Arbre de décision (pour les débutants) -Édition de code-
Cette fois, nous résumerons la mise en œuvre de l'arbre de décision (classification).
■ Procédure de l'arbre de décision
Passez aux 7 étapes suivantes.
- Préparation du module
- Préparation des données
- Visualisation des données
- Créez un modèle
- Diagramme du modèle
- Classification des prédictions
- Évaluation du modèle
1. Préparation du module
Tout d'abord, importez les modules requis.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#Module pour lire le jeu de données
from sklearn.datasets import load_iris
#Module de normalisation (normalisation distribuée)
from sklearn.preprocessing import StandardScaler
#Module qui sépare les données d'entraînement et les données de test
from sklearn.model_selection import train_test_split
#Module qui exécute l'arbre de décision
from sklearn.tree import DecisionTreeClassifier
#Module pour tracer l'arbre de décision
from sklearn.tree import plot_tree
2. Préparation des données
Cette fois, nous utiliserons le jeu de données iris pour classer trois types.
Obtenez d'abord les données, standardisez-les, puis divisez-les.
#Chargement du jeu de données iris
iris = load_iris()
#Diviser en variable objective et variable explicative (montant de la fonction)
X, y = iris.data[:, [0, 2]], iris.target
#Standardisation (normalisation distribuée)
std = StandardScaler()
X = std.fit_transform(X)
#Divisez en données d'entraînement et données de test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 123)
Pour faciliter le tracé, nous avons réduit les fonctionnalités à deux. (Longueur sépale / Longueur pétale uniquement)
En normalisation, par exemple, lorsqu'il y a des quantités de caractéristiques à 2 et 4 chiffres (variables explicatives), l'influence de ces dernières devient grande. L'échelle est alignée en définissant la moyenne sur 0 et la variance sur 1 pour toutes les quantités d'entités.
Dans random_state, la valeur de départ est fixe et le résultat de la division des données est défini pour être le même à chaque fois.
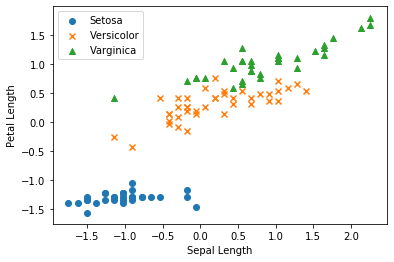
3. Visualisation des données
Tracons les données avant de les classer par SVM.
#Création d'objets de dessin et de sous-tracés
fig, ax = plt.subplots()
#Graphique de Setosa
ax.scatter(X_train[y_train == 0, 0], X_train[y_train == 0, 1],
marker = 'o', label = 'Setosa')
#Parcelle Versicolor
ax.scatter(X_train[y_train == 1, 0], X_train[y_train == 1, 1],
marker = 'x', label = 'Versicolor')
#Parcelle Varginica
ax.scatter(X_train[y_train == 2, 0], X_train[y_train == 2, 1],
marker = 'x', label = 'Varginica')
#Paramètres d'étiquette d'axe
ax.set_xlabel('Sepal Length')
ax.set_ylabel('Petal Length')
#Paramètres de la légende
ax.legend(loc = 'best')
plt.show()
Tracé avec des entités correspondant à Setosa (y_train == 0) (0: Sepal Length sur l'axe horizontal, 1: Petal Length sur l'axe vertical) Tracé avec des entités (0: Sepal Lengh sur l'axe horizontal, 1: Petal Length sur l'axe vertical) correspondant à Versicolor (y_train == 1) Tracé avec des entités (0: Sepal Lengh sur l'axe horizontal, 1: Petal Length sur l'axe vertical) correspondant à Varginica (y_train == 2)
Résultat de sortie
4. Créez un modèle
Tout d'abord, créez une fonction d'exécution (instance) de l'arbre de décision et appliquez-la aux données d'apprentissage.
#Créer une instance
tree = DecisionTreeClassifier(max_depth = 3)
#Créer un modèle à partir des données d'entraînement
tree.fit(X_train, y_train)
max_depth est un hyper paramètre
Vous pouvez l'ajuster vous-même tout en regardant les valeurs de sortie et les graphiques.
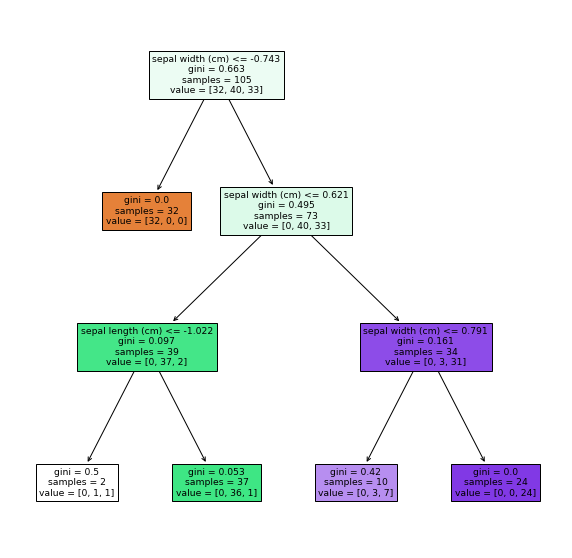
5. Diagramme du modèle
Depuis que j'ai pu créer un modèle de l'arbre de décision à partir des données d'entraînement Tracez et vérifiez comment la classification est effectuée.
#Définir la taille du tracé
fig, ax = plt.subplots(figsize=(10, 10))
# plot_Utilisez la méthode tree (arguments: instance de l'arbre de décision, liste des fonctionnalités)
plot_tree(tree, feature_names=iris.feature_names, filled=True)
plt.show()
Dans de nombreux cas, il est tracé avec GraphViz, mais comme il doit être installé et passé par le chemin, Cette fois, nous allons dessiner avec la méthode plot_tree.
Résultat de sortie
6. Classification des prédictions
Maintenant que le modèle est complet, prédisons la classification.
#Prédire les résultats de la classification
y_pred = tree.predict(X_test)
#Sortie de la valeur prédite et de la valeur de réponse correcte
print(y_pred)
print(y_test)
Résultat de sortie
y_pred: [2 2 2 1 0 1 1 0 0 1 2 0 1 2 2 2 0 0 1 0 0 2 0 2 0 0 0 2 2 0 2 2 0 0 1 1 2
0 0 1 1 0 2 2 2]
y_test: [1 2 2 1 0 2 1 0 0 1 2 0 1 2 2 2 0 0 1 0 0 2 0 2 0 0 0 2 2 0 2 2 0 0 1 1 2
0 0 1 1 0 2 2 2]
0:Setosa 1:Versicolor 2:Verginica
7. Évaluation du modèle
Puisqu'il existe trois types de classification cette fois, nous évaluerons par le taux de réponse correct.
#Taux de réponse correct de sortie
print(tree.score(X_test, y_test))
Résultat de sortie
Accuracy: 0.9555555555555556
À partir de ce qui précède, nous avons pu évaluer la classification à Setosa, Versicolor et Verginica.
■ Enfin
Dans l'arbre de décision, nous allons créer et évaluer le modèle en fonction des étapes 1 à 7 ci-dessus.
Cette fois, pour les débutants, je n'ai résumé que l'implémentation (code). En regardant le timing dans le futur, je voudrais écrire un article sur la théorie (formule mathématique).
Merci pour la lecture.
Références: Nouveau manuel d'analyse de données utilisant Python (Matériel pédagogique principal du test d'analyse des données de certification d'ingénieur Python 3)
Recommended Posts