Apprentissage automatique ⑤ Résumé AdaBoost
Résumé d'AdaBoost
Qu'est-ce qu'AdaBoost?
Adaboost est un modèle d'apprentissage automatique qui tente de créer un discriminateur fort en combinant des discriminateurs faibles qui sont légèrement plus précis que aléatoires. Le flux de la façon de faire Tout d'abord, appliquez un discriminateur faible et augmentez le poids de ceux qui ont été mal classés. Ensuite, ceux qui ont le poids sont prioritaires et classés. Je le répète.
Il est facile de comprendre si vous vous référez à la figure ci-dessous. J'ai également publié un lien Youtube, donc si vous voulez en savoir plus, jetez un œil.
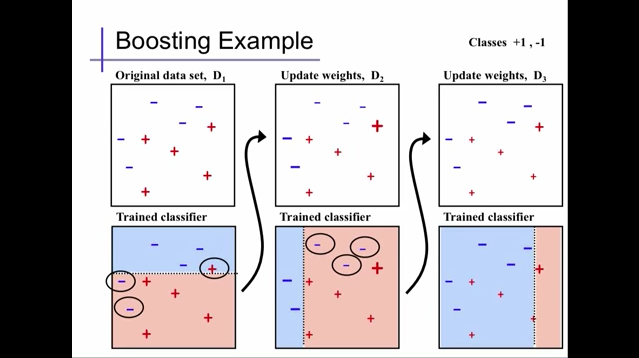 Extracted from Alexander Ihler's youtube video
Extracted from Alexander Ihler's youtube video
Dans la figure ci-dessus, nous utilisons d'abord un discriminateur faible en D1 pour classer puis augmenter les poids des '+' 1 et '-' 2 mal classés en D2. Ensuite, les trois éléments mal classés sont classés par ordre de priorité et à nouveau classés. Ici, en même temps que l'augmentation du poids, le poids des autres correctement classés diminue. De plus, dans D3, les poids des «-» 3 mal classés dans D2 sont augmentés et en même temps les poids des autres sont diminués. À propos, dans le code par défaut d'AdaBoost, DecisionTree est utilisé pour cette classification de discriminateur faible.
Sur la base du poids de la classification répétée, nous ferons un discriminateur fort.
 Extracted from Alexander Ihler's youtube video
Extracted from Alexander Ihler's youtube video
code par défaut
python
from sklearn.ensemble import AdaBoostClassifier
AdaBoostClassifier(base_estimator=None, n_estimators=50, learning_rate=1.0, algorithm='SAMME.R', random_state=None)
Description des paramètres dans AdaBoost
- base_estimator
Un modèle d'apprentissage automatique utilisé comme discriminateur faible. DecisionTreeClassifier est utilisé par défaut, mais d'autres modèles d'apprentissage automatique peuvent être appliqués en le spécifiant.
- n_estimators
Spécifiez le nombre de répétitions de la classification à l'aide d'un discriminateur faible. Cependant, avant cela, si le discriminateur fort devient précis à 100%, il s'arrête là.
Les avantages et les inconvénients d'AdaBoost.
- bon point
Il est facile de classer avec précision car il combine plusieurs classificateurs faibles.
--Mauvais point
Identique aux K voisins les plus proches, il est également vulnérable au bruit (différentes étiquettes sont mélangées au même endroit) et aux valeurs aberrantes (valeurs aberrantes). Il est facile de surapprendre.
Résumé
Ce qui précède est le contour d'AdaBoost pour autant que je puisse comprendre. Nous le mettrons à jour quotidiennement, donc si vous avez quelque chose à ajouter ou à corriger, nous vous serions reconnaissants de bien vouloir commenter.
Recommended Posts