Analyse de données à partir de python (visualisation de données 1)
introduction
Ceci est le premier poste de CEML (Clinical Engineer Machine Learning). Cette fois, je voudrais expliquer l'analyse des données avec python pour les débutants. Code source https://gitlab.com/ceml/qiita/-/blob/master/src/python/notebook/first_time_data_analysis.ipynb
Contenu de cet article
Nous expliquerons de la lecture des données à la simple analyse des données à l'aide d'un ensemble de données ouvert au public gratuitement.
À propos de l'ensemble de données
・ Fourni par: California Institute of Technology ・ Contenu: Données de test des patients atteints de maladies cardiaques ・ URL: https://archive.ics.uci.edu/ml/datasets/Heart+Disease -Utilisez uniquement les données traitées.cleveland.data dans l'URL ci-dessus.
Objectif de l'analyse
L'ensemble de données classe l'état du patient en cinq classes. Je vais procéder à l'analyse dans le but de saisir les caractéristiques de chaque classe.
Télécharger les données
Accédez à l'URL ci-dessus et téléchargez traitées.cleveland.data dans le dossier de données.
Lire les données
Importez des pandas et lisez les données avec la méthode read_csv de pandas. Le nom de la colonne est spécifié lors de la lecture des données. Répertoriez les noms de colonnes et transmettez-les comme arguments aux nemes dans la méthode read_csv.
import pandas as pd
columns_name = ["age", "sex", "cp", "trestbps", "chol", "fbs", "restecg", "thalach", "exang", "oldpeak","slope","ca","thal","class"]
data = pd.read_csv("/Users/processed.cleveland.data", names=columns_name)
#Afficher les 5 premières lignes de données
data.head()
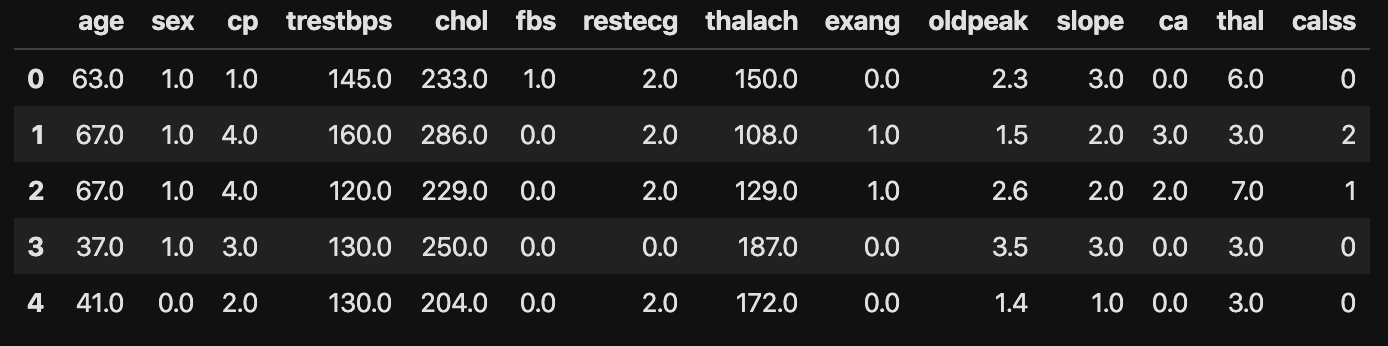
Voici les données lues.
 Voici une brève description de la colonne. Veuillez consulter la source de données pour plus de détails.
· Élever
・ Sexe (1 = homme; 0 = femme)
・ Cp: type de douleur thoracique
1:typical angina 2: atypical angina 3: non-anginal pain
4: asymptomatic
・ Trestbps: tension artérielle au repos (en mm Hg à l'admission à l'hôpital)
・ Chol: cholestérol sérique en mg / dl
・ Fbs: glycémie à jeun> 120 mg / dl) (1 = vrai; 0 = faux)
・ Restecg: résultats électrocardiographiques au repos
0: normal
1: having ST-T wave abnormality
(T wave inversions and/or ST elevation or depression of > 0.05 mV)
2: showing probable or definite left ventricular hypertrophy by Estes'criteria
・ Thalach: fréquence cardiaque maximale atteinte
・ Exang: angor induit par l'exercice (1 = oui; 0 = non)
・ Oldpeak: dépression ST induite par l'exercice par rapport au repos
・ Pente: la pente du segment ST de pointe d'exercice
1: upsloping
2: flat
3: downsloping
・ Ca: nombre de vaisseaux majeurs (0-3) colorés par fluorescence
・ Thal: 3 = normal; 6 = défaut corrigé; 7 = défaut réversible
・ Classe: 0 ~ 5 (0 est normal, plus le nombre est grand, pire c'est)
Voici une brève description de la colonne. Veuillez consulter la source de données pour plus de détails.
· Élever
・ Sexe (1 = homme; 0 = femme)
・ Cp: type de douleur thoracique
1:typical angina 2: atypical angina 3: non-anginal pain
4: asymptomatic
・ Trestbps: tension artérielle au repos (en mm Hg à l'admission à l'hôpital)
・ Chol: cholestérol sérique en mg / dl
・ Fbs: glycémie à jeun> 120 mg / dl) (1 = vrai; 0 = faux)
・ Restecg: résultats électrocardiographiques au repos
0: normal
1: having ST-T wave abnormality
(T wave inversions and/or ST elevation or depression of > 0.05 mV)
2: showing probable or definite left ventricular hypertrophy by Estes'criteria
・ Thalach: fréquence cardiaque maximale atteinte
・ Exang: angor induit par l'exercice (1 = oui; 0 = non)
・ Oldpeak: dépression ST induite par l'exercice par rapport au repos
・ Pente: la pente du segment ST de pointe d'exercice
1: upsloping
2: flat
3: downsloping
・ Ca: nombre de vaisseaux majeurs (0-3) colorés par fluorescence
・ Thal: 3 = normal; 6 = défaut corrigé; 7 = défaut réversible
・ Classe: 0 ~ 5 (0 est normal, plus le nombre est grand, pire c'est)
Prétraitement des données
Cette fois, en tant que prétraitement, vérifiez le type de données de chaque colonne et, s'il ne s'agit pas d'un type numérique, convertissez-le en type numérique. Il y a une valeur manquante entrée comme ?, Alors remplacez-la par null.
#Vérifiez le type de données
data.dtypes
#Convertir le type en float,? Remplacé par une valeur nulle
data = data.replace("?",np.nan).astype("float")
Vérifiez les statistiques de base et les valeurs manquantes des données
Confirmation pour chaque montant de fonction (variable)
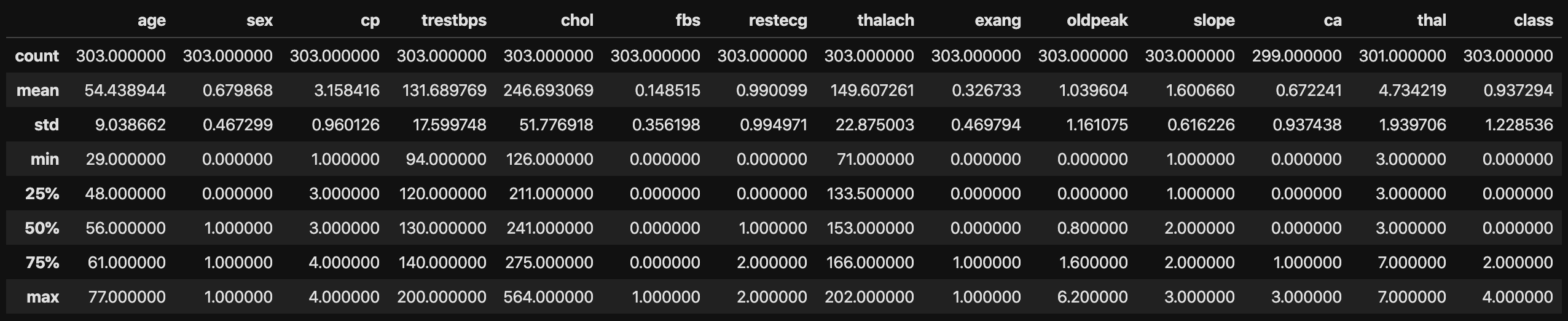
#Calculer les statistiques
data.describe()
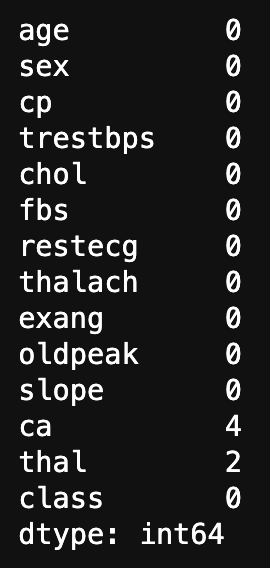
#Compter les valeurs manquantes
data.isnull().sum()
Avec juste cela, vous pouvez voir les valeurs manquantes dans les statistiques de chaque colonne.
La figure ci-dessous montre les résultats du calcul des statistiques.
Confirmation de chaque montant de fonction (variable) pour chaque classe
Voici le problème principal. En guise de confirmation, le but de cette analyse est de comprendre les caractéristiques de chaque classe. Dans ce cas, utilisez la méthode pandas group_by.
#Colonne Regrouper par classe
class_group = data.groupby("class")
#Lorsque vous spécifiez une classe et obtenez des statistiques
# class_group.get_group(0).describe()
#Spécifiez les options pour que toutes les colonnes puissent être affichées (notebook)
pd.options.display.max_columns = None
#Affichage des statistiques pour toutes les classes
class_group.describe()
Ce qui suit montre les statistiques pour toutes les classes.

C'est facile. Étant donné que la quantité de caractéristiques (variable) et le nombre de classes classées (5) sont faibles dans ces données, cela peut être confirmé en affichant les statistiques de toutes les classes, mais s'il y en a beaucoup, affichez toutes et confirmez. Les choses deviennent plus difficiles.
Visualisez les données
Vérifiez la distribution de chaque fonctionnalité (variable)
Vérifiez la distribution des données dans l'histogramme.
data.hist(figsize=(20,10))
#Empêcher les graphiques de se chevaucher
plt.tight_layout()
plt.show()
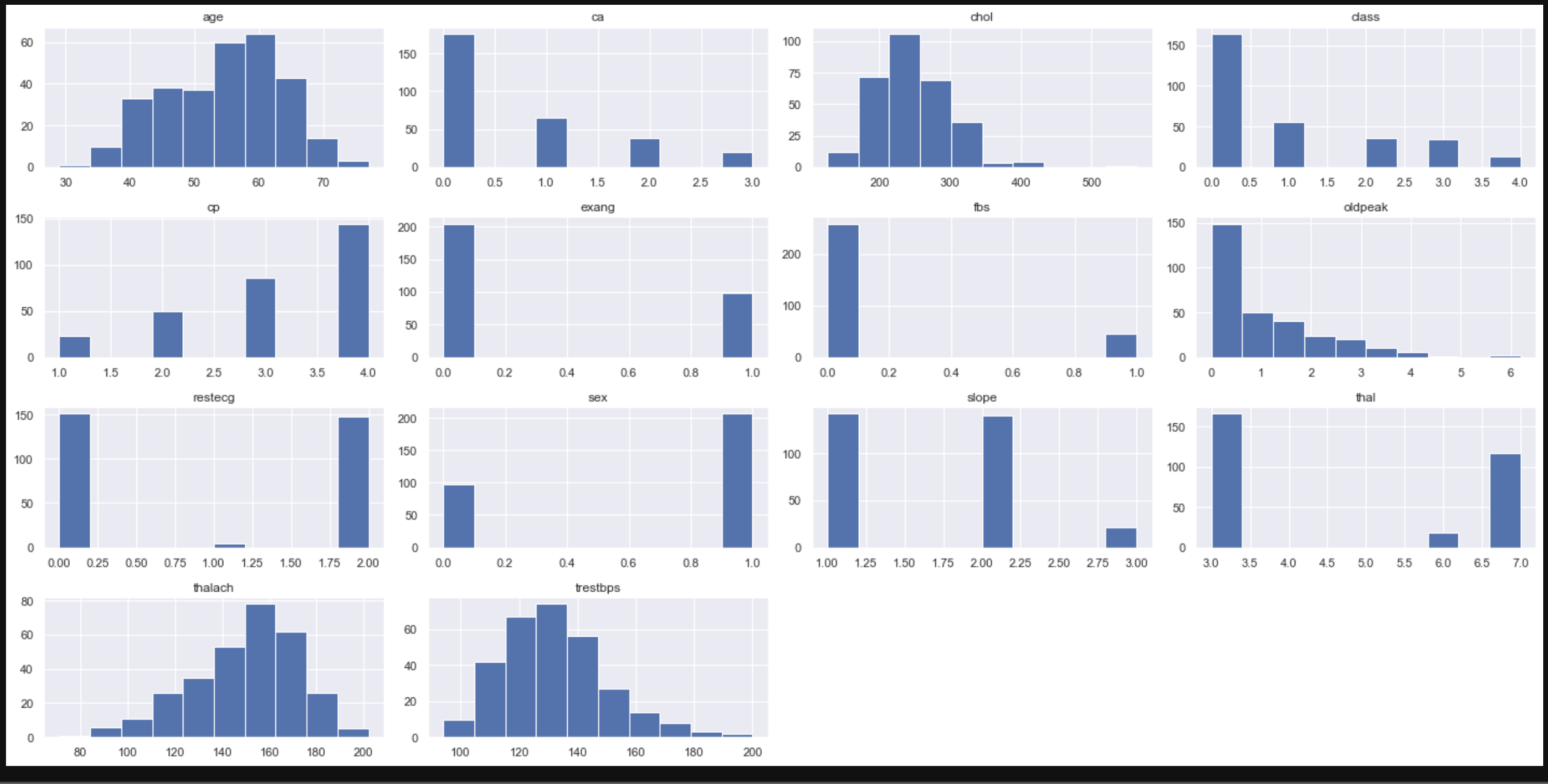
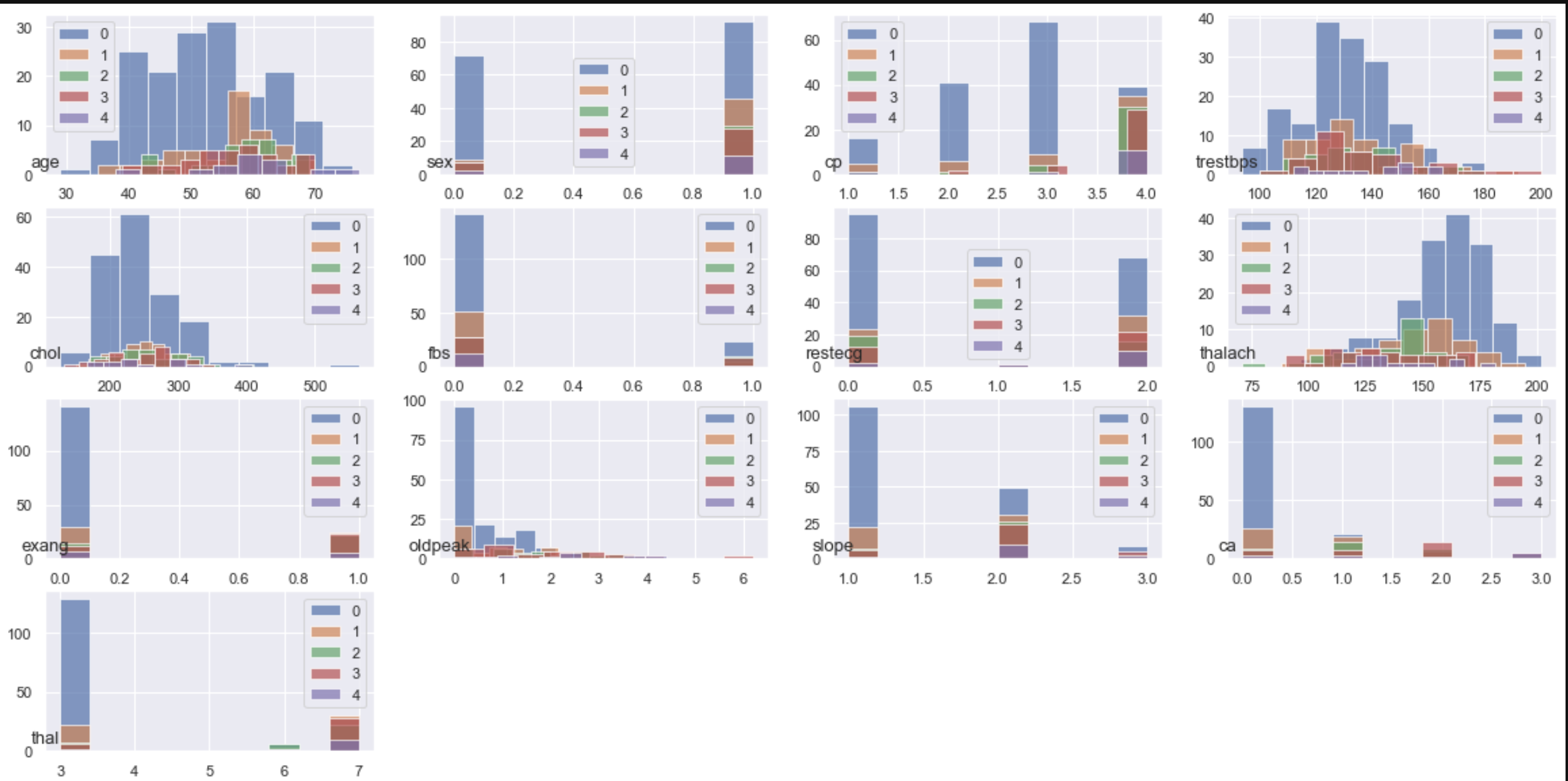
Afficher un histogramme de chaque caractéristique (variable) pour chaque classe
#Tracer par lui-même
# class_group["age"].hist(alpha=0.7)
# plt.legend([0,1,2,3,4])
#Afficher tout
plt.figure(figsize=(20,10))
for n, name in enumerate(data.columns.drop("class")):
plt.subplot(4,4,n+1)
class_group[name].hist(alpha=0.7)
plt.title(name,fontsize=13,x=0, y=0)
plt.legend([0,1,2,3,4])
Afficher la valeur moyenne et la variance de chaque montant de caractéristique (variable) pour chaque classe sur un graphique à barres
#Tracer par lui-même
# class_group.mean()["age"].plot.bar(yerr=class_group.std()["age"])
#Afficher tout
plt.figure(figsize=(20,10))
for n, name in enumerate(data.columns.drop("class")):
plt.subplot(4,4,n+1)
class_group.mean()[name].plot.bar(yerr=class_group.std()[name], fontsize=8)
plt.title(name,fontsize=13,x=0, y=0)
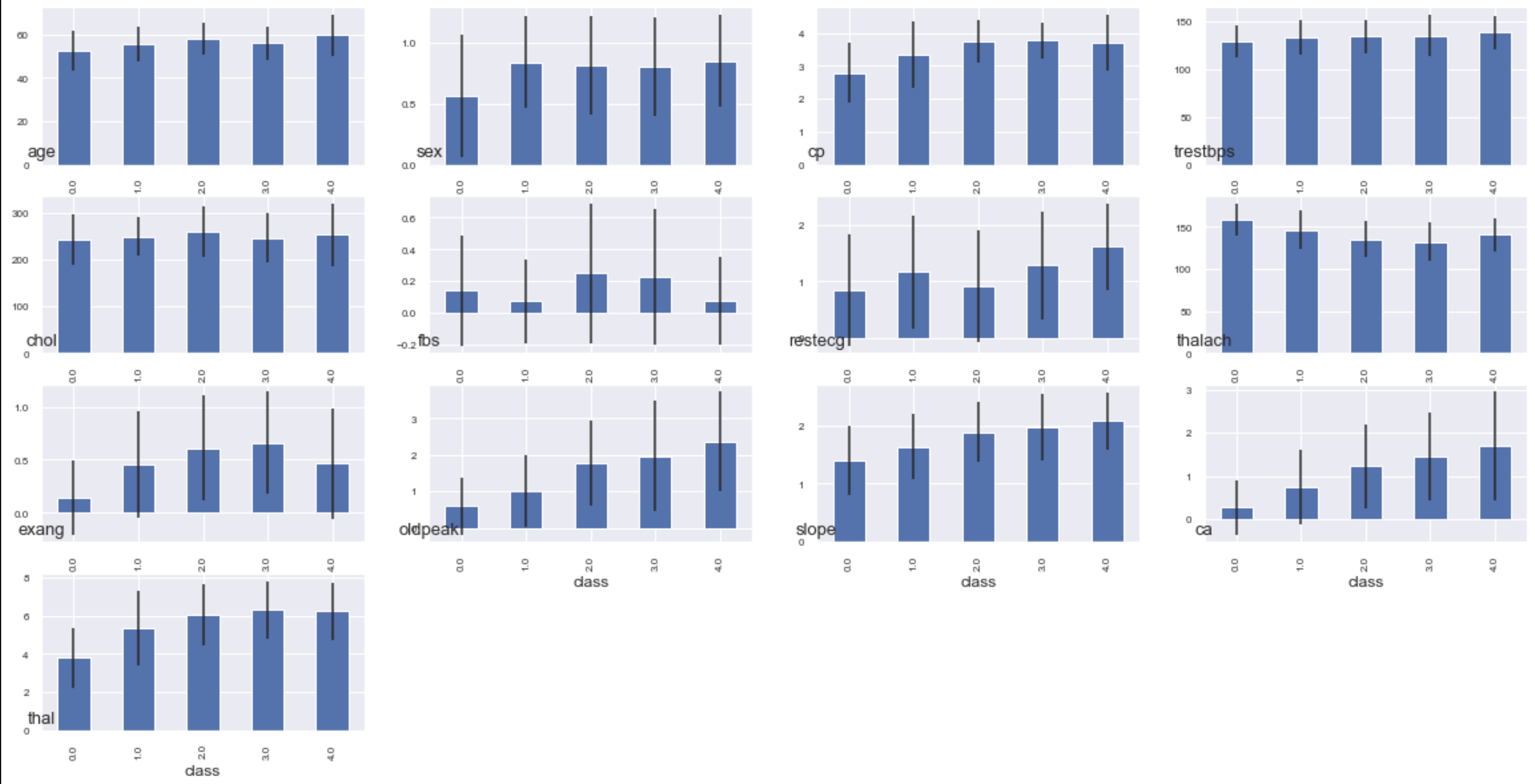
J'ai essayé de le visualiser grossièrement, mais l'histogramme de chaque classe ne peut pas être bien vu tel quel. La prochaine fois, j'analyserai à l'aide de graphiques qui peuvent être déplacés et de tracés 3D.
Analyse de données à partir de python (visualisation de données 2) https://qiita.com/CEML/items/e932684502764be09157 Analyse de données à partir de python (visualisation de données 3) https://qiita.com/CEML/items/71fbc7b8ab6a7576f514
Recommended Posts