Mettre en œuvre l'apprentissage de l'empilement en Python [Kaggle]
TL;DR
L'apprentissage par empilement est une méthode couramment utilisée lorsque la précision d'un seul modèle de prédiction dans l'apprentissage automatique atteint un plateau. Dans cet article, nous utiliserons Python comme modèle d'empilement basé sur le précédent concours Kaggle "Otto Group Product Classification Challenge". Mettre en œuvre et contester les tâches de classification multi-classes.
Aperçu de la compétition
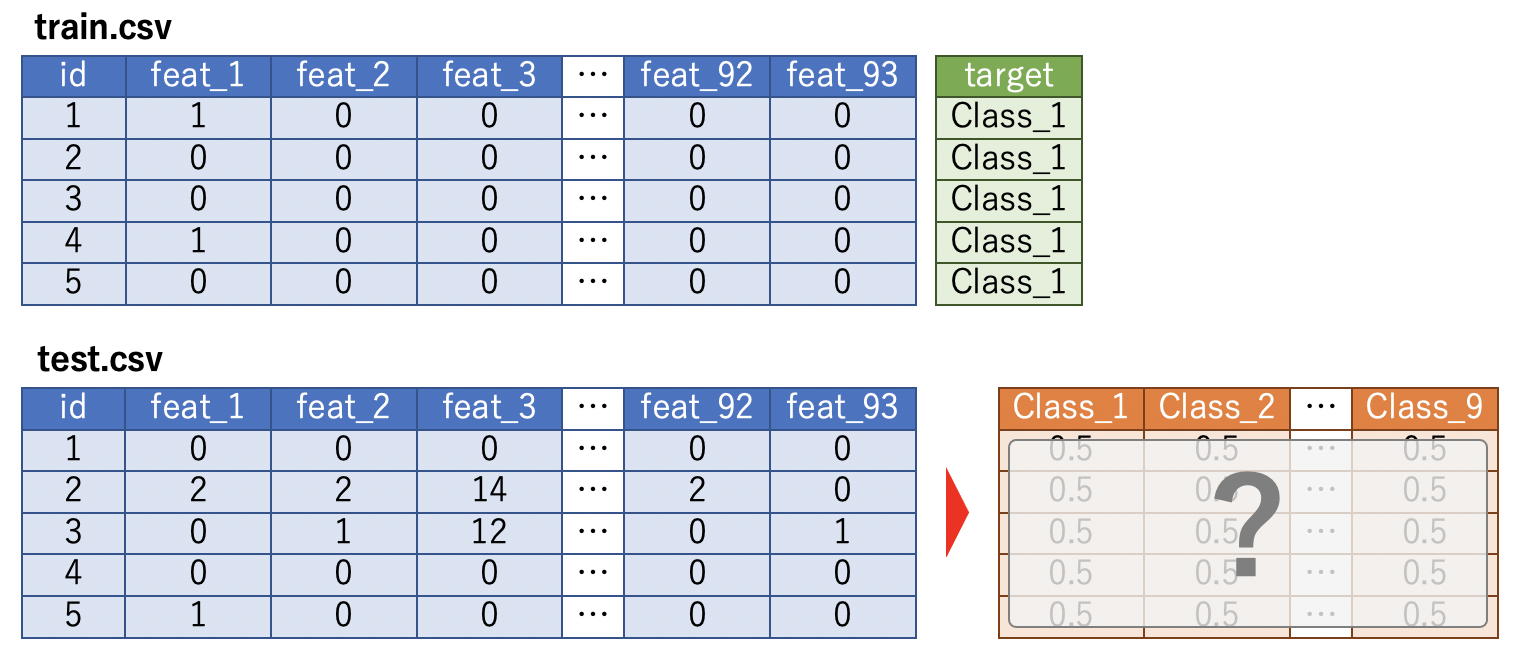
Il s'agit d'une tâche multi-classification qui prédit laquelle des neuf classes sera classée à partir des données produit.
train.csv stocke 93 quantités de caractéristiques et les données de la classe à laquelle il appartient, qui est la variable objectif. Le but est de prédire la classe à laquelle appartient chaque produit avec une probabilité à partir de la quantité de caractéristiques de test.csv. Multi-Class Log-Loss est utilisé comme indice d'évaluation.
Préparation
Importez les bibliothèques requises.
In
import os, sys
import datetime
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import StratifiedKFold
from sklearn.preprocessing import LabelEncoder
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.neighbors import KNeighborsClassifier
import xgboost as xgb
from xgboost import XGBClassifier
Lecture / prétraitement des données
In
train = pd.read_csv('data/train.csv')
test = pd.read_csv('data/test.csv')
sample = pd.read_csv('data/sampleSubmission.csv')
In
train.head()

La valeur de la variable objectif étant une chaîne de caractères, convertissez-la en valeur numérique.
In
le = LabelEncoder()
le.fit(train['target'])
train['target'] = le.transform(train['target'])
Séparez la variable explicative X et la variable objective y. Convertissez X en un tableau NumPy.
In
X_train = train.drop(['id', 'target'], axis=1)
y_train = train['target'].copy()
X_test = test.drop(['id'], axis=1)
X_train = X_train.values
X_test = X_test.values
Conservez le champ test ʻid` pour créer le fichier de soumission.
testIds = test['id'].copy()
Puisqu'il s'écarte de l'objectif, je vais l'omettre ici, mais quand on regarde la distribution des données, il y a un biais considérable dans les valeurs. Je pensais que la normalisation était une bonne méthode, mais quand je l'ai essayée, il n'y avait pas d'amélioration de la précision finale, j'ai donc décidé de continuer avec les données de ligne telles quelles.
Définition du modèle de première couche
Configuration globale du modèle
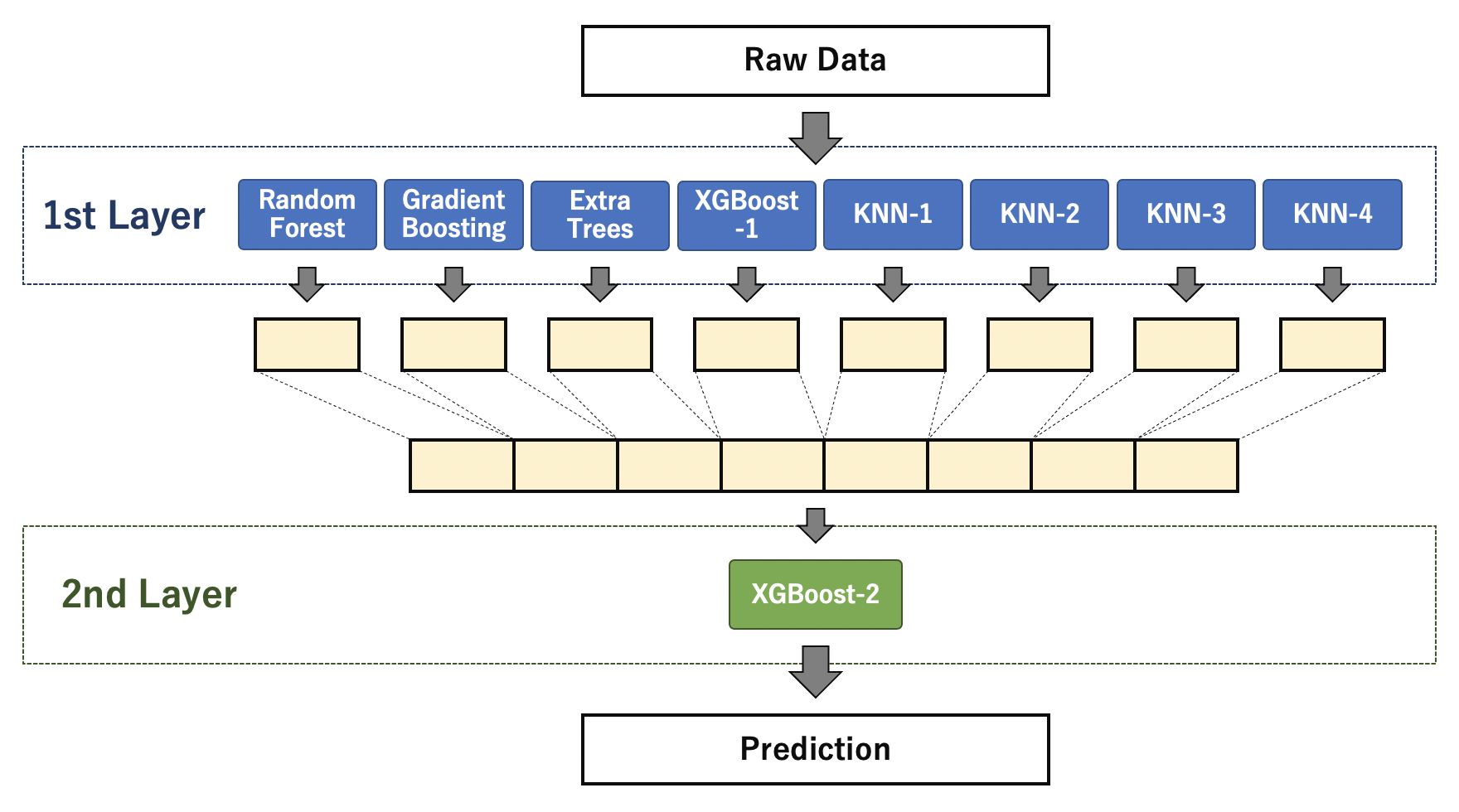
Dans l'ensemble, la première couche définit huit modèles tels que Random Forest, Gradient Boosting et KNN. En utilisant les valeurs prédites de chaque modèle dans la première couche, la prédiction par XGBoost dans la deuxième couche est utilisée comme résultat de prédiction final.
Définition de la classe d'extension du classificateur
Définissez une classe d'extension pour le classificateur afin de simplifier les opérations (définition, formation, prédiction) pour chaque modèle de premier niveau.
In
class ClfBuilder(object):
def __init__(self, clf, params=None):
self.clf = clf(**params)
def fit(self, X, y):
self.clf.fit(X, y)
def predict(self, X):
return self.clf.predict(X)
def predict_proba(self, X):
return self.clf.predict_proba(X)
Définition de la fonction de prédiction hors pli
L'empilement utilise les valeurs prévues du premier modèle de couche pour le deuxième modèle de couche. Afin d'éviter le surentraînement des données connues dans la deuxième couche, la valeur prédite par Out-of-Fold est calculée dans la première couche et utilisée pour l'entraînement dans la deuxième couche. Dans l'implémentation suivante, «Stratified KFold» est utilisé pour la vérification d'intersection en 5 parties.
In
def get_base_model_preds(clf, X_train, y_train, X_test):
print(clf.clf)
N_SPLITS = 5
oof_valid = np.zeros((X_train.shape[0], 9))
oof_test = np.zeros((X_test.shape[0], 9))
oof_test_skf = np.zeros((N_SPLITS, X_test.shape[0], 9))
skf = StratifiedKFold(n_splits=N_SPLITS)
for i, (train_index, valid_index) in enumerate(skf.split(X_train, y_train)):
print('[CV] {}/{}'.format(i+1, N_SPLITS))
X_train_, X_valid_ = X_train[train_index], X_train[valid_index]
y_train_, y_valid_ = y_train[train_index], y_train[valid_index]
clf.fit(X_train_, y_train_)
oof_valid[valid_index] = clf.predict_proba(X_valid_)
oof_test_skf[i, :] = clf.predict_proba(X_test)
oof_test[:] = oof_test_skf.mean(axis=0)
return oof_valid, oof_test
Paramétrage
Définissez les paramètres à passer à la fonction ClfBuilder avec le type dict.
(* Le réglage des hyper paramètres n'est pas effectué ici)
In
rfc_params = {
'n_estimators': 100,
'max_depth': 10,
'random_state': 0,
}
gbc_params = {
'n_estimators': 50,
'max_depth': 10,
'random_state': 0,
}
etc_params = {
'n_estimators': 100,
'max_depth': 10,
'random_state': 0,
}
xgbc1_params = {
'n_estimators': 100,
'max_depth': 10,
'random_state': 0,
}
knn1_params = {'n_neighbors': 4}
knn2_params = {'n_neighbors': 8}
knn3_params = {'n_neighbors': 16}
knn4_params = {'n_neighbors': 32}
Créez une instance du premier modèle de couche.
In
rfc = ClfBuilder(clf=RandomForestClassifier, params=rfc_params)
gbc = ClfBuilder(clf=GradientBoostingClassifier, params=gbc_params)
etc = ClfBuilder(clf=ExtraTreesClassifier, params=etc_params)
xgbc1 = ClfBuilder(clf=XGBClassifier, params=xgbc1_params)
knn1 = ClfBuilder(clf=KNeighborsClassifier, params=knn1_params)
knn2 = ClfBuilder(clf=KNeighborsClassifier, params=knn2_params)
knn3 = ClfBuilder(clf=KNeighborsClassifier, params=knn3_params)
knn4 = ClfBuilder(clf=KNeighborsClassifier, params=knn4_params)
Apprentissage du modèle de première couche
En utilisant le get_base_model_preds défini précédemment, chaque modèle de première couche est entraîné et la valeur prédite utilisée pour l'apprentissage et la prédiction du modèle de deuxième couche est calculée.
In
oof_valid_rfc, oof_test_rfc = get_base_model_preds(rfc, X_train, y_train, X_test)
oof_valid_gbc, oof_test_gbc = get_base_model_preds(gbc, X_train, y_train, X_test)
oof_valid_etc, oof_test_etc = get_base_model_preds(etc, X_train, y_train, X_test)
oof_valid_xgbc1, oof_test_xgbc1 = get_base_model_preds(xgbc1, X_train, y_train, X_test)
oof_valid_knn1, oof_test_knn1 = get_base_model_preds(knn1, X_train, y_train, X_test)
oof_valid_knn2, oof_test_knn2 = get_base_model_preds(knn2, X_train, y_train, X_test)
oof_valid_knn3, oof_test_knn3 = get_base_model_preds(knn3, X_train, y_train, X_test)
oof_valid_knn4, oof_test_knn4 = get_base_model_preds(knn4, X_train, y_train, X_test)
Out
RandomForestClassifier(max_depth=10, random_state=0)
[CV] 1/5
[CV] 2/5
[CV] 3/5
[CV] 4/5
[CV] 5/5
GradientBoostingClassifier(max_depth=10, n_estimators=50, random_state=0)
[CV] 1/5
(...Abréviation...)
[CV] 5/5
KNeighborsClassifier(n_neighbors=32)
[CV] 1/5
[CV] 2/5
[CV] 3/5
[CV] 4/5
[CV] 5/5
La valeur de prédiction à entrer dans la deuxième couche est la combinaison des résultats de prédiction de chaque classificateur côte à côte.
In
X_train_base = np.concatenate([oof_valid_rfc,
oof_valid_gbc,
oof_valid_etc,
oof_valid_xgbc1,
oof_valid_knn1,
oof_valid_knn2,
oof_valid_knn3,
oof_valid_knn4,
], axis=1)
X_test_base = np.concatenate([oof_test_rfc,
oof_test_gbc,
oof_test_etc,
oof_test_xgbc1,
oof_test_knn1,
oof_test_knn2,
oof_test_knn3,
oof_test_knn4,
], axis=1)
Définition / apprentissage du modèle de deuxième couche
XGBoost est utilisé comme modèle de deuxième couche. Définissez les paramètres et créez une instance du modèle.
In
xgbc2_params = {
'n_eetimators': 100,
'max_depth': 5,
'random_state': 42,
}
xgbc2 = XGBClassifier(**xgbc2_params)
Nous allons former le modèle de deuxième couche.
In
xgbc2.fit(X_train_base, y_train)
Prédiction par données de test
La prédiction est effectuée à l'aide de données de test à l'aide du modèle de deuxième couche formé.
In
prediction = xgbc2.predict_proba(X_test_base)
Stockez les résultats de la prédiction dans le bloc de données du fichier de soumission. Sortie au format csv et soumission.
In
columns = ['Class_1', 'Class_2', 'Class_3', 'Class_4', 'Class_5', 'Class_6', 'Class_7', 'Class_8', 'Class_9']
df_prediction = pd.DataFrame(prediction, columns=columns)
df_submission = pd.concat([testIds, df_prediction], axis=1)
In
now = datetime.datetime.now()
timestamp = now.strftime('%Y%m%d-%H%M%S')
df_submission.to_csv('output/ensemble_{}.csv'.format(timestamp), index=False)
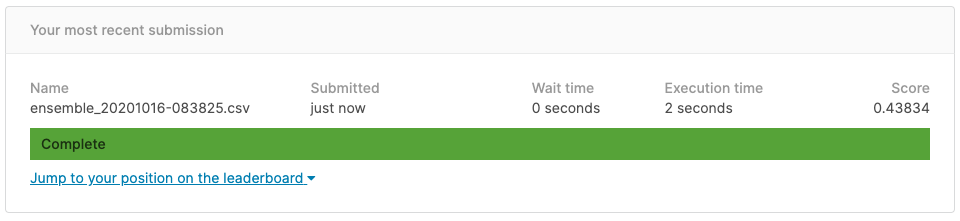
Le résultat est «Score = 0,443834». Comme il s'agit d'une soumission tardive, il ne sera pas répertorié dans le classement, mais s'il est répertorié, il a été classé 462/3507, ce qui était le top 14%.
Comparaison de précision avec chaque modèle de la première couche
Pour voir l'effet de l'empilement, comparons-le avec le score prévu pour les données de test calculées par chaque modèle de la première couche.
| Classifier | Score |
|---|---|
| Random Forest | 0.95957 |
| Gradient Boosting | 0.49276 |
| Extra Trees | 1.34781 |
| XGBoost-1 | 0.47799 |
| KNN-1 | 1.94937 |
| KNN-2 | 1.28614 |
| KNN-3 | 0.93161 |
| KNN-4 | 0.75685 |
Nous avons confirmé que la prédiction d'empilement est meilleure que n'importe quel classificateur unique! Cette fois, nous n'avons pas traité les données d'entrée ni réglé les hyper-paramètres, mais cela pourrait améliorer encore la précision. De plus, comme le modèle gagnant, il semble possible de configurer la deuxième couche avec plusieurs classificateurs.
Références / URL
- "Technologie d'analyse des données qui gagne avec Kaggle"
- Tutoriel d'apprentissage d'ensemble (empilement) et d'apprentissage automatique dans Kaggle
- KAGGLE ENSEMBLING GUIDE
Recommended Posts