Ensemble de données pour l'apprentissage automatique
What Cet article visualise l'ensemble de données pour la mise en œuvre du modèle Perceptron, qui est un modèle rudimentaire d'apprentissage automatique.
Content
Visualisation des ensembles de données avec Numpy Pandas Matplot
Quel est le modèle Perceptron? Ne sera pas mentionné ici. C'est un modèle célèbre, donc si vous le recherchez, vous en trouverez beaucoup. C'est le premier modèle que j'ai codé depuis que j'ai commencé à étudier l'apprentissage automatique.
L'ensemble de données est-il utilisé cette fois par une institution appelée ** UCI Machine Learning Repository **? Ou une sorte de jeu de données open source sur les fleurs Iris est utilisé comme exemple.
Tout d'abord, vérifiez l'ensemble de données. Obtenez l'ensemble de données en ligne et affichez son contenu à l'aide du module os et de la bibliothèque pandas.
import os
import pandas as pd
s = os.path.join('https://archive.ics.uci.edu', 'ml', 'machine-learning-databases', 'iris', 'iris.data')
df = pd.read_csv(s, header=None, encoding='utf-8')
print(df)
Le résultat de l'exécution du code ci-dessus est
0 1 2 3 4
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
.. ... ... ... ... ...
145 6.7 3.0 5.2 2.3 Iris-virginica
146 6.3 2.5 5.0 1.9 Iris-virginica
147 6.5 3.0 5.2 2.0 Iris-virginica
148 6.2 3.4 5.4 2.3 Iris-virginica
149 5.9 3.0 5.1 1.8 Iris-virginica
[150 rows x 5 columns]
Et comme ça, la colonne stocke les informations suivantes. Il s'agit d'un ensemble de données de 150 fleurs. En passant, dans cet ensemble de données, il existe deux types de fleurs, «Iris-setona» et «Iris-virginica».
0 colonne: Sepal length, #La longueur de l'épée
1 rangée: Separl width, #Largeur de l'épée
2 rangées: Petak length, #Longueur des pétales
3 rangées: Petal width, #Largeur des pétales
4 rangées: Class laber #Nom de la fleur
Ensuite, regardons le contenu avec un graphique à deux dimensions, centré sur la longueur de l'épée et la longueur de l'épée. En passant, je vais diviser l'intrigue pour chaque type de fleur. Dessinez le graphique à l'aide de la bibliothèque Matplot. Tout d'abord, importez la bibliothèque. Utilisez Numpy pour la manipulation des données
import matplotlib.pyplot as plt
import Numpy as np
Ensuite, récupérez la 0ème colonne: la longueur de l'épée, et la 2ème colonne: la longueur des pétales. Utilisez ʻilocpour obtenir les valeurs des 0e et 2e colonnes de la 0-100e ligne. Une liste unidimensionnelle à deux éléments de [valeurs dans la colonne 0, valeurs dans la colonne 2] est renvoyée. Ceux qui sont intéressés sont recommandés parprint (X)`.
X = df.iloc[0:100, [0, 2]].values #1 à droite,Seule la troisième rangée est retirée
Cette fois, nous regardons le contenu de l'ensemble de données à l'avance, et les 50 premiers sont les données d'Iris-setona. Tracez les données setosa avec des cercles rouges et versicolor avec un x bleu. Pour prendre la valeur du côté droit des deux éléments sur l'axe des x et la valeur du côté gauche sur l'axe des y, écrivez comme suit.
#Diagramme de dispersion de l'affichage du cercle rouge de Setosa
plt.scatter(X[:50,0], X[:50, 1], color='red', marker='o', label='setosa')
#affichage versicolor tracé bleu x
plt.scatter(X[50:100, 0], X[50:100, 1], color='blue', marker='x', label='versicolor')
#Paramètres d'étiquette d'axe
plt.xlabel('sepal length [cm]') #La longueur de l'épée
plt.ylabel('petal length [cm]') #Longueur de Hanabira
#Paramètres de la légende(Placé en haut à gauche)
plt.legend(loc='upper left')
plt.show()
Le résultat de l'exécution est ci-dessous
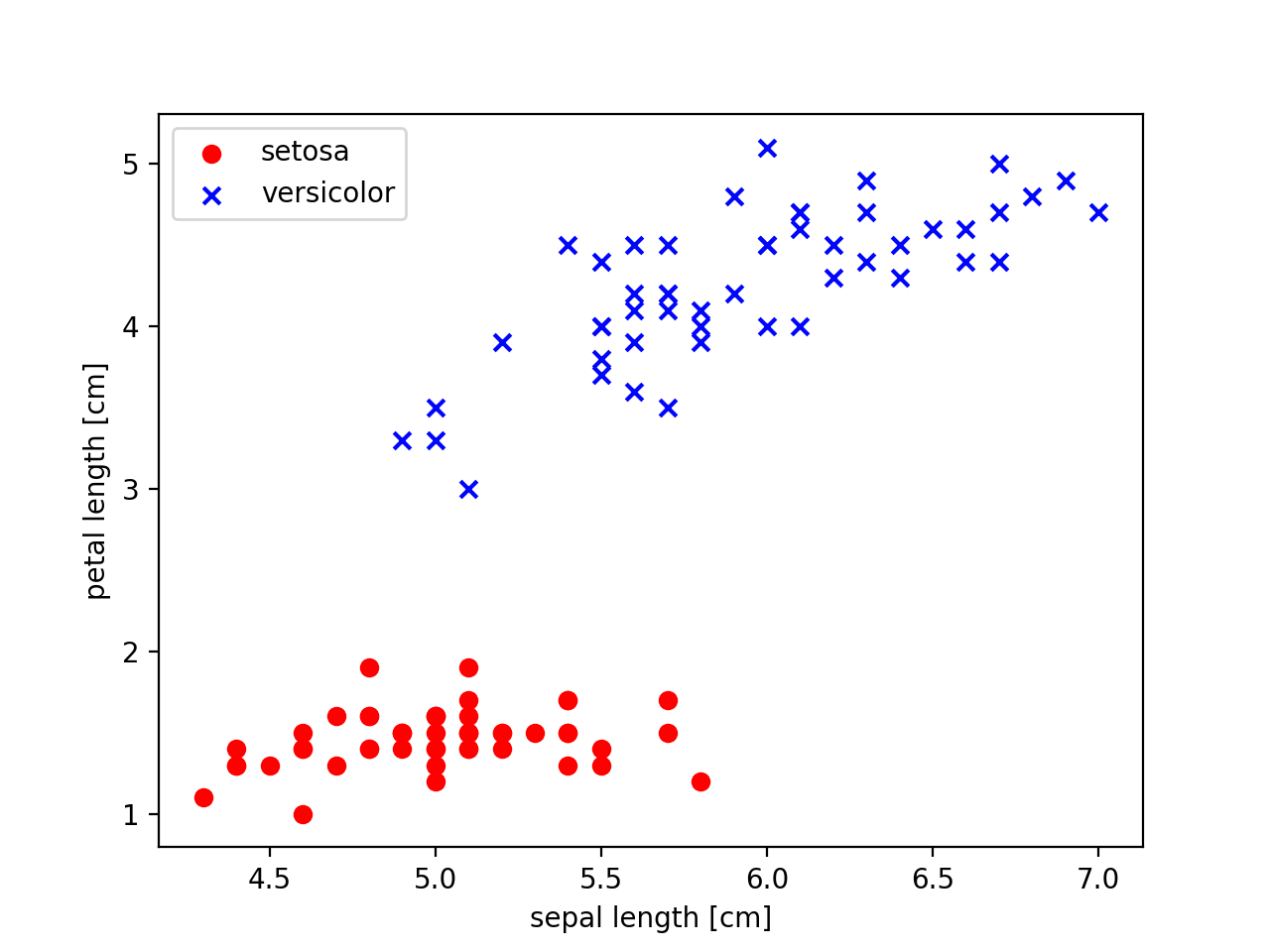 En regardant les résultats, il semble y avoir une loi. .. ..
En regardant les résultats, il semble y avoir une loi. .. ..
Nous allons l'utiliser pour construire un algorithme d'apprentissage automatique, mais le flux est à peu près le suivant (car il n'est pas possible de copier tout le livre de référence ...)
Étape .1 Définissez le taux d'apprentissage w_1 pour la longueur de la griffe et le taux d'apprentissage w_2 pour la longueur de la fleur (utilisez des nombres aléatoires). Étape .2 Prenez le produit interne avec l'ensemble de données et stockez chaque résultat de calcul de produit interne dans un tableau ou quelque chose. Étape .3 Classer en setosa ou versicolor avec une certaine valeur (par exemple, 0) comme limite du résultat du calcul du produit interne. Étape .4 Vérifiez si les données réelles correspondent au résultat de la classification, et si vous faites une erreur, mettez à jour les paramètres en fonction du taux d'apprentissage (implémenté pour tous les ensembles de données avec la boucle for, etc.) Étape .5 Gérer avec des indicateurs lorsque la classification est incorrecte Étape .6 Continuez à effectuer jusqu'à ce qu'il n'y ait pas d'erreurs de classification
Si vous suivez le processus ci-dessus, l'apprentissage automatique se terminera avec succès. Je ne publierai pas l'implémentation ici (car elle est susceptible d'être prise dans le droit d'auteur des livres de référence)
Comment En fait, lors du comptage du nombre d'erreurs de classification dans chaque cycle d'apprentissage, il y a des scènes où il ne diminue pas de façon monotone mais augmente. Il est également important de surveiller si vous apprenez dans la bonne direction ...
Recommended Posts