Modèle d'analyse de données Python
Modèle d'analyse de données Python
Lorsque vous travaillez sur kaggle, vous devez analyser les données et créer vos propres fonctionnalités. À ce moment-là, l'analyse des données est effectuée à l'aide du graphique. Dans cet article, je publierai un modèle pour créer des graphiques à des fins d'analyse de données.
Bibliothèque utilisée
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
import seaborn as sns
Observation de la corrélation
Diagramme de dispersion entre toutes les variables
Si vous utilisez des pandas, vous pouvez obtenir un diagramme de dispersion en une seule fois. Un histogramme est dessiné entre les mêmes variables. (Parce que les mêmes variables ne sont que des lignes droites)
from pandas.plotting import scatter_matrix
scatter_matrix(df)
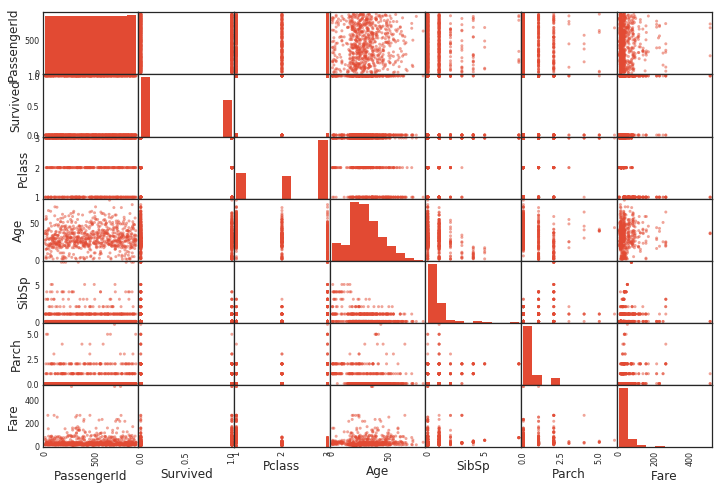
Nuage de points
De plus, un diagramme de dispersion de variables spécifiques peut être facilement créé comme suit.
df.plot(kind='scatter',x='Age',y='Survived',alpha=0.1,figsize=(4,3))
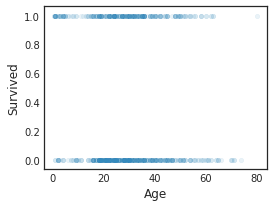
Calcul du coefficient de corrélation
Coefficient de corrélation
Le coefficient de corrélation de Pearson peut être affiché en une seule fois avec corr (). Très pratique.
data1.corr()
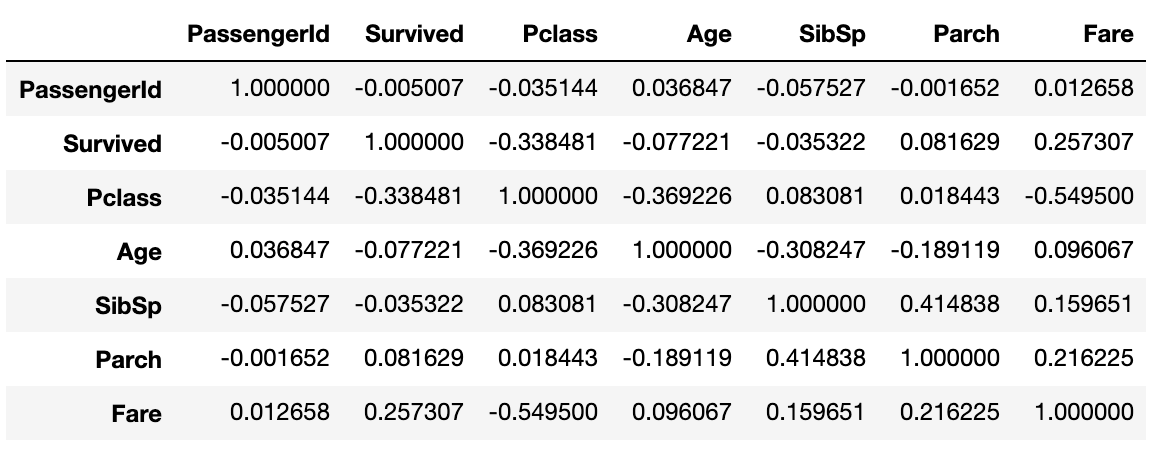
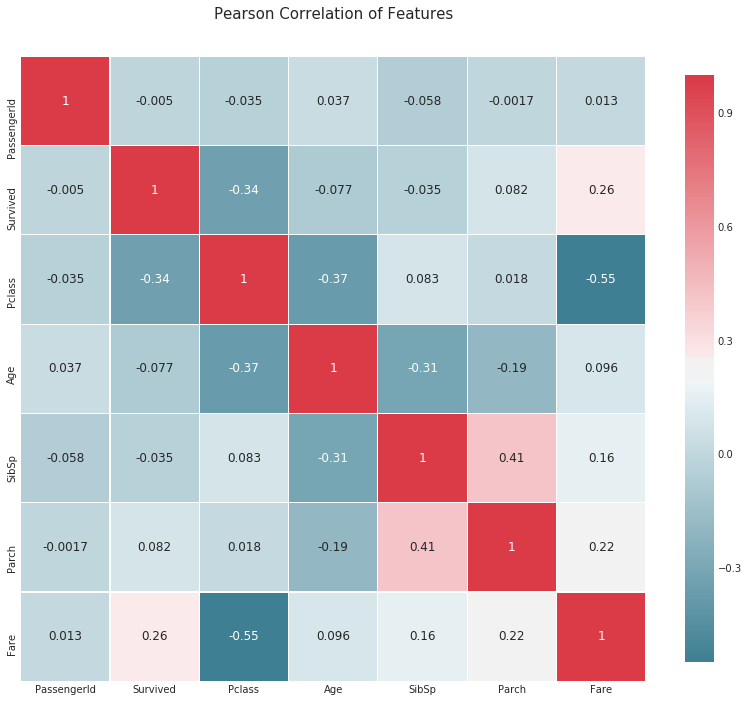
Carte thermique des coefficients de corrélation
def correlation_heatmap(df):
_ , ax = plt.subplots(figsize =(14, 12))
colormap = sns.diverging_palette(220, 10, as_cmap = True)
_ = sns.heatmap(
df.corr(),
cmap = colormap,
square=True,
cbar_kws={'shrink':.9 },
ax=ax,
annot=True,
linewidths=0.1,vmax=1.0, linecolor='white',
annot_kws={'fontsize':12 }
)
plt.title('Pearson Correlation of Features', y=1.05, size=15)
correlation_heatmap(data1)
Coefficient de corrélation pour la variable objective
corr_matrix = data1.corr()
fig,ax=plt.subplots(figsize=(15,6))
y=pd.DataFrame(corr_matrix['Survived'].sort_values(ascending=False))
sns.barplot(x = y.index,y='Survived',data=y)
plt.tick_params(labelsize=10)
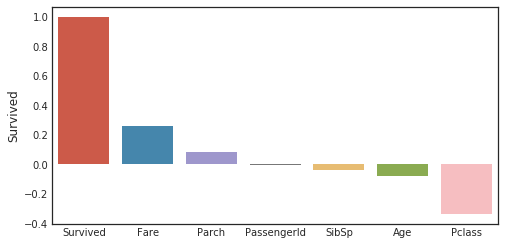
histogramme
Variante de toutes les variables
Vous pouvez l'obtenir d'un seul coup avec hist ().
df.hist()
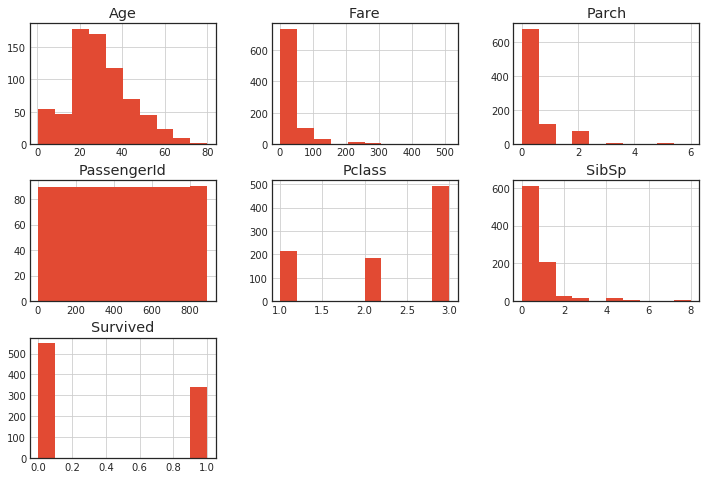
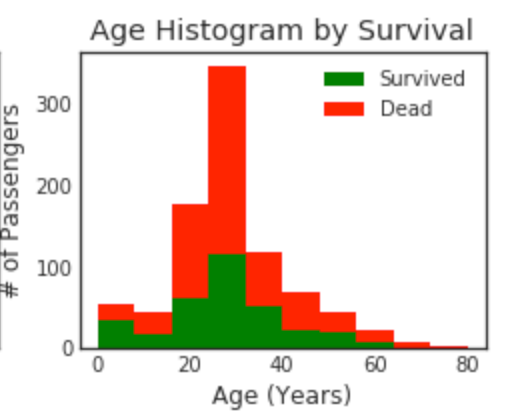
Superposer l'histogramme
plt.figure(figsize=[8,6])
plt.subplot(222)
plt.hist(x = [data1[data1['Survived']==1]['Age'], data1[data1['Survived']==0]['Age']], stacked=True, color = ['g','r'],label = ['Survived','Dead'])
plt.title('Age Histogram by Survival')
plt.xlabel('Age (Years)')
plt.ylabel('# of Passengers')
plt.legend()
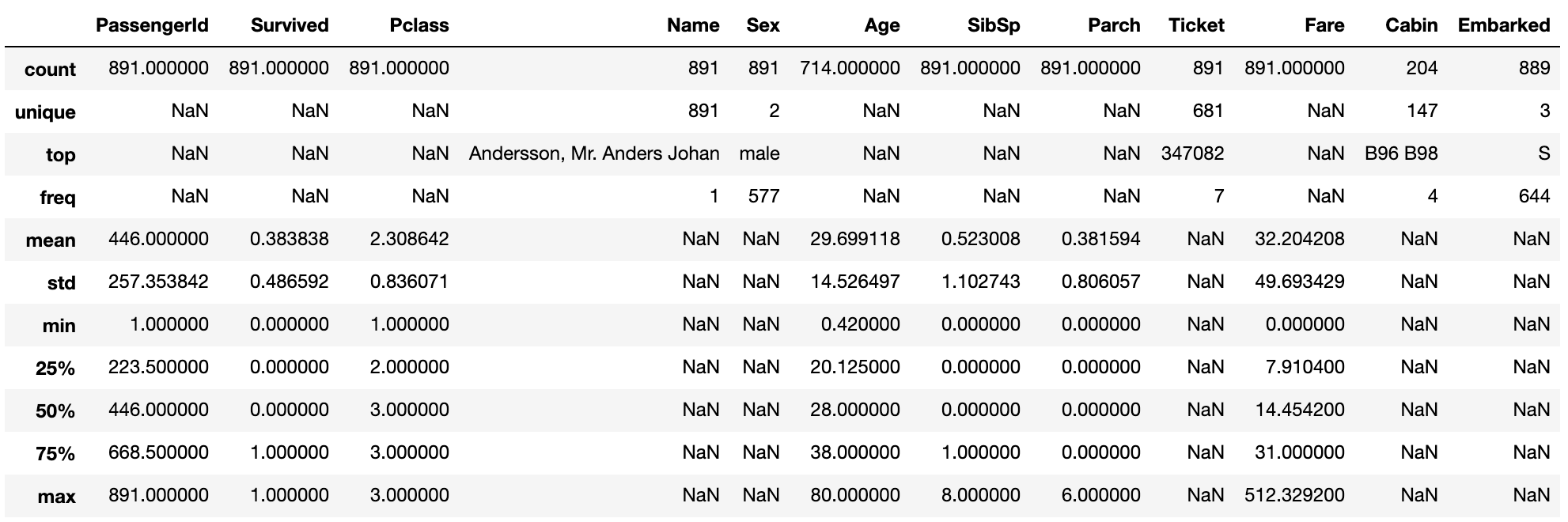
Description de la distribution variable
Si include = 'all', les quantités de caractéristiques qui ne sont pas des valeurs numériques sont également affichées.
data1.describe(include = 'all')
Quadrant
plt.figure(figsize=[8,6])
"""
o is treated as a Outlier.
minimun
25e centile premier quadrant
50e centile, deuxième quadrant (médiane)
75e centile, troisième quadrant
maximum
"""
plt.subplot(221)
plt.boxplot(data1['Age'], showmeans = True, meanline = True)
plt.title('Age Boxplot')
plt.ylabel('Age (Years)')
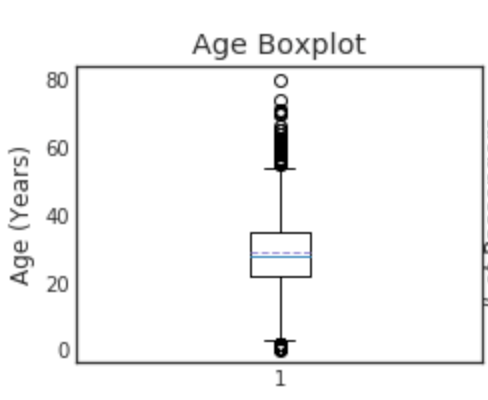
Vous pouvez consulter Boxplot pour voir s'il existe des valeurs aberrantes. Cela peut également être utilisé pour remplir les valeurs manquantes. Lorsque les valeurs aberrantes correspondent ou que la distribution est biaisée, il est préférable d'utiliser la valeur médiane plutôt que la moyenne. En revanche, si la distribution est symétrique à gauche et à droite, il peut être préférable d'utiliser la valeur moyenne.
Recommended Posts