Analyse de données pour améliorer POG 3 ~ Analyse de régression ~
Revoir jusqu'à la dernière fois
Analyse des données pour améliorer POG 2 ~ Analyse avec jupyter notebook ~ montre la relation causale entre le profil du cheval et les prix gagnés pendant la période POG. En analysant, nous avons pu saisir des tendances générales telles que «les chevaux femelles sont désavantageux» et «la naissance précoce est plus avantageuse».
But de cette fois
Déterminer la possibilité de prédire les prix de la période POG en fonction du profil du cheval par analyse de régression.
L'analyse des données
Traitement des données qualitatives
Jetons un coup d'œil au contenu des données à analyser à nouveau.

Puisque nous voulons prédire le montant du prix en fonction du profil de chaque cheval, la variable objective est "POG period prize_year-round" et les variables explicatives sont "sexe", "mois de naissance", "entraîneur", "propriétaire du cheval", "producteur". , "Origine", "Prix de transaction Seri", "Père", "Mère et père" seraient appropriés. Cependant, comme aucune relation significative n'a été trouvée dans l'analyse précédente, le "prix de transaction seri" est cette fois exclu de l'analyse.
En passant, parmi les variables explicatives, les données autres que le «prix de transaction seri» sont des données dites qualitatives. Par conséquent, l'analyse de régression ne peut pas être effectuée telle quelle.
Dans un tel cas, il semble qu'il s'agisse d'une méthode générale * pour effectuer une analyse de régression après avoir converti des données qualitatives en variables fictives afin qu'elles puissent être traitées comme des données quantitatives.
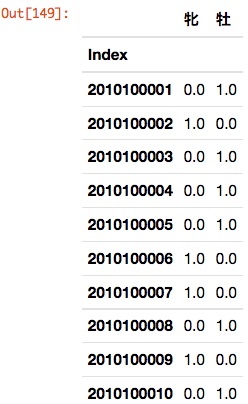
pandas a une fonction pour convertir les données qualitatives en variables factices. Un exemple est présenté ci-dessous.
python
horse_df = pd.read_csv('./horse_db/horse_prof_2010_2014_mod.csv', encoding='utf-8', header=0, index_col=0)
pd.get_dummies(horse_df[u'sexe'])[:3]
Analyse de régression simple
Dans cette analyse, la méthode OLS (méthode du carré minimum) du module statsmodels est utilisée. Le code utilisé pour l'analyse est indiqué ci-dessous.
python
#Importation de module
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(font='Osaka')
import statsmodels.api as sm
import IPython.display as display
%matplotlib inline
#Lire les données de la source d'analyse
horse_df = pd.read_csv('./horse_db/horse_prof_2010_2014_mod.csv', encoding='utf-8', header=0, index_col=0)
#horse_df = horse_df[:50]
#Convertir des données qualitatives en variables factices
use_col = [
u'sexe',
#u'Le mois de naissance',
#u'Entraîneur',
#u'Propriétaire de cheval',
#u'Producteur',
#u'Origine',
#u'père',
#u'Mère père',
]
if len(use_col) == 1:
dum = pd.get_dummies(horse_df[use_col[0]])
else:
dum = pd.get_dummies(horse_df[use_col])
# X,Définition de y
X_col = dum.columns
y_col = u'Prix de la période POG_Toute l'année'
tmp_df = pd.concat([dum, horse_df[y_col]], axis=1)
tmp_df = tmp_df.dropna()
tmp_df = tmp_df.applymap(np.int)
X = tmp_df[X_col].ix[:,:]
X = sm.add_constant(X)
y = tmp_df[y_col]
#Génération de modèle
model = sm.OLS(y,X)
#résultat
results = model.fit()
y_predict = results.predict()
plt.plot(y_predict, y, marker='o', ls='None', label='_'.join(use_col))
plt.xlabel(u'Prévoir')
plt.ylabel(u'Mesure réelle')
plt.legend(loc=0)
plt.title('R^2: %.3f, F: %.3f' % (results.rsquared, results.fvalue))
plt.savefig('./figure/fig_'+'_'.join(use_col)+'.png')
#display.display(results.summary())
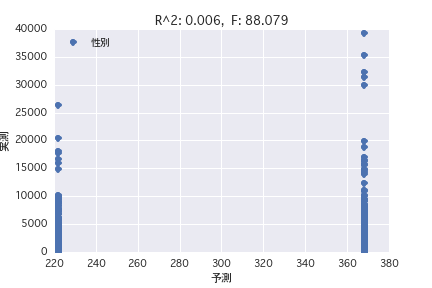
sexe
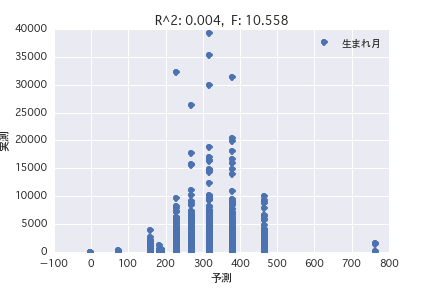
Le mois de naissance
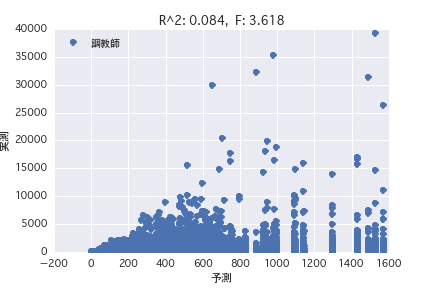
Entraîneur
Propriétaire de cheval
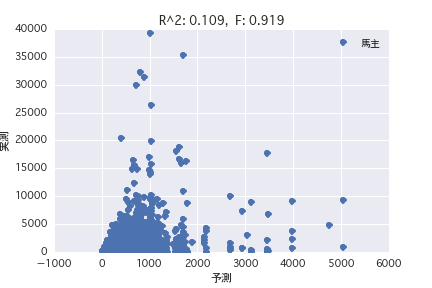
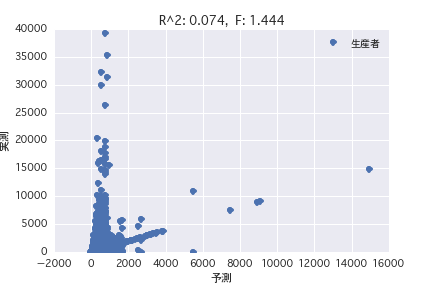
Producteur
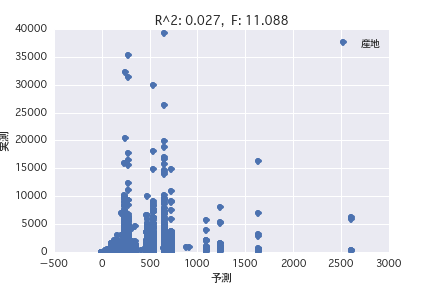
Origine
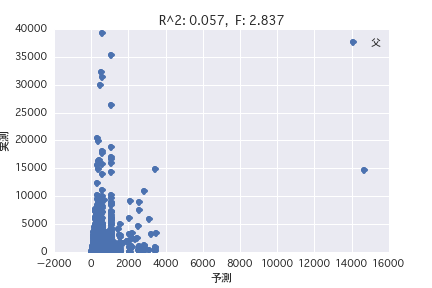
père
Mère père
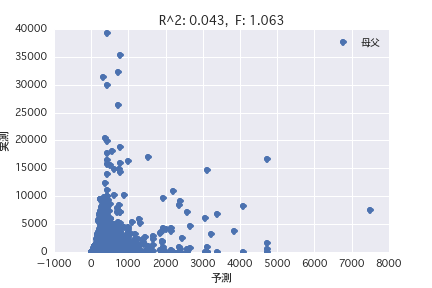
Analyse de régression multiple
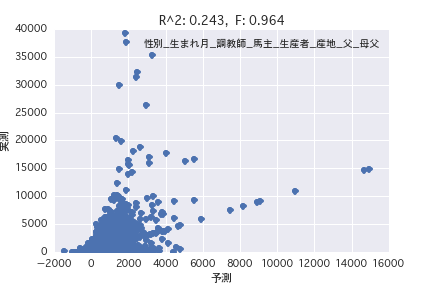
Ce résumé
Une analyse de régression a été réalisée avec la variable objective comme «période POG prix_année-ronde» et la variable explicative comme différents profils de chevaux («sexe», «père», etc.). Il a été constaté qu'il est difficile de prédire le montant du prix à partir du profil du cheval parce que R ^ 2 est petit à la fois dans l'analyse de régression simple et dans l'analyse de régression multiple.
à partir de maintenant
Analyse de discrimination (identification des chevaux non primés, moyens ouverts, chevaux de première classe) Analyse axée sur le pedigree
Recommended Posts