Avoir réussi l'examen d'analyse des données de certification d'ingénieur Python
Ce n'est pas difficile, mais c'est une connaissance organisée
** [Attention] Cet article ne décrit pas directement le contenu de l'examen. ** ** Je suis passé comme le dit le titre.
 |
 |
|---|---|
| Certificat de réussite Python CDA | Résultats de test |
L'examen de certification d'ingénieur Python comprend un examen de base et un examen d'analyse de données (à compter du 27 octobre 2020). Au moins, le test d'analyse des données n'est pas si difficile, mais vous pouvez généralement le déboguer et vous pouvez rechercher la grammaire qui vous préoccupe en ligne, mais vous ne pouvez rien voir dans le test **. Il semble qu'il y ait eu beaucoup d'erreurs parce que je n'ai pris aucune mesure au sérieux. Voici quelques éléments à vérifier avant de passer cet examen.
Mathématiques / Statistiques
Premièrement, des fonctions telles que le logarithme exponentiel et les accords sinusoïdaux, les vecteurs / matrices et la différenciation / intégration sont des éléments essentiels. Je suis étudiant en sciences, donc je n'ai pas étudié pour cet examen. Les statistiques de probabilité sont également indispensables pour l'analyse des données, par exemple, la table de distribution de fréquence peut être sortie par la valeur de retour de ax.hist gérée par matplotlib.
range ou numpy
Pouvez-vous vraiment répondre à la sortie suivante? Il y a des moments où je me sens mal à l'aise. Question 1~4
import numpy as np
# Question 1
q1 = range(1, 10, 1)
print( q1 )
# Question 2
q2 = np.arange(1, 10, 1)
print( q2 )
# Question 3
q3 = np.arange(1.0, 10.0, 0.1)
print( q3 )
# Question 4
q4 = [ len( q1 ), len( q2 ), len( q3 ) ]
print( [ f'q{i+1} length = {a}' for i, a in enumerate(q4)] ) # print( q4 )
<détails>
# Answer for Question 1
range(1, 10)
# Answer for Question 2
9
# Answer for Question 3
[1. 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 2. 2.1 2.2 2.3 2.4 2.5 2.6 2.7
2.8 2.9 3. 3.1 3.2 3.3 3.4 3.5 3.6 3.7 3.8 3.9 4. 4.1 4.2 4.3 4.4 4.5
4.6 4.7 4.8 4.9 5. 5.1 5.2 5.3 5.4 5.5 5.6 5.7 5.8 5.9 6. 6.1 6.2 6.3
6.4 6.5 6.6 6.7 6.8 6.9 7. 7.1 7.2 7.3 7.4 7.5 7.6 7.7 7.8 7.9 8. 8.1
8.2 8.3 8.4 8.5 8.6 8.7 8.8 8.9 9. 9.1 9.2 9.3 9.4 9.5 9.6 9.7 9.8 9.9]
# Answer for Question 4
90
Question 5~8
# Question 5
q5 = [ i for i in range(1, 10, 3) ]
print( q5 )
q6 = q5[-1]
print( q6 )
# Question 7, Which range is true?
# 1<=q7<=9 or 1<=q7<=10 or 2<=q7<=9 or 2<=q7<=10 ?
#q7 = [ random.randint(1, 10) for i in range(100) ]
q7 = random.randint(1, 10)
print( q7 )
# Question 8, Which range is true?
# 1<=q8<=9 or 1<=q8<=10 or 2<=q8<=9 or 2<=q8<=10 ?
#q8 = [ random.randrange(1, 10) for i in range(100)]
q8 = random.randrange(1, 10)
print(q8)
<détails>
# Answer for Question 5
[1, 4, 7]
# Answer for Question 6
7
# Answer for Question 7
#ex) 9
1<=q7<=10
# Answer for Question 8
#ex) 4
1<=q8<=9
Légèrement le commentaire ci-dessus (plage)
En Python, l'utilisation de x = range (a, b) entraîne généralement un <= x <b. Même dans le cas de Numpy, il n'inclura pas 10 comme q2 = np.arange (1, 10, 1). La même chose est vraie pour les tranches. Cependant, dans le cas de q7 = random.randint (1, 10), ce n'est pas une plage, donc c'est 1 à 10 (dont 10). Si quelque chose comme ça contient des étapes comme q5 = [i pour i dans la plage (1, 10, 3)], ou devient numpy ou des fractions comme q3 = np.arange (1.0, 10.0, 0.1) , Ceux qui sont nouveaux dans Python peuvent être confus. Utilisons-le bien pour que vous puissiez sortir le résultat dans votre tête.
Expressions régulières
Si vous ne l'avez pas utilisé, utilisez simplement "| (ou)" et "? (0 ou 1 fois)".
import re
prog = re.compile('Mori(i|mori)t(a)?k(a)?y(o)?s(hi)?', re.IGNORECASE)
ret = prog.search('Moriitkys')
print(ret[0])
ret = prog.search('Moritkys')
print(ret[0])
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-48-3f281450d109> in <module>()
4 print(ret[0])
5 ret = prog.search('Moritkys')
----> 6 print(ret[0])
TypeError: 'NoneType' object is not subscriptable
Comme mentionné ci-dessus, dans le cas de (i | mori), l'un ou l'autre doit être inclus. D'autre part, dans le cas de t (a)?, Seul "t" ou "ta" est autorisé.
Pandas Est-ce une caractéristique du test d'analyse des données? Pouvez-vous mémoriser avec précision les détails des pandas? Par exemple, voyez la différence entre loc et iloc dans un bloc de données.
import pandas as pd
df = pd.DataFrame([[101, "a", True],[102, "b", False],[103, "c", False]])
df.index = ["01", "02", "03"]
df.columns = ["A", "B", "C"]
a1 = df.loc["03", "A"]
a2 = df.iloc[2, 0]
print(a1, a2)
Réponse (peut s'afficher par défaut selon le navigateur)
Dans les deux cas, 103 est la sortie. Pour la spécification d'élément, spécifiez un index ou des colonnes pour df.loc et spécifiez la valeur numérique à partir de 0e pour df.iloc. Ceci est également inclus dans le livre de référence, donc si vous voulez passer l'examen, vous devez le mémoriser.
Dans les deux cas, 103 est la sortie. Pour la spécification d'élément, spécifiez un index ou des colonnes pour df.loc et spécifiez la valeur numérique à partir de 0e pour df.iloc. Ceci est également inclus dans le livre de référence, donc si vous voulez passer l'examen, vous devez le mémoriser.
De plus, il y a beaucoup de choses à vérifier dans df.head, comme le nombre de lignes de données à prendre depuis le début et les détails du traitement des valeurs manquantes (dropna et fillna).
Matplotlib Si vous en avez envie, je vais résumer quelque chose, mais par exemple, le style du graphique, le réglage du titre, etc. sont également écrits dans le texte, vous devez donc le vérifier. En particulier, les types de graphiques (ax.bar, ax.scatter, ax.hist, ax.boxplot, ax.pie, etc.) sont des éléments obligatoires comme titre de test de l'analyse des données.
Apprentissage automatique
Il existe différentes méthodes d'apprentissage automatique. Arbre de décision, analyse en composantes principales, NN, etc. Bien entendu, un analyste de données doit pouvoir tout utiliser. Cependant, je pense qu'il est nécessaire de revoir l'algorithme, l'explication de la méthode, scikit-learn, etc. pour la méthode qui n'est pas souvent utilisée. Dans le livre de référence, j'ai senti que l'apprentissage avec les enseignants et l'apprentissage sans les enseignants étaient confus (n'est-ce pas le cas?), Alors vous voudrez peut-être étudier avec ou sans enseignants. Hmm.
Résumé de l'apprentissage automatique
・ ** Prétraitement des données (traitement des valeurs manquantes, normalisation des fonctionnalités, etc.) ** Pour le traitement des valeurs manquantes, le traitement des valeurs manquantes mentionné ci-dessus par Pandas est introduit. Veuillez consulter le livre de référence pour plus de détails. La normalisation des fonctionnalités nécessite des connaissances telles que les statistiques de probabilité (normalisation distribuée, normalisation maximale, etc.). En outre, lors du prétraitement, il est important de sélectionner la quantité de caractéristiques des données et d'exclure les valeurs aberrantes (en dehors de la plage de test?), Mais pour le moment, vous devez vérifier le contenu dans le livre de référence.
・ ** Apprendre avec l'enseignant ** Le livre de référence explique la machine à vecteurs de support (SVC de sklearn.svm) et le modèle de régression linéaire (LinearRegression de sklearn.linear_model), veuillez donc vérifier ici pour plus de détails.
・ ** Apprendre sans professeur ** L'ouvrage de référence explique l'arbre de décision (DecisionTreeClassifier de sklearn.tree), la forêt aléatoire (RandomForestClassifier de sklearn.ensemble), la réduction de dimension (PCA de sklearn.decomposition) et le clustering (KMcluseans of sklearn.tree, AgglomerativeClustering of sklearn.cluster). Veuillez vérifier ici pour plus de détails.
・ ** Renforcer l'apprentissage ** Seule une brève explication apparaît dans le livre de référence.
・ ** Codage variable ** ** [Codage de la variable de catégorie] ** Les humains donnent des noms aux objets afin qu'ils puissent facilement reconnaître le monde dans lequel ils vivent. Par exemple, les deux organes sensoriels attachés à l'avant de la tête humaine qui reçoivent la lumière sont appelés «yeux», et les organes olfactifs et respiratoires attachés à l'avant de la tête humaine sont appelés «nez». Même si l'objet est interprété par le type de caractère de cette manière, si vous souhaitez le classer par calcul, l'entrée et la sortie doivent être une séquence de nombres (valeur numérique). Le travail d'association de la valeur numérique avec la cible réelle est le codage de variables catégorielles.
 |
|---|
| Schéma conceptuel du codage des variables catégorielles |
Plus précisément, j'expliquerai où se trouve le codage des variables catégorielles dans le programme que j'ai créé plus tôt.
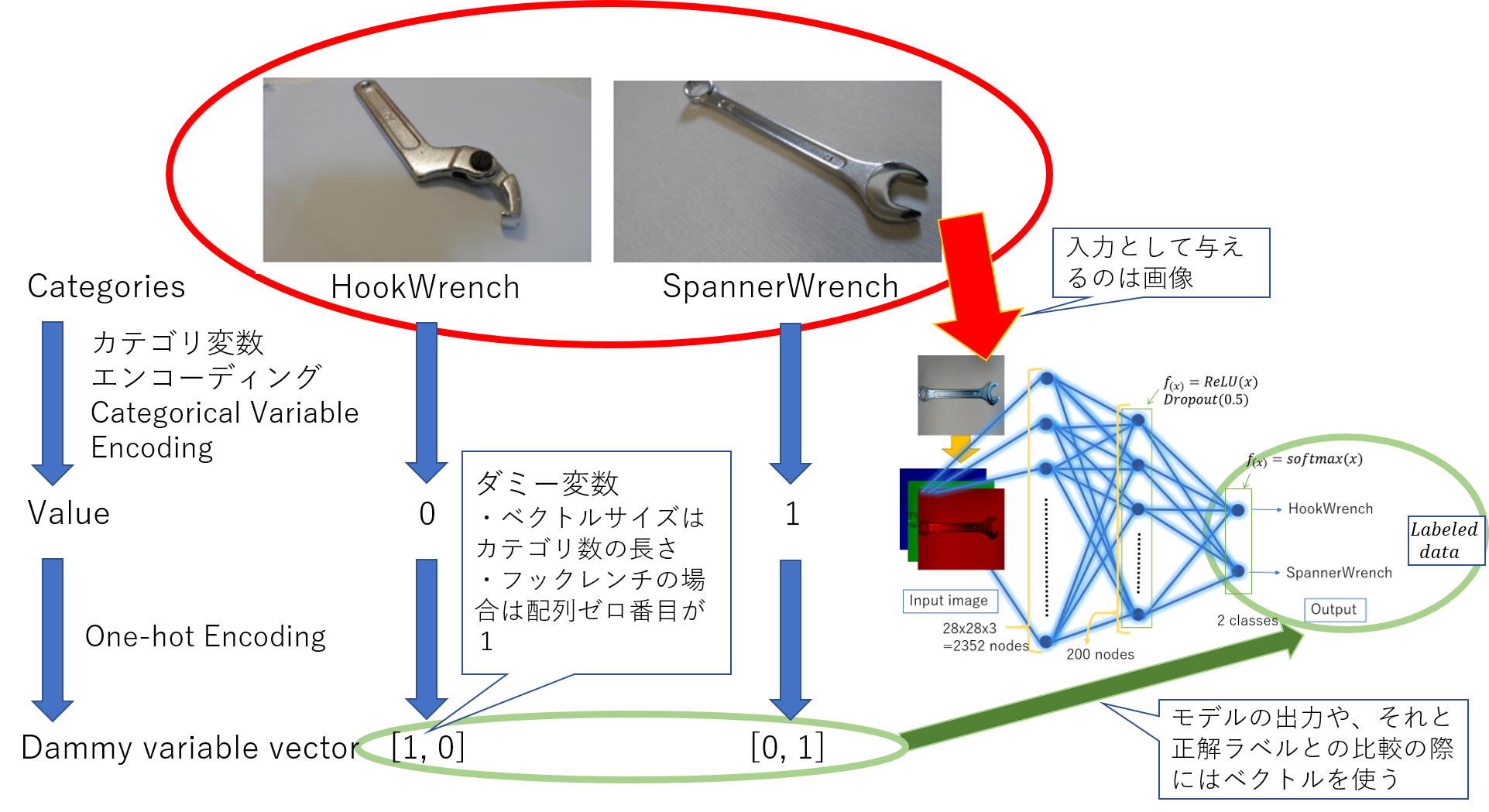 |
|---|
| Codage de variable de catégorie, un-Schéma conceptuel du codage à chaud |
La page suivante est un article sur la classification de la clé à ergot et de la clé à molette à l'aide de PyTorch et Keras. https://qiita.com/moriitkys/items/316fcca8d83dfa706597 Dans ce cas, l'encodage de la variable catégorielle est l'affectation du dictionnaire exécuté dans la cellule 1, ligne 56 du programme MyOwnNN_pytorch.ipynb de GitHub (GitHub-moriitkys / MyOwnNN).
#How many classes are in "dataset" folder
categories = [i for i in os.listdir(os.getcwd().replace("/mylib", "") + "/dataset")]
categories_idx = {}#ex) HookWrench:0, SpannerWrench:1
for i, name in enumerate(categories):
categories_idx[name] = i
nb_classes = len(categories)#ex) nb_classes=2
Dans ce cas, la clé à ergot est convertie à 0 et la clé à molette à 1. Pour l'encodage de variables catégorielles, la méthode de sklean.preprocessing est introduite dans le livre de référence.
** [Codage à chaud] ** C'est aussi le travail nécessaire pour obtenir le résultat souhaité par le calcul. Comme il est souvent plus pratique de traiter les entrées et les sorties comme des tableaux dans l'apprentissage automatique, il est également nécessaire de convertir l'ensemble de données de valeurs scalaires en tant que tableau. Par exemple, s'il existe deux catégories, clé à molette: 0 et clé à crochet: 1, convertissez la clé à molette en [1, 0] et la clé à ergot en [0, 1].
Plus précisément, j'expliquerai où se trouve le codage des variables catégorielles dans le programme que j'ai créé plus tôt. Le codage à chaud se situe autour de la 13e à la 16e ligne de la cellule 3.
y_train1=np_utils.to_categorical(y_train,nb_classes)
y_val1=np_utils.to_categorical(y_val,nb_classes)
Deux méthodes d'encodage one-hot, sklean et pandas, sont présentées dans le livre de référence.
・ ** Évaluation du modèle ** ** [Indice d'évaluation des catégories] ** Je peux le comprendre, mais je ne sais pas si je le mémorise, alors je l'ai résumé. Cette explication est également incluse dans le livre de référence, c'est donc une bonne idée de la vérifier.
| Exemple positif | Exemple négatif | |
|---|---|---|
| Exemple positif et prédiction | TP | FP |
| Cas négatifs et prédictions | FN | TN |
TP (True Positive): Prédit comme un exemple positif et en fait un exemple positif FP (False Positive): Prédit comme un exemple positif, mais en fait un exemple négatif FN (False Negative): Prédit comme un exemple négatif, mais en fait un exemple positif TN (True Negative): Prédit comme un cas négatif et en fait un cas négatif
** Taux de conformité **: Pourcentage de cas positifs réels par rapport aux cas positifs prévus. ・ Formule de taux de conformité P = TP / (TP + FP) ・ Le taux de précision est considéré comme un indicateur de la petite taille des erreurs dans la classe de prédiction. ** Taux de rappel **: Pourcentage de cas positifs réels qui devraient être corrects. ・ Formule de taux de rappel R = TP / (TP + FN) ・ Il y a un compromis entre le rappel et la précision ** Valeur F **: Moyenne harmonisée de précision et de rappel. ・ F = 2PR / (P + R) ・ Indicateur qui améliore l'équilibre entre P et R ** Taux de réponse correcte **: pourcentage de données dont les prévisions et les résultats réels correspondent ・ Formule de taux de réponse correcte A = (TP + TN) / (TP + FP)
** [Précision de la probabilité de prédiction] ** Si vous le connaissez, il n'y a rien de mal à cela, mais le livre de référence mentionne la courbe ROC (roc_curve dans sklearn.metrics).
Sommaire
Vous devriez étudier correctement. Je ne pense pas qu'il soit possible de faire quelque chose comme mémoriser un examen simulé. La mémorisation des livres de référence peut être utile, mais elle doit être comprise.
Livre de référence
Nouveau manuel d'analyse de données utilisant Python (M. Terada, Shingo Tsuji, Takanori Suzuki, Shintaro Fukushima)
Auteur de cet article
moriitkys Takayoshi Morii Faites un robot. Je suis intéressé par l'IA / la robotique / les graphismes 3D. Récemment, j'ai réfléchi à la façon de gagner de l'argent et je prévois de fabriquer du matériel avec cet argent. Qualification / Certification: test G, test d'analyse des données de certification d'ingénieur Python, test d'implémentation AI grade A, TOEIC: 810 (2019/01/13)
Recommended Posts