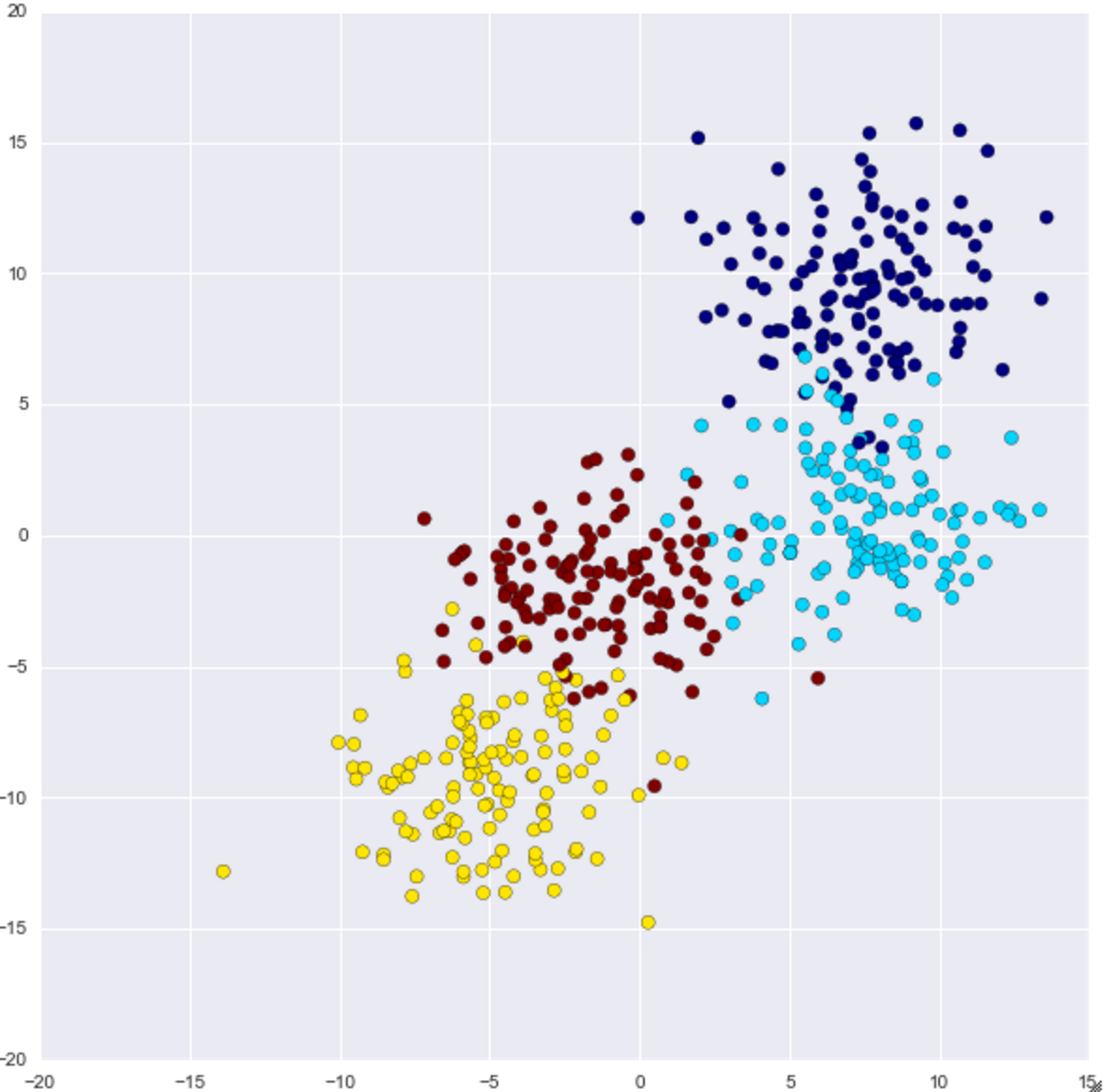
La distribution de 500 données générées à partir des quatre points centraux ressemble à ceci.
Essayez l'arbre de décision
Le code de visualize_tree est écrit en bas.
{do_decision_tree.py}
from sklearn.tree import DecisionTreeClassifier #Pour l'arbre de décision
clf = DecisionTreeClassifier(max_depth=2, random_state = 0) #Création d'instance max_depth:Profondeur de l'arbre
visualize_tree(clf, X, y) #Exécution de dessin
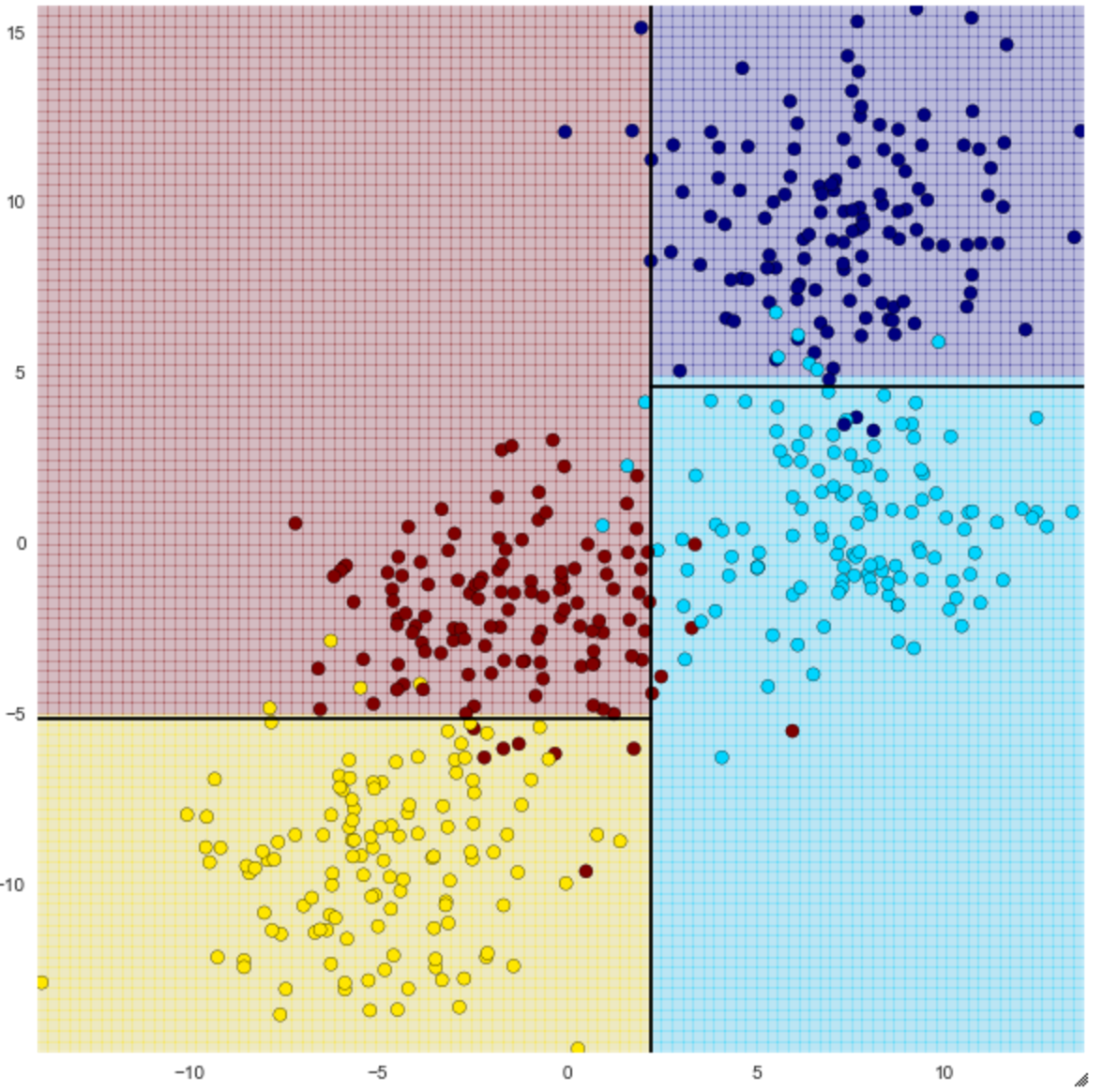
Vous pouvez voir comment il peut être classé en quatre en utilisant des lignes droites. La précision change en fonction du nombre de profondeurs (max_depth) de l'arbre de décision, donc quand j'ai mis max_depth à 4, c'est devenu comme suit.
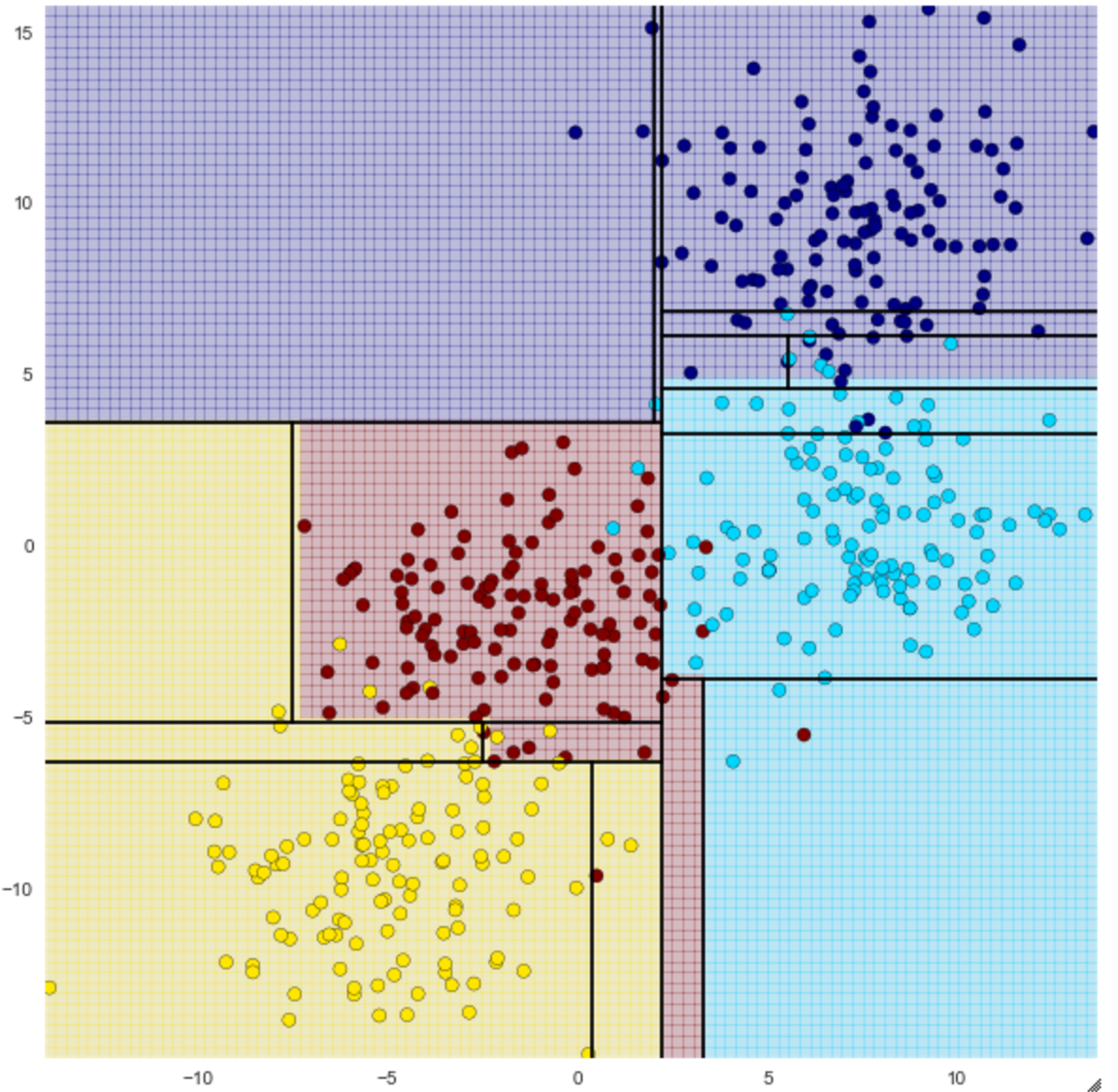
De la profondeur 2, vous pouvez voir que vous essayez de faire une classification plus fine.
Cependant, plus la profondeur est élevée, plus la précision des données d'entraînement est élevée, mais plus il est facile de surapprendre. Pour éviter cela, essayez d'exécuter une forêt aléatoire.
Essayez une forêt aléatoire
{do_random_forest.py}
from sklearn.ensemble import RandomForestClassifier #Pour la forêt aléatoire
clf = RandomForestClassifier(n_estimators=100, random_state=0) #Création d'instance n_estimators:Spécifier le nombre d'arbres de décision à faire
visualize_tree(clf, X, y, boundaries=False)
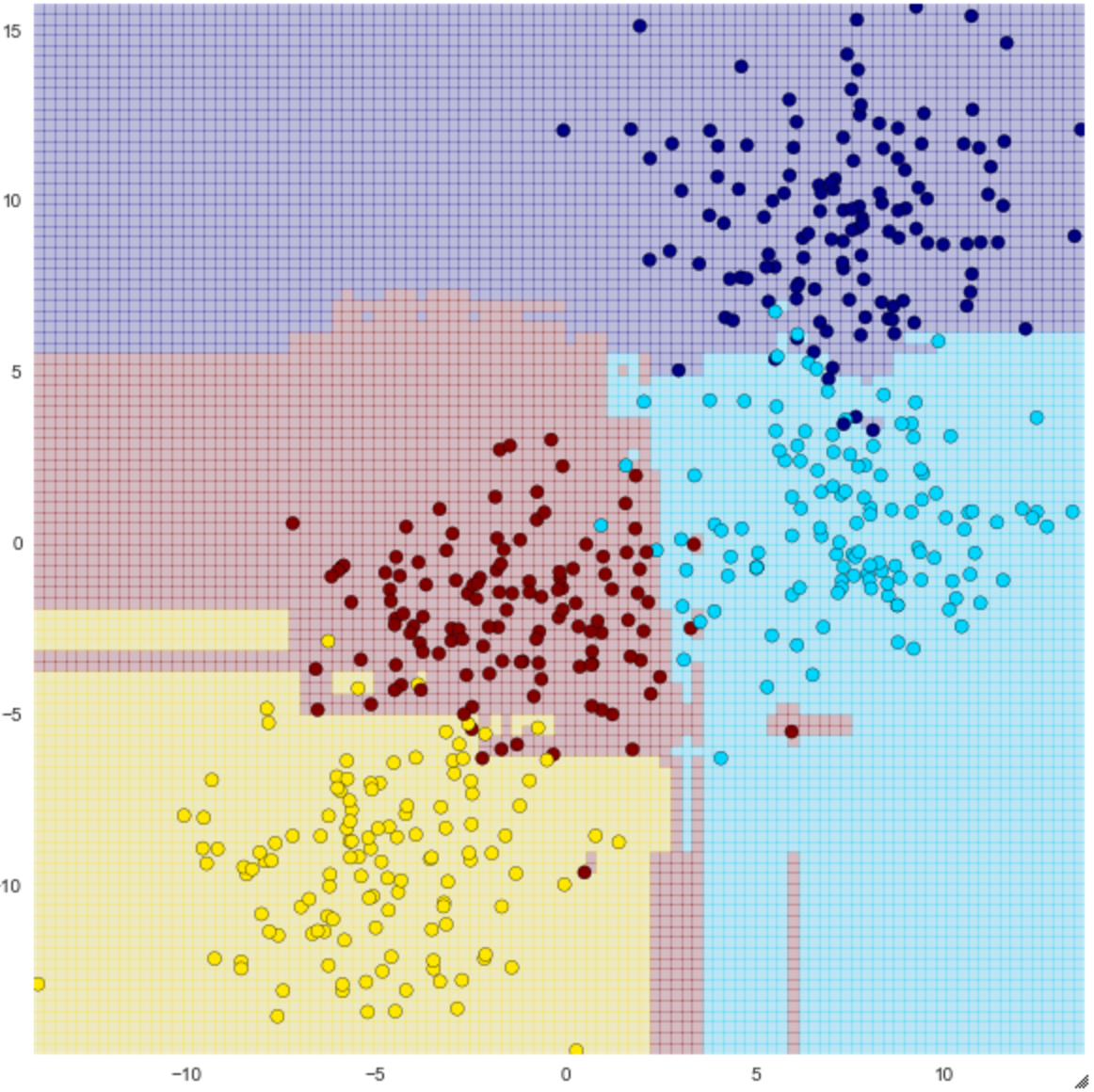
On peut voir que la classification n'est pas une simple ligne droite, mais elle semble être plus précise qu'un arbre de décision. Soit dit en passant, cela n'empêche pas toujours le surapprentissage: par exemple, le cercle rouge en bas à droite de la figure ci-dessus semble être hors de valeur, mais il est groupé en rouge.
Une fonction qui visualise le résultat.
{visualize_tree.py}
#Essayez de dessiner un arbre de décision
def visualize_tree(classifier, X, y, boundaries=True,xlim=None, ylim=None):
"""Fonction de visualisation de l'arbre de décision.
INPUTS:Modèle de classification, X, y, optional x/y limits.
OUTPUTS:Visualisation des arbres de décision à l'aide de Meshgrid
"""
#Construire un modèle à l'aide de l'ajustement
classifier.fit(X, y)
#Réglage automatique de l'axe
if xlim is None:
xlim = (X[:, 0].min() - 0.1, X[:, 0].max() + 0.1)
if ylim is None:
ylim = (X[:, 1].min() - 0.1, X[:, 1].max() + 0.1)
x_min, x_max = xlim
y_min, y_max = ylim
#Créez une grille maillée.
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 100),np.linspace(y_min, y_max, 100))
#Effectuer des prédictions de classificateur
Z = classifier.predict(np.c_[xx.ravel(), yy.ravel()])
#Façonné à l'aide de meshgrid.
Z = Z.reshape(xx.shape)
#Coloré par classification.
plt.figure(figsize=(10,10))
plt.pcolormesh(xx, yy, Z, alpha=0.2, cmap='jet')
#Dessiner des données d'entraînement.
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='jet')
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
def plot_boundaries(i, xlim, ylim):
'''
Dessinez une bordure.
'''
if i < 0:
return
tree = classifier.tree_
#Appelez récursivement pour tracer les limites.
if tree.feature[i] == 0:
plt.plot([tree.threshold[i], tree.threshold[i]], ylim, '-k')
plot_boundaries(tree.children_left[i], [xlim[0], tree.threshold[i]], ylim)
plot_boundaries(tree.children_right[i], [tree.threshold[i], xlim[1]], ylim)
elif tree.feature[i] == 1:
plt.plot(xlim, [tree.threshold[i], tree.threshold[i]], '-k')
plot_boundaries(tree.children_left[i], xlim,
[ylim[0], tree.threshold[i]])
plot_boundaries(tree.children_right[i], xlim,
[tree.threshold[i], ylim[1]])
if boundaries:
plot_boundaries(0, plt.xlim(), plt.ylim())
Essayez une régression dans une forêt aléatoire
Les forêts aléatoires peuvent également revenir.
Utilisez sin pour préparer des données qui font bouger les petites vagues en grandes vagues
{get_dummy_malti_sin_dataset.py}
from sklearn.ensemble import RandomForestRegressor
x = 10 * np.random.rand(100)
def sin_model(x, sigma=0.2):
"""Données factices constituées de grosses vagues + petites vagues + bruit."""
noise = sigma * np.random.randn(len(x))
return np.sin(5 * x) + np.sin(0.5 * x) + noise
#Calculer y à partir de x
y = sin_model(x)
#Essayez Plot.
plt.figure(figsize=(16,8))
plt.errorbar(x, y, 0.1, fmt='o')
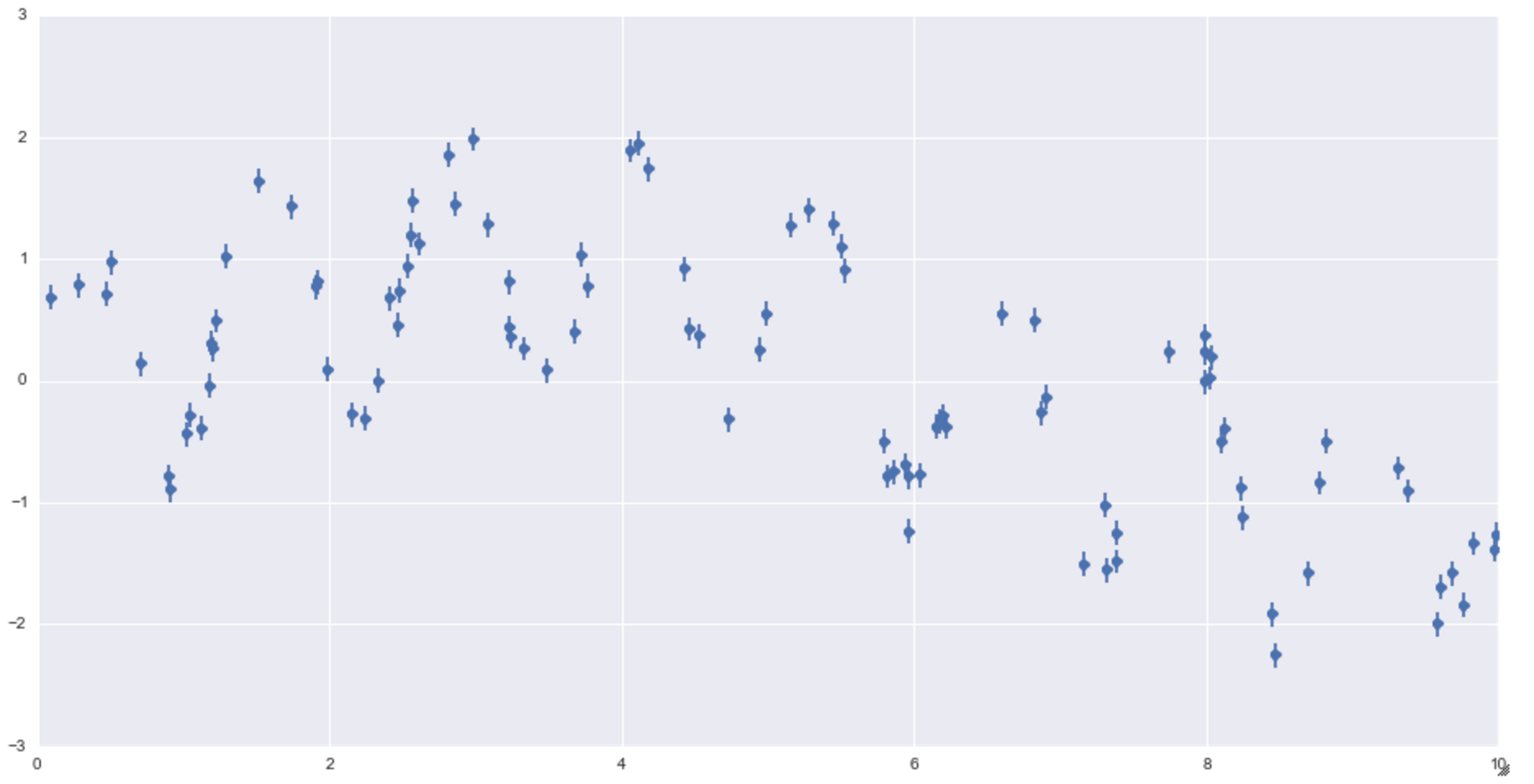
Données factices ondulées. Il diminue petit à petit.
Courir avec sklearn
{do_random_forest_regression.py}
from sklearn.ensemble import RandomForestRegressor #Pour la régression forestière aléatoire
#Préparez 1000 données de 0 à 10 pour confirmation
xfit = np.linspace(0, 10, 1000) #1000 pièces de 0 à 10
#Exécution aléatoire de la forêt
rfr = RandomForestRegressor(100) #Génération d'instance Spécifiez le nombre d'arbres à 100
rfr.fit(x[:, None], y) #Exécution de l'apprentissage
yfit = rfr.predict(xfit[:, None]) #Exécution prédictive
#Obtenez la valeur réelle pour la comparaison des résultats.
ytrue = sin_model(xfit,0) #Envoyez xfit à la fonction de génération d'onde et obtenez le résultat
#Vérifiez le résultat
plt.figure(figsize = (16,8))
plt.errorbar(x, y, 0.1, fmt='o')
plt.plot(xfit, yfit, '-r') #Tracé prédit
plt.plot(xfit, ytrue, '-k', alpha = 0.5) #Diagramme de réponse correct
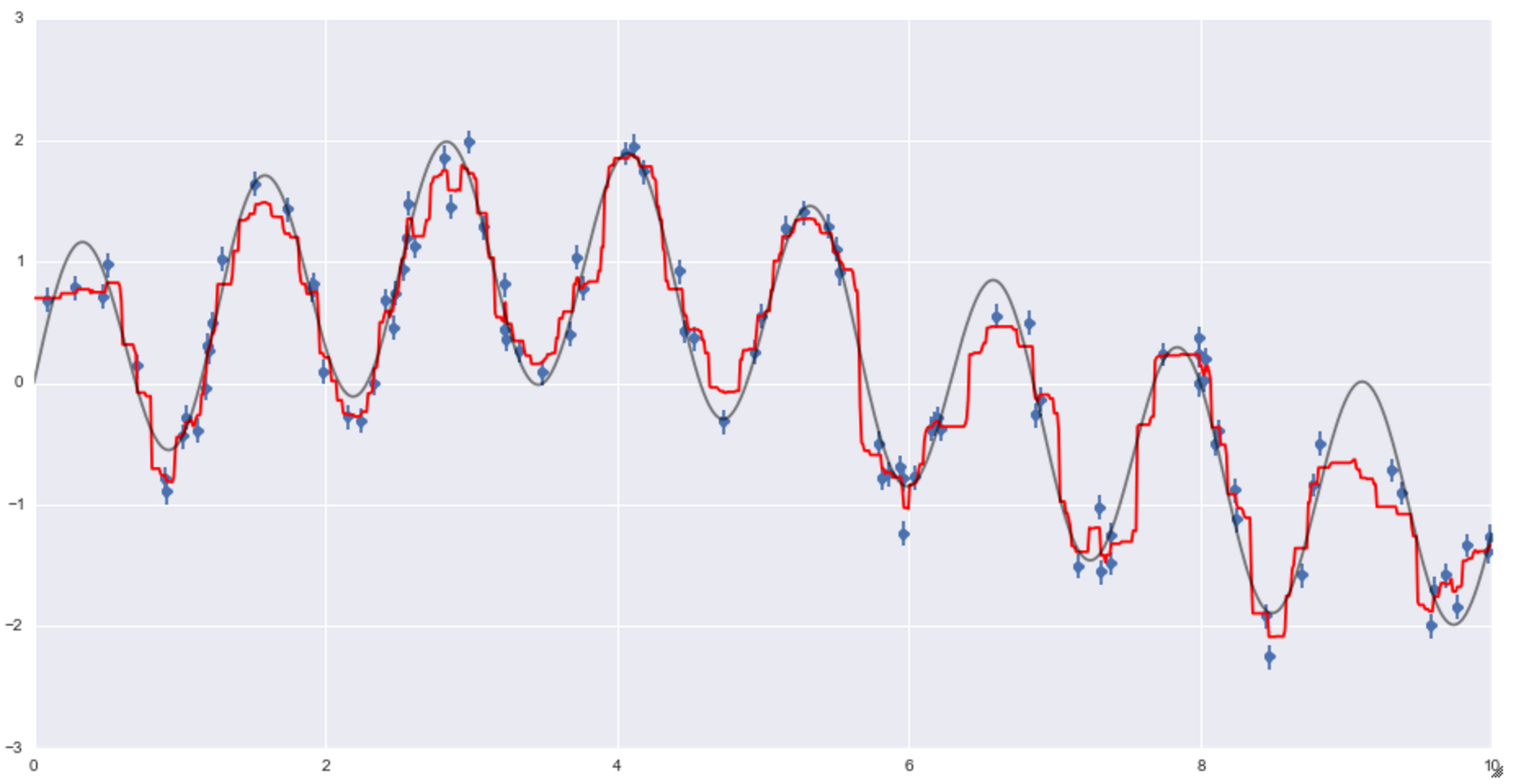
Vous pouvez voir que la ligne rouge est la ligne de régression de la prédiction, et le résultat semble être raisonnablement bon.
Recommended Posts