Analyse de données à partir de python (pré-traitement des données-apprentissage automatique)
introduction
Pour les débutants, j'aimerais expliquer le prétraitement des données avec python à la construction de modèles d'apprentissage automatique. Utilisez le renforcement de gradient pour l'apprentissage automatique.
Code source https://gitlab.com/ceml/qiita/-/blob/master/src/python/notebook/first_time_ml.ipynb
Contenu de cet article
table des matières
- Prétraitement des données 1-1. Lire les données 1-2. Combiner des données 1-3. Complément foncier défectueux 1-4. Création de fonctionnalités 1-5. Répartition des données
- Apprentissage automatique 2-1. Création de jeux de données et définition de modèles 2-2. Formation et évaluation de modèles 2-3. Confirmer l'importance de la quantité de caractéristiques
À propos de l'ensemble de données
・ Fourni par: California Institute of Technology ・ Contenu: Données de test des patients atteints de maladies cardiaques ・ URL: https://archive.ics.uci.edu/ml/datasets/Heart+Disease ・ Traitées.cleveland.data, retraitées.hungarian.data, retraitées.hungarian.data, traitées.suisse à l'URL ci-dessus
- Voir ci-dessous pour le téléchargement des données Analyse de données à partir de python (visualisation de données 1) https://qiita.com/CEML/items/d673713e25242e6b4cdb
Objectif de l'analyse
L'ensemble de données classe l'état du patient en cinq classes. Laissez l'apprentissage automatique prédire ces cinq classes. Les modèles d'apprentissage automatique utilisent la stimulation de gradient.
1. Prétraitement des données
1.1 Chargement des données
import pandas as pd
columns_name = ["age", "sex", "cp", "trestbps", "chol", "fbs", "restecg", "thalach", "exang", "oldpeak","slope","ca","thal","class"]
cleveland = pd.read_csv("/Users/processed.cleveland.data",header=None, names=columns_name)
hungarian = pd.read_csv("/Users/reprocessed.hungarian.data",sep=' ',header=None, names=columns_name)
va = pd.read_csv("/Users/processed.va.data",header=None, names=columns_name)
switzerland = pd.read_csv("/Users/processed.switzerland.data",sep=",",header=None, names=columns_name)
Le sep donné à l'argument en hubgarien et en suisse est un délimiteur de caractère. Puisque toutes les données de ces deux données sont contenues dans une colonne, elles sont séparées pour chaque colonne par sep.
- Pour plus de détails sur les colonnes, reportez-vous à l'article de référence de téléchargement de données.
1-2. Combiner les données
Toutes les données peuvent être combinées et traitées en même temps.
merge_data = pd.concat([cleveland,hungarian,va,switzerland],axis=0)
print(merge_data.shape)
# output
'''(921, 14)'''
1-3. Compléter les terres déficientes
Dans ces données, '? Depuis 'est entré, convertissez-le en null puis convertissez les données en type numérique. Cette fois, nous utiliserons le renforcement du gradient, nous utiliserons donc la valeur nulle telle quelle sans la convertir, mais pour les autres modèles, vous devrez remplacer null par un certain nombre.
merge_data.replace({"?":np.nan},inplace=True)
merge_data = merge_data.astype("float")
#Supprimer la classe manquante dans la ligne
merge_data.dropna(subset=["class"], inplace=True)
#Confirmation de valeur manquante
print(merge_data.isnull().sum())
# output
'''
age 0
sex 0
cp 0
trestbps 58
chol 7
fbs 82
restecg 1
thalach 54
exang 54
oldpeak 62
slope 119
ca 320
thal 220
class 0
dtype: int64
'''
1-4. Création de fonctionnalités
Il s'agit de l'étape de création d'une nouvelle quantité d'objets à partir de la quantité d'objets. Normalement, je sauterais d'abord cette étape et créerais un modèle en utilisant uniquement les données collectées. Sur la base de la précision, nous créerons une nouvelle quantité de caractéristiques pour améliorer la précision. Cette fois je vais le créer depuis le début car c'est un tutoriel. Par exemple, créez une différence par rapport à l'âge moyen en tant que quantité d'entités.
merge_data['diff_age'] = merge_data['age'] - merge_data['age'].mean()
1-5. Division des données
Divisez les données en trois parties: formation, test et validation. Une chose à garder à l'esprit en ce moment est que la classe de pathologie est déséquilibrée. Regardons cela concrètement.
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
merge_data["class"].hist()
plt.xlabel("class")
plt.ylabel("number of sample")
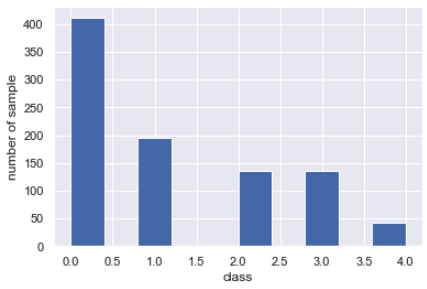
Il existe de nombreuses classes 0 de personnes en bonne santé, et le nombre de patients gravement malades diminue. Il existe de nombreux problèmes de déséquilibre dans les problèmes réels.
Vous devez fractionner les données sans modifier ce pourcentage.
from sklearn.model_selection import StratifiedShuffleSplit
#Séparer la variable objectif
X = merge_data.drop("class",axis=1).values
y = merge_data["class"].values
columns_name = merge_data.drop("class",axis=1).columns
#Définir une fonction à classer
sss = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=0)
def data_split(X,y):
for train_index, test_index in sss.split(X, y):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
X_train = pd.DataFrame(X_train, columns=columns_name)
X_test = pd.DataFrame(X_test, columns=columns_name)
return X_train, y_train, X_test, y_test
# train, test,Séparé en val
X_train, y_train, X_test, y_test = data_split(X, y)
X_train, y_train, X_val, y_val = data_split(X_train.values, y_train)
#confirmation de forme
print("train shape", X_train.shape)
print("test shape", X_test.shape)
print("validation shape", X_val.shape)
#Vérifier le pourcentage de classe
plt.figure(figsize=(20,5))
plt.subplot(1,3,1)
plt.hist(y_train)
plt.subplot(1,3,2)
plt.hist(y_test)
plt.subplot(1,3,3)
plt.hist(y_val)
# output
'''
train shape (588, 14)
test shape (184, 14)
validation shape (148, 14)
'''
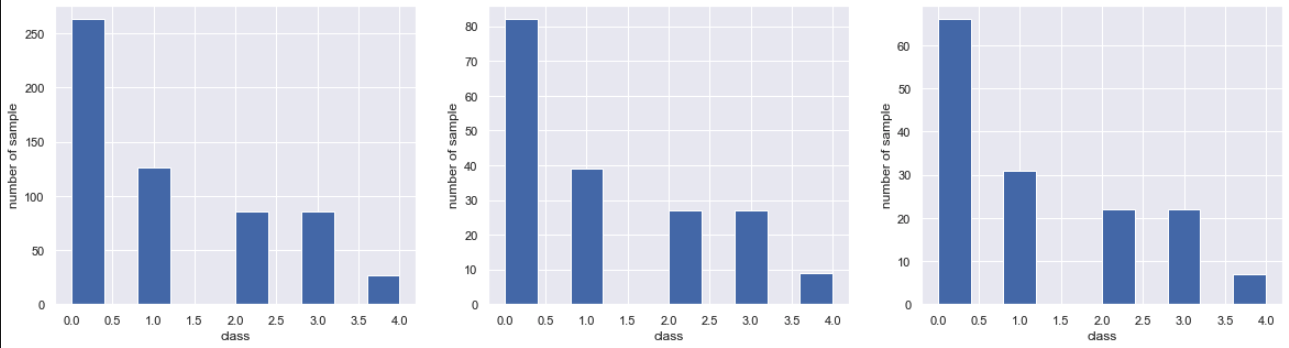 Il peut être divisé sans changer le rapport.
Il peut être divisé sans changer le rapport.
2. Apprentissage automatique
2.1 Création du jeu de données et définition du modèle
Créez un jeu de données et donnez-lui des paramètres.
import lightgbm as lgb
#Créer un jeu de données
train = lgb.Dataset(X_train, label=y_train)
valid = lgb.Dataset(X_val, label=y_val)
#Définir les paramètres du modèle
params = {
'reg_lambda' : 0.2,
'objective': 'multiclass',
'metric': 'multi_logloss',
'num_class': 5,
'reg_alpha': 0.1,
'min_data_leaf': 100,
'learning_rate': 0.025,
# 'feature_fraction': 0.8,
# 'bagging_fraction': 0.8
}
2.2 Formation et évaluation du modèle
Lors de la formation d'un modèle, spécifiez un arrêt précoce et arrêtez l'apprentissage lorsque la perte ne diminue pas. La prédiction est très probablement avec argmax. L'évaluation est basée sur la matrice de mélange et le coefficient kappa. Seule la vérification d'exclusion est effectuée sans validation croisée.
#Former le modèle
model = lgb.train(params,
train,
valid_sets=valid,
num_boost_round=5000,
early_stopping_rounds=500)
#Prévoir
y_pred = model.predict(X_test, num_iteration=model.best_iteration)
y_pred = np.argmax(y_pred, axis=1)
#--------------------------Évaluation du modèle-----------------------------------------------
from sklearn.metrics import confusion_matrix
from sklearn.metrics import cohen_kappa_score
#Créer une matrice mixte
result_matrix = pd.DataFrame(confusion_matrix(y_test,y_pred))
#Calculez le taux de réponse correct pour chaque classe
class_accuracy = [(result_matrix[i][i]/result_matrix[i].sum())*1 for i in range(len(result_matrix))]
result_matrix[5] = class_accuracy
#Calculer le coefficient kappa
kappa = cohen_kappa_score(y_test,y_pred)
print("kappa score:",kappa)
# plot
plt.figure(figsize=(7,5))
sns.heatmap(result_matrix,annot=True,cmap="Blues",cbar=False)
plt.xticks([5.5,4.5,3.5,2.5,1.5,0.5], ["accuracy",4, 3, 2, 1,0])
plt.ylabel('Truth',fontsize=13)
plt.xlabel('Prediction',fontsize=13)
plt.tick_params(labelsize = 13)
# output
'''
kappa score: 0.3368649587494572
'''
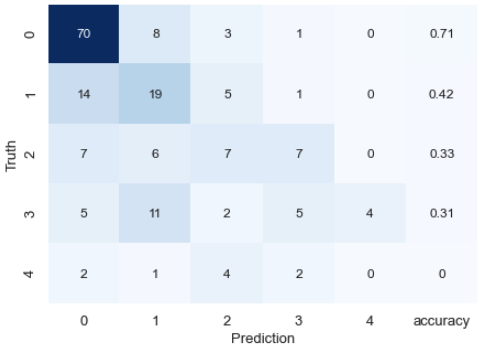
Les résultats ne sont pas très bons, mais à part ça, nous confirmons l'importance des fonctionnalités.
2-3. Confirmer l'importance de la quantité d'éléments
lgb.plot_importance(model, figsize=(8, 6))
plt.show()
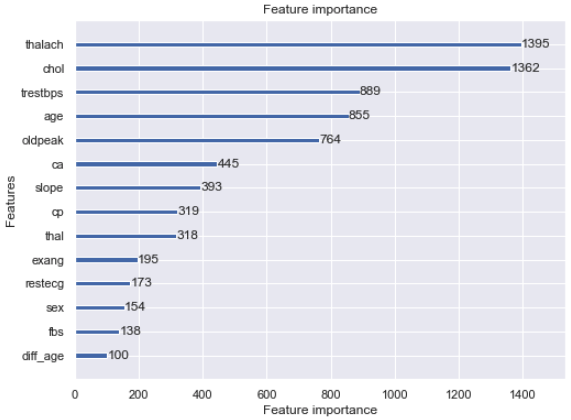
Le résultat était que la quantité d'entités créées était la plus faible.
en conclusion
Cette fois, nous sommes passés du prétraitement des données à l'évaluation du modèle par holdout. L'ingénierie des fonctionnalités et la recherche de paramètres élevés sont nécessaires pour améliorer la précision. De plus, une évaluation de validation croisée est nécessaire pour garantir l'exactitude.
Recommended Posts