Une introduction à OpenCV pour l'apprentissage automatique
Pour effectuer un apprentissage automatique, il arrive souvent que vous souhaitiez découper uniquement un objet (zone) spécifique d'une image et le reconnaître ou créer des données d'apprentissage. Dans cet article, je voudrais vous présenter comment utiliser OpenCV, qui a tant de fonctions, en me concentrant sur les fonctions utilisées pour un tel apprentissage automatique. Plus précisément, nous nous concentrerons sur les modules suivants.

La procédure de coupe de base est la suivante. Dans ce qui suit, je vais expliquer selon ce processus.
- Prétraitement: prétraitement de l'image pour faciliter la détection des objets
- Détection d'objet: détecte un objet et le coupe de l'image.
- Détection de contour: détecte un objet en reconnaissant la zone (contour) sur l'image
- Reconnaissance d'objets: utilise le modèle entraîné d'OpenCV pour reconnaître et détecter l'objet cible.
- Préparation à l'apprentissage automatique: utilisez l'image coupée pour préparer la prédiction et l'apprentissage.
De plus, miniconda est utilisé pour créer l'environnement OpenCV. Installez-le et tapez la commande suivante pour terminer la construction de l'environnement.
- conda create -n cv_env numpy jupyter matplotlib
- conda install -c https://conda.anaconda.org/menpo opencv3
- activate cv_env
(* Le nom de l'environnement virtuel ne doit pas nécessairement être cv_env. De plus, s'il s'agit de Mac / Linux, l'activation sera supprimée, donc une assistance est requise. Pour plus de détails, cliquez ici] / 950b8af9100b64c0d8f9))
Le code introduit cette fois est publié dans le référentiel suivant. J'espère que vous pourrez vous y référer au besoin.
Prétraitement
Lors de la détection d'un objet, il est pratique d'avoir un "contour clair" et "continu".

Les méthodes efficaces pour cela sont le "traitement par seuil" et le "filtrage (flou)". Cette section se concentrera sur ces deux. De plus, étant donné que le traitement d'image est généralement mis à l'échelle des gris à l'avance, cela est également mentionné.
Échelle de gris
Étant donné que les informations de couleur sont rarement nécessaires dans le traitement de l'image, il est très courant de procéder à des niveaux de gris à l'avance. Cependant, veuillez noter que les informations RVB sont souvent nécessaires pour une utilisation finale dans l'apprentissage automatique.Par conséquent, lors du recadrage à partir d'une image, la couleur doit être utilisée en premier.
Les images couleur en niveaux de gris avec OpenCV est très simple. Spécifiez simplement cv2.COLOR_BGR2GRAY dans cv2.cvtColor.
import cv2
def to_grayscale(path):
img = cv2.imread(path)
grayed = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
return grayed
Comme le nom de cv2.COLOR_BGR2GRAY le suggère, les informations de couleur de l'image chargée par cv2.imread sont chargées dans l'ordre de BGR (bleu vert rouge). La variable qui lit l'image est une matrice (de numpy), mais si vous vérifiez sa taille, c'est comme suit.
img = cv2.imread(IMAGE_PATH)
img.shape
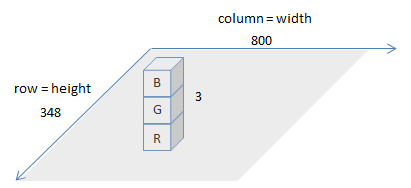
>>> (348, 800, 3)
Cela signifie que l'image chargée est représentée par une matrice 348x800x3. L'image ressemble à la figure ci-dessous.
De plus, matplotlib, qui est souvent utilisé pour afficher des images, s'attend à ce que les images arrivent en «RVB». Par conséquent, si vous mettez l'image lue par OpenCV dans matplotlib telle quelle, ce sera comme suit (l'image d'origine est à gauche, et celle lue par OpenCV est affichée par matplotlib telle quelle).

Par conséquent, lors de l'affichage avec matplotlib, il est nécessaire de changer l'ordre des couleurs comme suit.
def to_matplotlib_format(img):
return cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
Traitement des seuils
Le traitement de seuil est un traitement d'image basé sur le dépassement ou non d'un certain seuil. Par exemple, il s'agit d'un processus tel que définir tous les endroits où la luminosité n'atteint pas une certaine valeur à 0. Cela vous permet de supprimer l'arrière-plan et de souligner le contour, et de le traiter comme indiqué dans la figure ci-dessous (le côté gauche est l'image d'origine, le côté droit est celui avec le traitement de seuil).

Le traitement des seuils dans OpenCV est exécuté par cv2.threshold pouvez. Les principaux paramètres ici sont «thresh», qui est le seuil, «maxval», qui est la limite supérieure de la valeur, et «type», qui est le type de traitement de seuil.
Le tableau ci-dessous résume les types de «type» pour le traitement de seuil et comment le seuil (seuil) / limite supérieure (maxValue) est utilisé à ce moment-là.
| Threshold Type | over thresh :arrow_up_small: | under thresh :arrow_down_small: |
|---|---|---|
THRESH_BINARY |
maxValue | 0 |
THRESH_BINARY_INV |
0 | maxValue |
THRESH_TRUNC |
threshold | (as is) |
THRESH_TOZERO |
(as is) | 0 |
THRESH_TOZERO_INV |
0 | (as is) |
«(tel quel)» signifie que la valeur de l'image originale est utilisée telle quelle. Si vous souhaitez en savoir plus sur le traitement des seuils, les documents suivants vous seront utiles.
OpenCV Threshold ( Python , C++ )
Dans l'image de l'oiseau utilisée cette fois, en plus de supprimer le fond bleu, la limite (brillante) des ailes de l'oiseau est clairement définie.
- Déposez l'arrière-plan-> THRESH_BINARY
- Zone plus grande que le seuil (= clair = clair = arrière-plan): maxValue (255 = blanc = effacer)
- En dessous du seuil: 0 (noir = accentué)
- Clarification des limites-> THRESH_BINARY_INV
- Zones plus grandes que le seuil (= brillant = os d'oiseau = limite): 0 (noir = accentué)
- En dessous du seuil: maxValue (255 = blanc = effacer)
Et enfin, ces deux résultats de traitement sont fusionnés.
def binary_threshold(path):
img = cv2.imread(path)
grayed = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
under_thresh = 105
upper_thresh = 145
maxValue = 255
th, drop_back = cv2.threshold(grayed, under_thresh, maxValue, cv2.THRESH_BINARY)
th, clarify_born = cv2.threshold(grayed, upper_thresh, maxValue, cv2.THRESH_BINARY_INV)
merged = np.minimum(drop_back, clarify_born)
return merged
Si vous n'êtes pas sûr de la valeur de «seuil», vous pouvez vérifier la luminosité avec un outil de peinture. Sous Windows, vous pouvez le vérifier avec le compte-gouttes standard de l'outil de peinture.

Si vous utilisez ʻadaptiveThreshold`, il déterminera un seuil approprié tout en regardant les pixels environnants, vous pouvez donc essayer ceci une fois. Veuillez vous référer au document suivant pour plus de détails.
Traitement des seuils par couleur
Couleurs spécifiques utilisant cv2.inRange Il est également possible d'extraire la partie de. Dans ce qui suit, la partie bleue de l'arrière-plan est détectée et masquée.

def mask_blue(path):
img = cv2.imread(path)
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
blue_min = np.array([100, 170, 200], np.uint8)
blue_max = np.array([120, 180, 255], np.uint8)
blue_region = cv2.inRange(hsv, blue_min, blue_max)
white = np.full(img.shape, 255, dtype=img.dtype)
background = cv2.bitwise_and(white, white, mask=blue_region) # detected blue area becomes white
inv_mask = cv2.bitwise_not(blue_region) # make mask for not-blue area
extracted = cv2.bitwise_and(img, img, mask=inv_mask)
masked = cv2.add(extracted, background)
return masked
La "blue_region" obtenue par "cv2.inRange" est la région de couleur spécifiée. Notez que «blue_region» est représenté en échelle de gris, avec des valeurs plus élevées (255 = plus proche du blanc) là où il se trouve. De plus, lorsque vous utilisez «cv2.inRange», il est nécessaire de changer l'image en représentation HSV, et il est également nécessaire de spécifier la gamme de couleurs en conséquence. Qu'est-ce que l'expression HSV? Elle est facile à comprendre en regardant la figure ci-dessous.

Cependant, la valeur HSV spécifiée par OpenCV est un peu bizarre, il est donc assez difficile d'estimer la valeur à partir de l'outil de peinture comme décrit ci-dessus.
| Plage générale de valeurs | OpenCV | |
|---|---|---|
| H | 0 - 360 | 0 - 180 |
| S | 0 - 100 | 0 - 255 |
| V | 0 - 100 | 0 - 255 |
Par conséquent, il est plus rapide de regarder réellement les valeurs dans la matrice si la spécification ne semble pas très bien fonctionner. Vous pouvez découper la valeur de la matrice (valeur de couleur) de la zone spécifiée avec la sensation de ʻimg [10:20, 10:20] `, donc si vous la cochez, vous pouvez la spécifier précisément (en fait, cette fois la valeur de peinture est Cela n'a pas du tout aidé, alors je l'ai spécifié de cette façon).
Après cela, l'image est créée en ajoutant "background", ce qui rend la zone de "blue_region" toute blanche et "extraite", qui extrait la zone autre que "blue_region". bitwise_and / bitwise_not est une fonction utile pour faire ce genre de masquage.
Ce qui précède est l'explication du traitement de seuil.
Lissage
Si le contour de l'image n'est pas clair ou que l'arrière-plan est sombre, le contour peut ne pas être supprimé ou l'arrière-plan peut rester même si le traitement de seuil est appliqué. Dans l'exemple ci-dessous, le gravier à vos pieds reste fin et le contour est irrégulier.
 Piping plover chick with band at two weeks
Piping plover chick with band at two weeks
Dans de tels cas, il est judicieux d'utiliser un filtre pour le lissage. Pour faire simple, le processus de filtrage est un processus qui brouille l'image, mais en floutant l'image, il est possible de ne détecter que "les points qui sont clairement visibles même s'ils sont flous" et d'ignorer les points qui disparaissent s'ils sont flous. Je peux le faire. Ce qui suit est un exemple d'application du filtre gaussien à l'aide de "Flou gaussien" (figure de gauche), puis de traitement de seuil (figure de droite).
def blur(img):
filtered = cv2.GaussianBlur(img, (11, 11), 0)
return filtered

Les détails fins de l'image ont été perdus, mais vous pouvez voir que les parties caractéristiques restent ensemble et que le bruit qui était souvent en arrière-plan a disparu. Veuillez vous référer au document officiel OpenCV suivant pour les filtres autres que Gaussian Blur.
Une autre technique utilisée pour lisser les images est la morphologie. Il s'agit d'une méthode d'élimination du bruit et d'accentuation des contours à l'aide d'un traitement d'expansion / contraction d'image. Ce qui suit est une image d'une méthode typique en morphologie.

- Dialation: a pour effet d'étendre la zone de délimitation
- Érosion: a pour effet d'éroder la zone frontalière
- Ouverture: similaire à l'érosion, érode la frontière mais plus lente que l'érosion.
- Fermeture: similaire à la numérotation, élargissant les limites et rétrécissant l'arrière-plan, mais plus lente que la numérotation
Les détails théoriques sont omis ici, mais vous pouvez le considérer comme un type de filtre. Dans OpenCV, il y a cv2.dilate et cv2.erode qui peuvent effectuer le traitement de morphologie ci-dessus, et un cv2.morphologyEx pratique qui peut appliquer en continu l'ouverture / la fermeture. Cette fois, je vais essayer de lisser en utilisant cv2.morphologyEx.
def morph(img):
kernel = np.ones((3, 3),np.uint8)
opened = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel, iterations=2)
return opened

Cette fois, probablement parce que la couleur d'arrière-plan est sombre, il est devenu difficile d'épaissir la zone avec CLOSE, j'ai donc essayé de la traiter pour que la distance entre les zones soit aussi grande que possible en OPEN. Cependant, comme le bruit persiste, il est traité en combinaison avec le filtre.
def morph_and_blur(img):
kernel = np.ones((3, 3),np.uint8)
m = cv2.GaussianBlur(img, (3, 3), 0)
m = cv2.morphologyEx(m, cv2.MORPH_OPEN, kernel, iterations=2)
m = cv2.GaussianBlur(m, (5, 5), 0)
return m

C'est plus comme si l'information restait qu'un simple filtrage. En outre, vous pouvez voir que les zones précédemment connectées sont désormais fermement indépendantes en appliquant Ouverture. Ce qui suit est détaillé sur le traitement de la morphologie, veuillez donc vous y référer.
- Simple and effective coin segmentation using Python and OpenCV
- Image Segmentation with Watershed Algorithm
En fait, si l'arrière-plan est sombre et que l'échelle de gris est utilisée, il est assez difficile de clarifier la zone à partir de là. Par conséquent, si l'arrière-plan a une couleur que vous pouvez reconnaître, il est préférable de le masquer avec une couleur puis de le traiter.
Ce qui précède est l'explication du prétraitement. De là, je voudrais enfin détecter l'objet de l'image après le prétraitement.
Détection d'objets
Détection de contour
Jusque-là, je pense que l'objet à reconnaître a été clarifié par prétraitement, nous allons donc l'utiliser pour détecter le contour.

Dans OpenCV, les contours peuvent être facilement détectés en utilisant cv2.findContours.
def detect_contour(path, min_size):
contoured = cv2.imread(path)
forcrop = cv2.imread(path)
# make binary image
birds = binary_threshold_for_birds(path)
birds = cv2.bitwise_not(birds)
# detect contour
im2, contours, hierarchy = cv2.findContours(birds, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
crops = []
# draw contour
for c in contours:
if cv2.contourArea(c) < min_size:
continue
# rectangle area
x, y, w, h = cv2.boundingRect(c)
x, y, w, h = padding_position(x, y, w, h, 5)
# crop the image
cropped = forcrop[y:(y + h), x:(x + w)]
cropped = resize_image(cropped, (210, 210))
crops.append(cropped)
# draw contour
cv2.drawContours(contoured, c, -1, (0, 0, 255), 3) # contour
cv2.rectangle(contoured, (x, y), (x + w, y + h), (0, 255, 0), 3) #rectangle contour
return contoured, crops
def padding_position(x, y, w, h, p):
return x - p, y - p, w + p * 2, h + p * 2
binary_threshold_for_birds est une fonction de traitement de seuil de l'image d'oiseau utilisée cette fois (= prétraitement). Cela produira l'image d'arrière-plan blanc introduite précédemment, donc inversez-la et utilisez-la pour la détection de zone. C'est difficile à comprendre, mais dans le cas du noir et blanc, "blanc" a une valeur plus élevée (255), donc lors de la détection de contour, il est nécessaire de donner une image avec le contour dessiné en blanc en entrée.
- Veuillez noter que les contours ne seront détectés que si l'image est assez claire en noir et blanc.
Il ne vous reste plus qu'à lancer cv2.findContours. Les contours détectés par ceci peuvent être facilement dessinés sur l'image avec cv2.drawContours. Vous pouvez également utiliser cv2.boundingRect pour obtenir les coordonnées d'un rectangle qui correspond au contour. Cependant, c'est une bataille serrée, donc cette fois j'utilise padding_position pour donner un peu de place à l'environnement.
Pour cv2.findContours, veuillez également vous référer au document officiel.
De plus, lorsque l'utilisateur n'est pas automatique, il est possible de détecter l'objet dans la zone fermée en utilisant une technique appelée coupe graphique. Je n'entrerai pas dans les détails, mais je pense que c'est utile lors de la création d'outils d'annotation, donc si vous êtes intéressé, veuillez vous référer à ce qui suit.
Interactive Foreground Extraction using GrabCut Algorithm
Approximation du contour
OpenCV fournit plusieurs fonctions qui se rapprochent du contour détecté. Par exemple, ʻapproxPolyDP` se rapproche linéairement du contour détecté, et si le contour est droit, il est préférable de l'utiliser pour découper. Ci-dessous se trouve le contour détecté par la ligne pointillée rouge, et la ligne verte est une approximation linéaire.

def various_contours(path):
color = cv2.imread(path)
grayed = cv2.cvtColor(color, cv2.COLOR_BGR2GRAY)
_, binary = cv2.threshold(grayed, 218, 255, cv2.THRESH_BINARY)
inv = cv2.bitwise_not(binary)
_, contours, _ = cv2.findContours(inv, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for c in contours:
if cv2.contourArea(c) < 90:
continue
epsilon = 0.01 * cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, epsilon, True)
cv2.drawContours(color, c, -1, (0, 0, 255), 3)
cv2.drawContours(color, [approx], -1, (0, 255, 0), 3)
plt.imshow(cv2.cvtColor(color, cv2.COLOR_BGR2RGB))
various_contours(IMG_FOR_CONTOUR)
cv2.arcLength est la longueur du contour, qui est utilisée pour calculer la longueur droite minimale de ʻepsilon`. Vous pouvez maintenant ajuster la finesse des lignes droites.
Pour les autres fonctions, veuillez vous référer au tutoriel ci-dessous pour savoir comment les utiliser et les expliquer.
Découpez la zone de détection
Maintenant que nous connaissons la zone, afin de l'appliquer à un modèle d'apprentissage automatique, nous devons la découper à la taille attendue par le modèle. Pour ce faire, j'ai créé cette fois une fonction appelée resize_image.
def resize_image(img, size):
# size is enough to img
img_size = img.shape[:2]
if img_size[0] > size[1] or img_size[1] > size[0]:
raise Exception("img is larger than size")
# centering
row = (size[1] - img_size[0]) // 2
col = (size[0] - img_size[1]) // 2
resized = np.zeros(list(size) + [img.shape[2]], dtype=np.uint8)
resized[row:(row + img.shape[0]), col:(col + img.shape[1])] = img
# filling
mask = np.full(size, 255, dtype=np.uint8)
mask[row:(row + img.shape[0]), col:(col + img.shape[1])] = 0
filled = cv2.inpaint(resized, mask, 3, cv2.INPAINT_TELEA)
return filled
Cette fonction est formée par les étapes suivantes.
- redimensionner: préparer une toile (
redimensionnée) de la taille spécifiée (dimensionner l'image des données d'entraînement ou l'agrandir un peu pour la couper plus tard) - centrage: définissez l'image découpée au centre de la toile préparée
- remplissage: remplit la zone autour de l'image définie en utilisant les informations de l'image d'origine.
OpenCV a également une fonction redimensionner, mais si vous l'utilisez, l'image coupée sera ajustée de force à la taille spécifiée et l'image sera déformée. Par conséquent, cette fois, nous prenons une méthode pour préparer une toile d'une taille qui correspond à l'image découpée, en plaçant l'image découpée au centre et en remplissant l'environnement. Le cv2.inpaint utilisé pour remplir les blancs est à l'origine une fonction de restauration des défauts de l'image. Cependant, cette fois, je l'utilise pour remplir l'environnement.
L'image réellement découpée est la suivante. Je pense que c'est presque exactement complété, mais la couleur de l'abeille sur le deuxième morceau a un peu grandi. Dans ces cas, vous devez ajuster le remplissage afin qu'il ne soit rempli que de la couleur d'arrière-plan.

Alignement d'image
La position sur l'image où l'objet est déplacé est un point important dans la reconnaissance. Le CNN récemment utilisé le fera bien même s'il est légèrement désaligné en raison du pliage, mais si vous le corrigez, la précision sera grandement améliorée. Par conséquent, nous expliquerons ici la correction de position de l'image après la découpe.
La figure ci-dessous est un exemple d'alignement des images. La première ligne est l'image de base et la deuxième ligne et les suivantes sont corrigées pour s'aligner avec l'image de la première ligne (le côté gauche est avant la correction, le côté droit est après correction).
 Source de l'image: image 1, [image 2](http://www.publicdomainpictures.net/view- image.php? image = 51893 & picture = & jazyk = JP), image 3
Source de l'image: image 1, [image 2](http://www.publicdomainpictures.net/view- image.php? image = 51893 & picture = & jazyk = JP), image 3
Après avoir appliqué la correction, je pense que les positions des oiseaux sont presque les mêmes. Ceci est corrigé en utilisant findTransformECC en référence au site suivant.
Image Alignment (ECC) in OpenCV ( C++ / Python )
def align(base_img, target_img, warp_mode=cv2.MOTION_TRANSLATION, number_of_iterations=5000, termination_eps=1e-10):
base_gray = cv2.cvtColor(base_img, cv2.COLOR_BGR2GRAY)
target_gray = cv2.cvtColor(target_img, cv2.COLOR_BGR2GRAY)
# prepare transformation matrix
if warp_mode == cv2.MOTION_HOMOGRAPHY:
warp_matrix = np.eye(3, 3, dtype=np.float32)
else :
warp_matrix = np.eye(2, 3, dtype=np.float32)
criteria = (cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, number_of_iterations, termination_eps)
sz = base_img.shape
# estimate transformation
try:
(cc, warp_matrix) = cv2.findTransformECC(base_gray, target_gray, warp_matrix, warp_mode, criteria)
# execute transform
if warp_mode == cv2.MOTION_HOMOGRAPHY :
# Use warpPerspective for Homography
aligned = cv2.warpPerspective(target_img, warp_matrix, (sz[1], sz[0]), flags=cv2.INTER_LINEAR + cv2.WARP_INVERSE_MAP)
else :
# Use warpAffine for Translation, Euclidean and Affine
aligned = cv2.warpAffine(target_img, warp_matrix, (sz[1],sz[0]), flags=cv2.INTER_LINEAR + cv2.WARP_INVERSE_MAP)
return aligned
except Exception as ex:
print("can not align the image")
return target_img
En bref, findTransformECC est une fonction qui recherche des points similaires dans deux images et met le résultat de l'estimation du type de mouvement effectué dans warp_matrix. À l'origine, c'était pour analyser quel type de mouvement s'est produit sur une image continue comme un film, de sorte que les positions ne peuvent pas être alignées à moins que les images ne soient tout à fait les mêmes. Ce qui précède semble également être aligné avec désinvolture, mais il était difficile de choisir une photo qui pourrait être corrélée (l'exception est que s'il n'y a pas de corrélation, elle ne convergera pas). .. ..
S'il y a des points caractéristiques (yeux, nez, bouche, etc.) qui sont communs à toutes les images telles que le visage, la conversion peut être appliquée en fonction de la position de chaque point caractéristique. ʻEstimateRigidTransform` peut être utilisé pour cela.
def face_align(base, base_position, target, target_position):
sz = base.shape
fsize = min(len(base_position), len(target_position)) # adjust feature size
tform = cv2.estimateRigidTransform(target_position[:fsize], base_position[:fsize], False)
aligned = cv2.warpAffine(target, tform, (sz[1], sz[0]))
return aligned
Selon la photo, il y a des cas où les yeux ne peuvent pas être détectés, donc dans ce qui précède, la conversion est effectuée en fonction de la plus petite quantité de fonction de détection (cependant, veuillez noter que dans ce cas, l'ordre dans lequel les quantités de caractéristiques sont insérées doit être aligné. ).

Après la conversion, vous pouvez voir que les positions des faces sont bien alignées. Vous trouverez également une introduction détaillée sur l'alignement du visage ci-dessous, veuillez donc vous y référer.
Average Face : OpenCV ( C++ / Python ) Tutorial
Reconnaissance d'objets
Dans ce qui précède, la détection de contour a été effectuée par elle-même, mais OpenCV dispose d'un modèle entraîné pour les objets qui détectent souvent des objets tels que des visages et des corps, et la reconnaissance d'objets peut être effectuée à l'aide de cela. Ce fichier de modèle entraîné s'appelle Cascade Classifier et vous pouvez également créer le vôtre. Il y en a qui sont ouverts au public, donc si vous êtes intéressé, veuillez vous y référer comme ils sont résumés ci-dessous.
Cascade Classifier est dans (dossier d'environnement virtuel) \ Library \ etc \ haarcascades lorsqu'il est installé avec pip (pour Windows / miniconda. Je pense que cela dépend de l'environnement). Vous voudrez peut-être expérimenter pour voir s'il y a quelque chose qui semble convenir à votre objectif. Cette fois, j'aimerais suivre le tutoriel officiel ci-dessous pour détecter les visages.
Face Detection using Haar Cascades
Le résultat de la détection réelle est le suivant. La détection de l'œil droit a échoué probablement parce qu'il est caché par les cheveux. .. ..

.JPG){kind=link}
{kind=link}
Le code est presque conforme au tutoriel. Veuillez noter que l'emplacement du fichier Cascade dépend de l'environnement comme décrit ci-dessus (si le chemin d'accès échoue, vous obtiendrez une erreur telle que ʻerror: (-215)! Empty () in function`).
def face_detection(path):
face_cascade = cv2.CascadeClassifier(CASCADE_DIR + "/haarcascade_frontalface_default.xml")
eye_cascade = cv2.CascadeClassifier(CASCADE_DIR + "/haarcascade_eye.xml")
img = cv2.imread(path)
grayed = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(grayed, 1.3, 5)
for (x, y, w, h) in faces:
img = cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2)
roi_gray = grayed[y:y+h, x:x+w]
roi_color = img[y:y+h, x:x+w]
eyes = eye_cascade.detectMultiScale(roi_gray)
for (ex, ey, ew, eh) in eyes:
cv2.rectangle(roi_color, (ex,ey), (ex + ew, ey + eh), (0, 255, 0), 2)
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
face_detection(IMG_FACE)
Le flux de base est de lire le fichier avec cv2.CascadeClassifier, de créer Classifier et de détecter avec detectMultiScale. Cette fois, il est uniquement en niveaux de gris, mais je pense qu'il peut être détecté plus fermement en effectuant le traitement de seuil mentionné ci-dessus. Pour découper la pièce détectée, reportez-vous à "Découper la zone de détection" dans la section précédente.
Si le visage est incliné, il ne sera pas détecté correctement. Il y a deux façons de faire cela: l'approche consistant à détecter d'abord les yeux / la bouche pour déterminer l'inclinaison, ou simplement en tournant l'image progressivement pour essayer de la détecter. Le compromis est que le premier est moins coûteux en calcul mais encombrant, et le second est plus facile mais plus intensif en calcul. Ce qui suit décrit en détail la méthode de détection lors de la rotation de l'image, veuillez donc vous y référer.
Se préparer à l'apprentissage
Jusqu'à présent, vous avez pu découper une image de l'objet cible de l'image. Il ne vous reste plus qu'à placer les images collectées dans un modèle d'apprentissage automatique. Cependant, divers prétraitements sont nécessaires lors de la saisie d'images dans le modèle d'apprentissage. Ce point est résumé ci-dessous.
[Implémentation du réseau neuronal convolutif / données de prétraitement](http://qiita.com/icoxfog417/items/5aa1b3f87bb294f84bac#%E3%83%87%E3%83%BC%E3%82%BF%E3%81] % AE% E5% 89% 8D% E5% 87% A6% E7% 90% 86)
Pour extraire les points, le traitement suivant est nécessaire.
- Transformation matricielle: conversion au format matriciel (généralement K (profondeur = couleur) x H (hauteur) x L (largeur)) que le modèle de formation attend.
- Réglage de la profondeur: convertissez-le en canal de couleur attendu par le modèle d'entraînement (échelle de gris ou RVB)
- Normalisation des données d'image: créer une image moyenne en faisant la moyenne de toutes les images et normaliser l'image.
- Mise à l'échelle: convertit la fourchette de prix de 0 à 255 en 0 en 1.
C'est tout pour l'explication. Veuillez bien utiliser OpenCV et laissez-nous apprendre diverses choses.
Les références
- Qu'est-ce qu'OpenCV? Présentation de la dernière version 3.0 des nouvelles fonctionnalités et configuration du module
- Introduction au traitement d'image: traitement d'image à partir d'OpenCV et Python
- Learn OpenCV
Recommended Posts