Modèle de prétraitement pour l'analyse des données (Python)
Modèle de prétraitement pour l'analyse des données (Python)
Le prétraitement des données que j'utilise souvent est résumé dans le format de modèle ci-dessous. La description est un modèle, sans grande explication.
Charger le jeu de données
Lecture au format csv
read_data.py
trainval_filename = './train.csv'
test_filename = './test.csv'
df_trainval = pd.read_csv(trainval_filename)
df_test = pd.read_csv(test_filename)
Combiner des cadres de données avec concat
Ceci est pratique lorsque vous souhaitez prétraiter les données d'entraînement et les données de test en même temps. Après cela, utilisez-le lorsque vous souhaitez combiner des données normalement.
df_all = pd.concat([df_trainval,df_test],axis=0)
#axis=0 :Connectez-vous vers le bas
#axis=1 :Connectez-vous à droite
Conversion de variable simple
Traitement des informations de date et d'heure par to_datatime
Convertir les informations de date et d'heure en type d'horodatage, convertir en année / mois / date / jour
'''
#Avant la conversion
Date
0 1999-07-17
1 2008-02-14
2 2013-03-09
3 2012-02-02
4 2009-05-09
'''
df_all['Date'] = pd.to_datetime(df_all["Date"])
'''
#Après le traitement
0 1999-07-17
1 2008-02-14
2 2013-03-09
3 2012-02-02
4 2009-05-09
'''
Conversion des informations en date et jour après application
La même chose peut être faite en utilisant map.
df_all['Year'] = df_all['Date'].apply(lambda x:x.year)
df_all['Month'] = df_all['Date'].apply(lambda x:x.month)
df_all['Day'] = df_all['Date'].apply(lambda x:x.day)
df_all['Weekday_name'] = df_all['Date'].apply(lambda x:x.weekday_name)
'''
#Après la conversion
Year Month Day Weekday_name
0 1999 7 17 Saturday
1 2008 2 14 Thursday
2 2013 3 9 Saturday
3 2012 2 2 Thursday
4 2009 5 9 Saturday
'''
Conversion numérique des étiquettes par LabelEncoder
Convertissez les étiquettes en informations numériques. Ci-dessous, les informations sur la ville sont converties en informations numériques.
laberlencoder.py
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
df_all['City'] = le.fit_transform(df_all['City'])
Remplacement d'élément par carte
Utilisez la fonction de carte pour convertir les étiquettes en valeurs discrètes.
map.py
'''
City Group Type
0 Big Cities IL
1 Big Cities FC
2 Other IL
3 Other IL
4 Other IL #Avant la conversion
'''
df_all['City Group'] = df_all['City Group'].map({'Other':0,'Big Cities':1}) #There are only 'Other' or 'Big city'
df_all["Type"] = df_all["Type"].map({"FC":0, "IL":1, "DT":2, "MB":3}) #There are only 'FC' or 'IL' or 'DT' or 'MB'
'''
City Group Type
0 1 1
1 1 0
2 0 1
3 0 1
4 0 1 Après conversion
'''
Acquisition d'informations de données en utilisant la fonction de pandas
Obtenir des informations sur la colonne à l'aide de info ()
Vous pouvez obtenir le nombre de colonnes, la longueur de la colonne, le type de données, etc. Très pratique
df.info()
'''<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
None
'''
describe() Diverses informations telles que le nombre de données dans chaque colonne, la moyenne, la variance et le quadrant peuvent être obtenues.
df.describe()
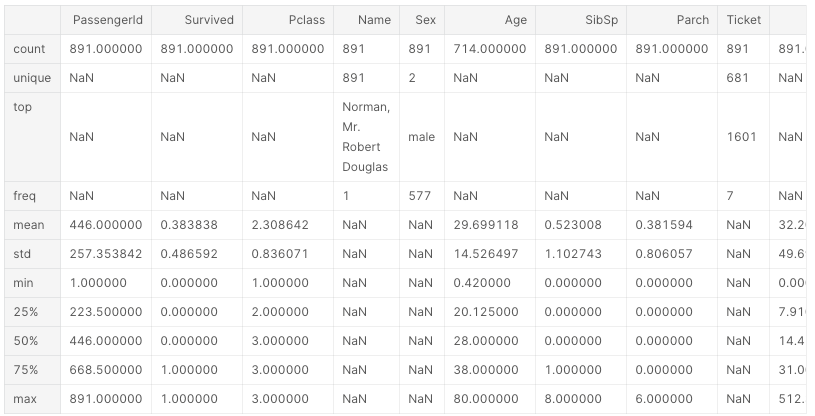
Agrégation NaN
df.isnull().sum()
'''
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
Family_size 0
'''
Remplir NaN
Il existe différentes manières de le remplir. Personnellement, je l'utilise uniquement autour des valeurs moyennes et médianes. S'il existe un autre bon moyen, faites-le moi savoir.
df['Age'].fillna(dataset['Age'].median()) #Version médiane
df['Age'].fillna(dataset['Age'].median()) #Version moyenne
df = df.dropna(how='all',axis=0) #Les colonnes où toutes les valeurs sont manquantes sont supprimées,axis=Réglez sur 1 pour les lignes.
df = df2.dropna(how='any',axis=0) #'any'Si défini sur, les lignes contenant ne serait-ce qu'un NaN seront supprimées. (Défaut)
Coefficient de corrélation par corr ()
Le coefficient de corrélation entre toutes les variables peut être calculé simplement en utilisant corr (). Très pratique.
print(df.corr())
'''
PassengerId Pclass Age SibSp Parch Fare
PassengerId 1.000000 -0.026751 -0.034102 0.003818 0.043080 0.008211
Pclass -0.026751 1.000000 -0.492143 0.001087 0.018721 -0.577147
Age -0.034102 -0.492143 1.000000 -0.091587 -0.061249 0.337932
SibSp 0.003818 0.001087 -0.091587 1.000000 0.306895 0.171539
Parch 0.043080 0.018721 -0.061249 0.306895 1.000000 0.230046
Fare 0.008211 -0.577147 0.337932 0.171539 0.230046 1.000000
Créer un histogramme avec hist ()
Utilisez simplement hist () et il dessinera un histogramme. Ceci est également très pratique.
df.hist()
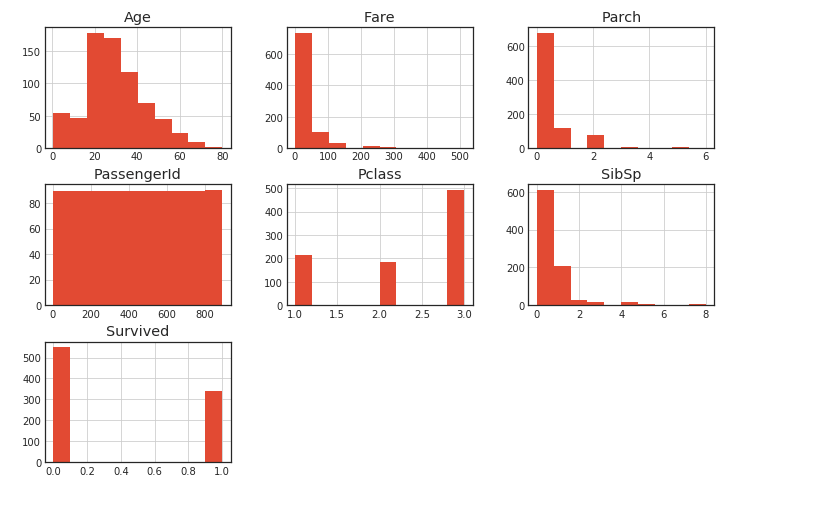
Création d'un diagramme de dispersion Scatter_matrix ()
scatter_matrix () dessine un diagramme de dispersion. Il crée un diagramme de dispersion entre toutes les variables. Le diagramme diagonal représente un histogramme de cette variable.
pd.plotting.scatter_matrix(df)
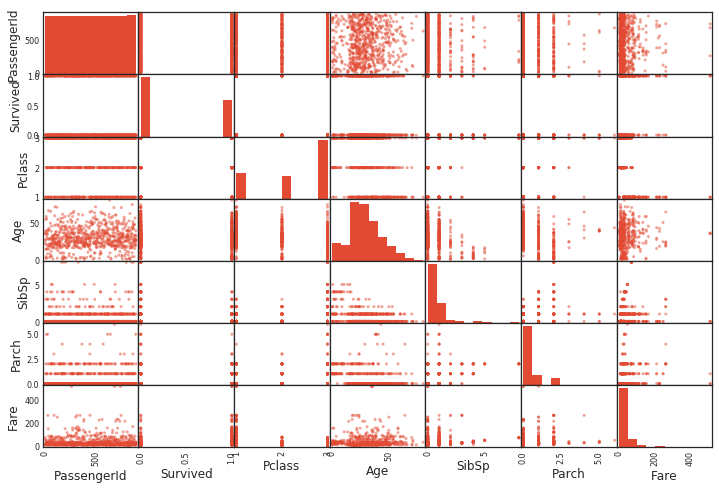
Regroupement par groupe par
La fonction groupby peut être appliquée aux variables d'étiquette. Le `` sexe '' n'a que les femmes et les hommes, il peut donc être divisé en deux Si vous ajoutez mean () après cela, la moyenne sera calculée pour chaque groupe.
print(df[['Sex', 'Survival']].groupby('Sex', as_index=False).mean())
'''
Sex Survived
0 female 0.742038
1 male 0.188908
'''
J'édite maintenant.
Recommended Posts