[Python] Première analyse de données / apprentissage automatique (Kaggle)
introduction
Alors que j'étais sur le point de trouver un emploi (vacances de printemps dans ma 4e année d'université), j'ai soudainement voulu devenir data scientist, alors j'ai commencé à travailler sur Kaggle pour le moment.
Cette fois, j'ai travaillé sur le tutoriel «** Titanic ** de ** Kaggle **. titanic / aperçu) "problème.
J'ai de l'expérience en analyse statistique dans mes recherches, mais je ne comprends pas du tout l'apprentissage automatique, j'ai donc décidé d'étudier en me référant au code de la personne incroyablement excellente!
Au fait, voici la référence ✔︎Introduction to Ensembling/Stacking in Python C'est le code qui a été décrit comme "le plus voté" dans le bloc-notes. (Au 10 mars 2020)
Aussi, j'ai également fait référence à cet article qui faisait référence au code ci-dessus lol Tutoriel d'apprentissage d'ensemble (d'empilement) et d'apprentissage automatique dans Kaggle
Introduction Le contenu de la compétition Titanic sur laquelle nous travaillons cette fois-ci recevra des données sur les passagers telles que l'âge, le sexe, le nombre de personnes dans la chambre, la classe de la chambre, la vie et la mort.
Sur la base de ces données ** Prétraitement des données → Visualisation des données → Construction de modèles empilables → Données de test → Évaluation **
Enfin, nous prédisons la vie et la mort des passagers à l'aide d'un modèle construit à partir de données de test. La qualité de cette prédiction est également une mesure du score.
Puisqu'il y a beaucoup de volume, cet article se concentrera sur ** le "prétraitement" et la "visualisation des données" **!
Après avoir construit le modèle, je le posterai dans le prochain article! Cliquez ici pour l'article de la suite ↓ ↓ ↓ [Python] Première analyse de données / apprentissage automatique (Kaggle) ~ Part2 ~
Maintenant, commençons le prétraitement des données! !!
Prétraitement des données
Importer la bibliothèque
À peu près la bibliothèque utilisée cette fois
--Traitements mathématiques et statistiques: numpy, pundas
- Opérations d'expression régulière (recherche ou remplacement de mots ou de nombres sous une forme spécifiée): re
- J'ai différents modèles ~: sklearn
- Algorithme d'arbre de décision d'amélioration des gradients: XGboost
--Graphiques et figures: matplotlib, seaborn, plotly
--Afficher / Masquer les avertissements: avertissements
――Cinq modèles de base
- RandomForestClassifier
- AdaBoostClassifier
- GradientBoostingClassifier
- ExtraTreesClassifier
- SVC --C'est Kfold qui applique ces cinq bibliothèques de modèles en même temps.
import_library.py
import pandas as pd
import numpy as np
import re
import sklearn
import xgboost as xgb
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
import plotly.offline as py
py.init_notebook_mode(connected=True)
import plotly.graph_objs as go
import plotly.tools as tls
import warnings
warnings.filterwarnings('ignore')
#5 modèles
from sklearn.ensemble import (RandomForestClassifier, AdaBoostClassifier,
GradientBoostingClassifier, ExtraTreesClassifier)
from sklearn.svm import SVC
#Appliquer plusieurs bibliothèques de machine learning en même temps
from sklearn.cross_validation import KFold
Obtenez des données
import_data.py
train = pd.read_csv('../input/train.csv')
test = pd.read_csv('../input/test.csv')
#Faire en sorte que l'ID du passager conserve l'ID du passager
PassengerId = test['PassengerId']
train.head(3)
production

Description des données
--PassengerId: ID du passager --Survivé: drapeau de vie ou de mort (si vous survivez: 1, si vous mourez: 0) --Pclass: Classe de billet --Nom: nom du passager --Sex: Genre -Age: Âge --SibSp: Frère / conjoint à bord --Pars: Parents / enfants à bord --frais: Frais --cabin: numéro de chambre --Embarqué: port à bord
Ingénierie de la quantité de fonctionnalités
Nous traiterons les données acquises afin qu'elles puissent être facilement analysées. Ce ** prétraitement semble être assez important ** en apprentissage automatique, je ferai donc de mon mieux pendant longtemps! !!
Fondamentalement, toutes les valeurs manquantes (aucune valeur) et les données de caractères sont converties en données numériques.
FeatureEngineering.py
full_data = [train, test]
#La longueur du nom du passager
train['name_length'] = train['name'].apply(len)
test['name_length'] = test['name'].apply(len)
#1 s'il y a des données de numéro de pièce, 0 s'il manque une valeur
train['Has_Cabin'] = train['Cabin'].apply(lambda x: 0 if type(x) == float else 1)
test['Has_Cabin'] = test['Cabin'].apply(lambda x: 0 if type(x) == float else 1)
#Chevaucher la taille de la famille sur le Titanic"Frère/Nombre de conjoints"Quand"parent/Nombre d'enfants"Définir à partir de
for dataset in full_data:
dataset ['FamilySize'] = dataset['Sibsp'] + dataset['Parch'] +1
#Si tu n'as pas de famille"IsAlone"Est 1
for dataset in full_data:
dataset['IsAlone'] = 0
dataset.loc[dataset['FamilySize'] == 1, 'IsAlone'] = 1
#La plupart des valeurs manquantes au port de départ'S'Garder
for dataset in full_data:
dataset['Embarked'] = dataset['Embarked'].fillna('S')
#Définissez la valeur manquante de la charge comme valeur médiane
#Divisez les frais en 4 groupes
for dataset in full_data:
dataset['Fare'] = dataset['Fare'].fillna(train['Fare'].median())
train['CategoricalFare'] = pd.qcut(train['Fare'], 4)
#Divisez l'âge en 5 groupes
for dataset in full_data:
age_avg = dataset['Age'].mean()
age_std = dataset['Age'].std()
age_null_count = dataset['Age'].isnull().sum()
#Liste des valeurs aléatoires à mettre en valeurs manquantes
#Utilisez une valeur qui est plus grande ou plus petite par l'écart de la valeur moyenne
age_null_random_list = np.random.randint(age_avg - age_std, age_avg + age_std, size = age_null_count)
dataset['Age'][np.isnan(dataset['Age'])] = age_null_random_list
#Convertir les données en type int
dataset['Age'] = dataset['Age'].astype(int)
train['CategoricalAge'] = pd.qcut(train['Age'],5)
#Fonction obtenir pour récupérer le nom_Définition du titre
def get_title(name):
title_search = re.search('([A-Za-z]+)\.',name)
#S'il y a un nom, retirez-le et renvoyez-le
if title_search:
return title_search.group(1)
return ""
#Fonction get_utiliser le titre
for dataset in ftll_data:
dataset['Title'] = dataset['Name'].apply(get_title)
#Corrigez la partie erronée du nom
dataset['Title'] = dataset['Title'].replace(['Lady', 'Countess','Capt', 'Col','Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')
dataset['Title'] = dataset['Title'].replace('Mlle', 'Miss')
dataset['Title'] = dataset['Title'].replace('Ms', 'Miss')
dataset['Title'] = dataset['Title'].replace('Mme', 'Mrs')
for dataset in full_data:
#0 pour les femmes, 1 pour les hommes
dataset['Sex'] = dataset['Sex'].map( {'female': 0, 'male': 1} ).astype(int)
#Étiqueté pour 5 types de noms
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5}
dataset['Title'] = dataset['Title'].map(title_mapping)
dataset['Title'] = dataset['Title'].fillna(0)
#Etiqueté sur 3 types de points de départ
dataset['Embarked'] = dataset['Embarked'].map( {'S': 0, 'C': 1, 'Q': 2} ).astype(int)
#Divisez les frais en 4 groupes
dataset.loc[ dataset['Fare'] <= 7.91, 'Fare'] = 0
dataset.loc[(dataset['Fare'] > 7.91) & (dataset['Fare'] <= 14.454), 'Fare'] = 1
dataset.loc[(dataset['Fare'] > 14.454) & (dataset['Fare'] <= 31), 'Fare'] = 2
dataset.loc[ dataset['Fare'] > 31, 'Fare'] = 3
dataset['Fare'] = dataset['Fare'].astype(int)
#Divisez l'âge en 5 groupes
dataset.loc[ dataset['Age'] <= 16, 'Age'] = 0
dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 32), 'Age'] = 1
dataset.loc[(dataset['Age'] > 32) & (dataset['Age'] <= 48), 'Age'] = 2
dataset.loc[(dataset['Age'] > 48) & (dataset['Age'] <= 64), 'Age'] = 3
dataset.loc[ dataset['Age'] > 64, 'Age'] = 4 ;
#Supprimer les fonctionnalités inutiles
drop_elements = ['PassengerId', 'Name', 'Ticket', 'Cabin', 'SibSp']
train = train.drop(drop_elements, axis = 1)
train = train.drop(['CategoricalAge', 'CategoricalFare'], axis = 1)
test = test.drop(drop_elements, axis = 1)
Codage que j'ai appris
--Comment utiliser la fonction lambda
- fillna() --pandas qcut fonction --map --Entrez la valeur uniquement si True dans [] de loc [] sans utiliser l'instruction if.
- axis = 1
Visualisation de données
Enfin le prétraitement est terminé! !! Vérifions si toutes les données sont des données numériques!
visualize.py
train.head(3)

Carte thermique de corrélation des motifs
Vérifiez la corrélation entre les quantités d'entités sur la carte thermique.
heatmap.py
colormap = plt.cm.RdBu
plt.figure(figsize = (14,12))
plt.title('Peason Correlation of Features', y = 1.05, size = 15)
sns.heatmap(train.astype(float).corr(), linewidths=0.1, vmax=1.0, square = True, cmap=colormap, linecolor='white', annot=True)
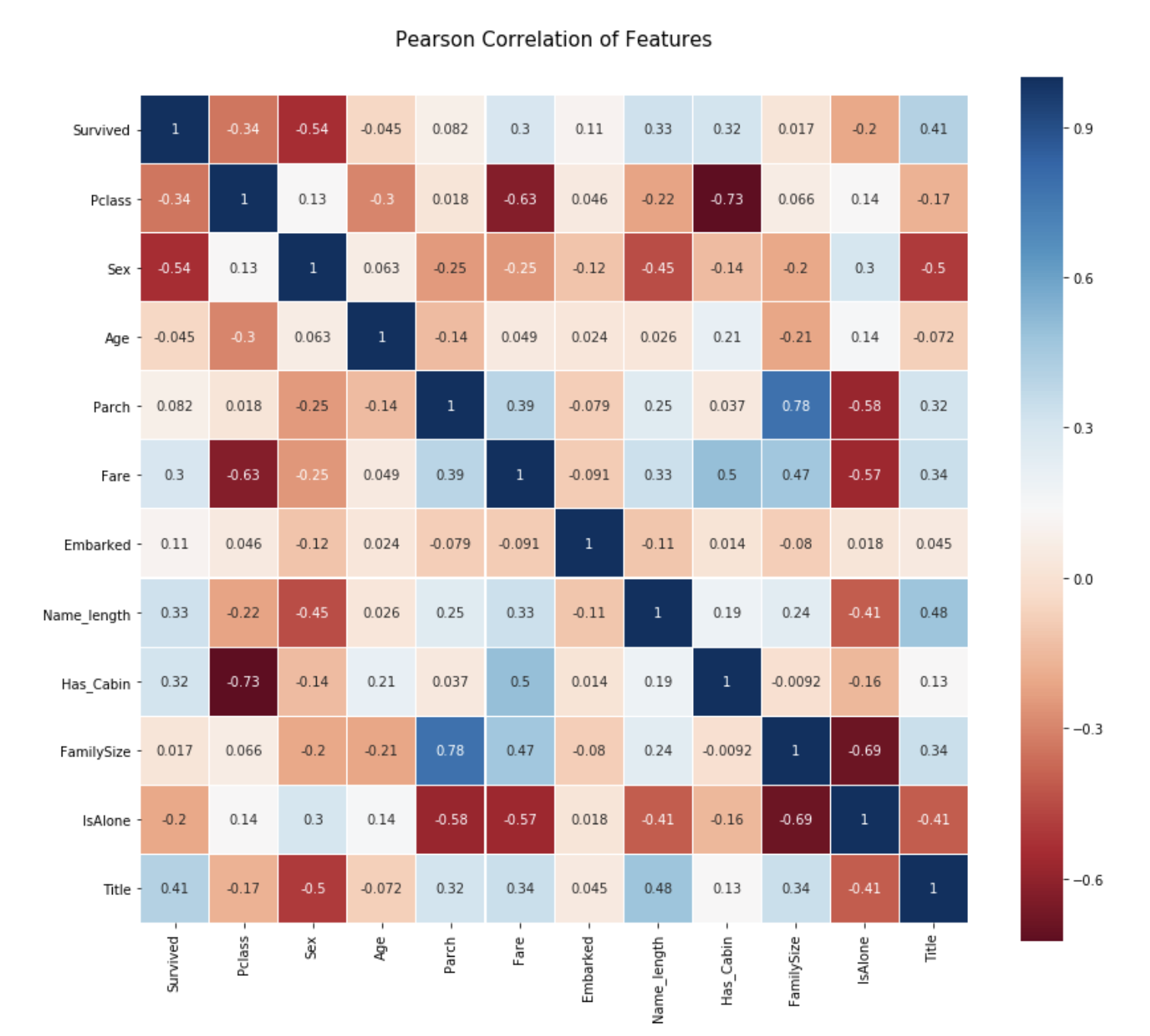
À partir de ce graphique, nous pouvons voir que les caractéristiques ne sont pas si fortement corrélées les unes aux autres.
Les fonctionnalités sont indépendantes les unes des autres → Pas de fonctionnalités inutiles → Important pour construire un modèle d'apprentissage (Parch et Family Size ont une corrélation relativement forte, mais laissez-les tels quels.)
Parcelle de paires
Répartition des données d'une fonctionnalité à une autre
PairPlot.py
g = sns.pairplot(train[[u'Survived', u'Pclass', u'Sex', u'Age', u'Parch', u'Fare', u'Embarked',
u'FamilySize', u'Title']], hue='Survived', palette = 'seismic',size=1.2,diag_kind = 'kde',diag_kws=dict(shade=True),plot_kws=dict(s=10) )
g.set(xticklabels=[])
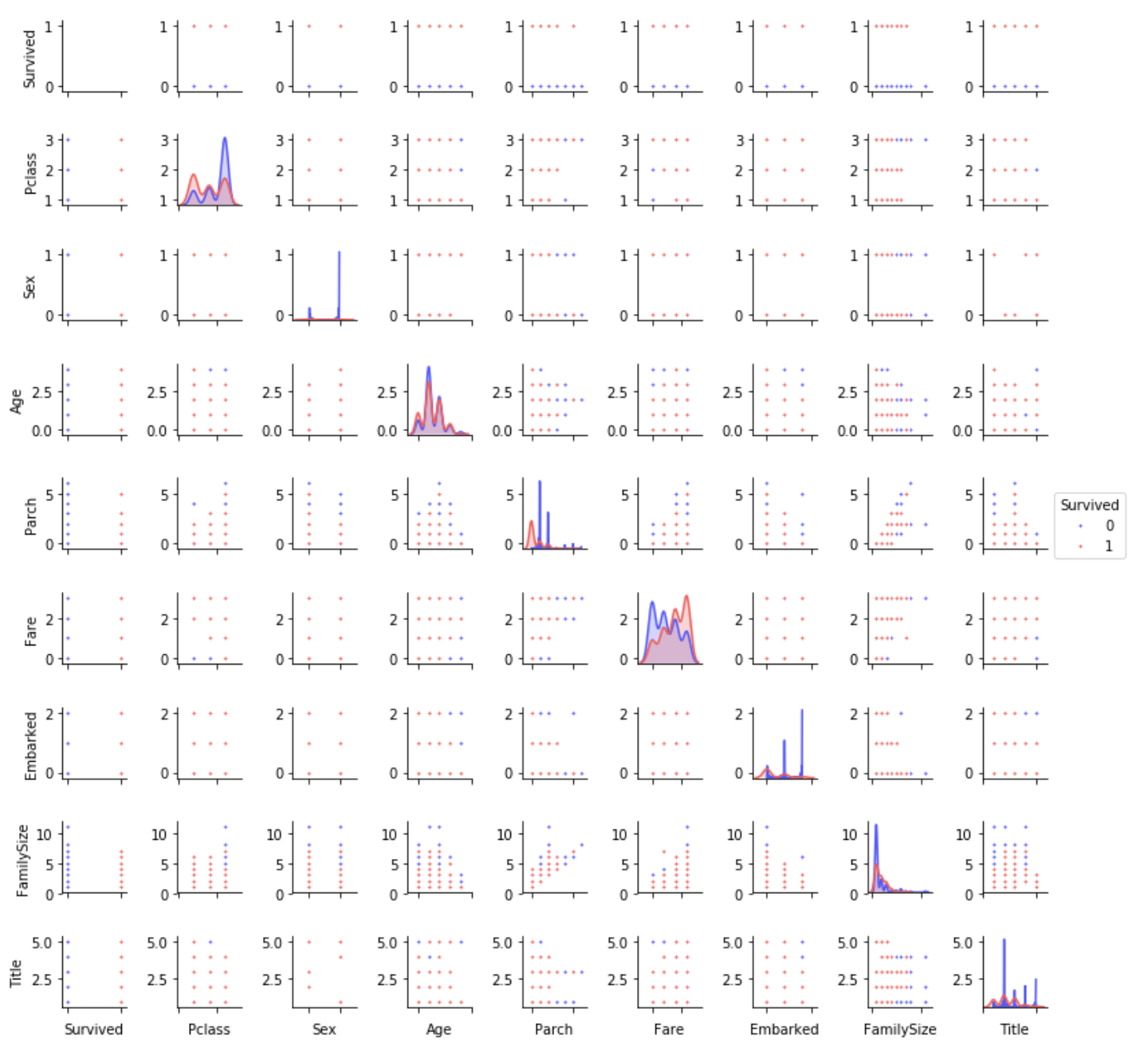
Résumé
Dans cet article, j'ai travaillé sur le tutoriel de Kaggle "Titanic". En tant que flux,
- Importer la bibliothèque
- Acquisition de données
- Prétraitement des données
- Eliminer les valeurs manquantes (insérer des valeurs proches de la valeur moyenne au hasard, etc.)
- Division égale des données --Convertir les données de catégorie en nombres
- Visualisation des données --Carte thermique de corrélation de Pearson
- Parcelle de paires
C'était assez difficile jusqu'à présent, mais je vais continuer à faire de mon mieux car c'est la construction du modèle réel à partir d'ici! !!
Recommended Posts