Analyse des données pour améliorer POG 2 ~ Analyse avec le notebook jupyter ~
Revoir jusqu'à la dernière fois
Analyse des données pour améliorer POG 1 ~ web scraping avec Python ~ montre le profil des chevaux nés entre 2010 et 2013 (sexe, pedigree, écuries). Etc.) et a remporté des prix pendant la période POG. Les données obtenues sont enregistrées séparément pour chaque année de naissance sous le nom de fichier "horse_db / horse_prof_ (yyyy) .csv".
But de cette fois
Cette fois, sur la base de ces données, j'aimerais analyser la relation causale entre le profil du cheval et les prix gagnés pendant la période POG, et trouver la loi de la victoire POG.
Malheureusement, je ne suis pas un spécialiste de l'analyse de données. Par conséquent, il sera possible de tirer des conclusions par essais et erreurs. En fin de compte, on s'attend à ce que l'analyse de régression multiple et l'apprentissage automatique soient pris en charge, mais j'aimerais d'abord comprendre les caractéristiques de chaque facteur par une simple analyse.
L'analyse des données
Cette fois, nous allons procéder à l'analyse sur un ordinateur portable Jupyter qui semble convenir à l'analyse des données, y compris les essais et erreurs. De plus, le module pandas permet de calculer des statistiques (moyenne, variance, etc.) pour chaque facteur.
Préparation
Tout d'abord, une trame de données à analyser est générée.
AnalyseUmaData_160105.ipynb
import os
import pandas as pd
year_l = range(2010, 2014)
masta_df = pd.DataFrame()
for year in year_l:
i_dname = './horse_db/'
i_fname = 'horse_prof_%d.csv' % year
i_fpath = os.path.join(i_dname, i_fname)
tmp_df = pd.read_csv(i_fpath,index_col=0, header=0, encoding='utf-8')
masta_df = pd.concat([masta_df, tmp_df])
masta_df[:10]
Une partie de la trame de données générée est représentée ci-dessous.
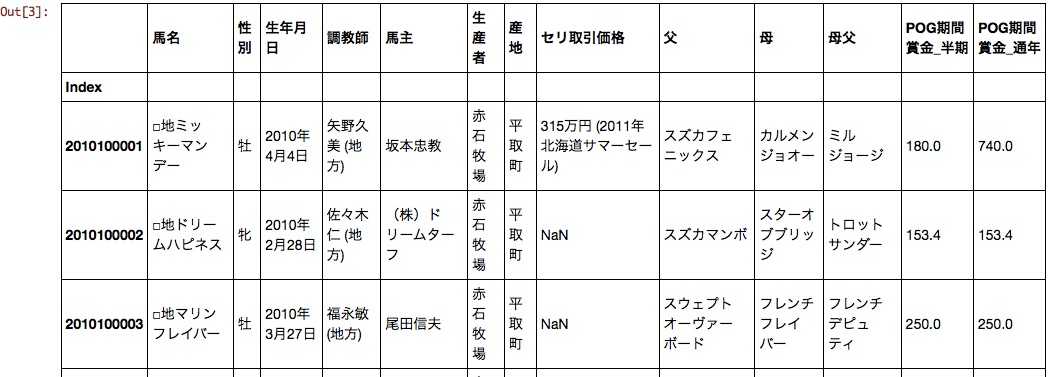
Le sexe, la date de naissance, l'entraîneur, le propriétaire du cheval, le producteur, le prix de la transaction sérielle, le père, la mère et le père sont susceptibles d'affecter le prix de la période POG.
Dans l'état actuel des choses, la date de naissance et le prix de la transaction sont difficiles à gérer, je vais donc le modeler un peu.
AnalyseUmaData_160105.ipynb
import datetime
#Anniversaire=>Année de naissance, mois de naissance
birth_y = masta_df[u'Anniversaire'].dropna().map(lambda x: datetime.datetime.strptime(x.encode('utf-8'), '%Y année%m mois%jour j').strftime('%Y'))
birth_y.name = u'Année de naissance'
birth_m = masta_df[u'Anniversaire'].dropna().map(lambda x: datetime.datetime.strptime(x.encode('utf-8'), '%Y année%m mois%jour j').strftime('%m'))
birth_m.name = u'Le mois de naissance'
df = pd.concat([masta_df, birth_y, birth_m], axis=1)
#Chaîne de caractères du prix de la transaction Seri=>Quantifier
df[u'Prix de transaction Seri'] = masta_df[u'Prix de transaction Seri'].fillna('-1')
df[u'Prix de transaction Seri'] = df[u'Prix de transaction Seri'].dropna().map(lambda x: x.replace(',', ''))
df[u'Prix de transaction Seri'] = df[u'Prix de transaction Seri'].dropna().map(lambda x: int(x.split(u'Dix mille yens')[0]))
df[:10]
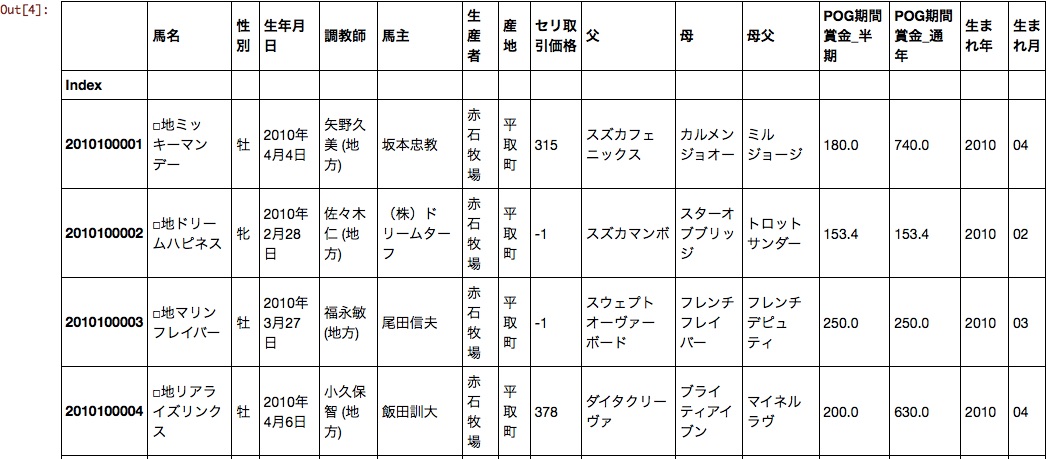
La date de naissance était divisée en année de naissance et en mois de naissance. Vous pouvez désormais gérer le prix de la transaction Seri, l'année de naissance et le mois de naissance sous forme de données numériques.
une analyse
Commençons l'analyse immédiatement. À la suite d'essais et d'erreurs, le script d'agrégation de données s'est établi sous la forme suivante.
AnalyseUmaData_160105.ipynb
import numpy as np
#Variable explicative
param_l = [u'sexe', u'Le mois de naissance', u'Entraîneur', u'Propriétaire de cheval', u'Producteur', u'père', u'母père']
#Variable objectif
prize_l = [u'Prix de la période POG_demi-période',u'Prix de la période POG_Toute l'année']
#Réglage
param = param_l[0]
prize = prize_l[1]
pts_filter = 5
prize_filter = 1000 #Filtre de prix
#Agrégat
ser_ave = df.groupby(param).mean()[prize]
ser_ave.name = u'prize>=0_ave'
ser_std = df.groupby(param).std()[prize]
ser_std.name = u'prize>=0_std'
ser_pts = df.groupby(param).size()
ser_pts.name = u'prize>=0_pts'
ser_fave = df[df[prize]>=prize_filter].groupby(param).mean()[prize]
ser_fave.name = u'prize>=%d_ave' % prize_filter
ser_fstd = df[df[prize]>=prize_filter].groupby(param).std()[prize]
ser_fstd.name = u'prize>=%d_std' % prize_filter
ser_fpts = df[df[prize]>=prize_filter].groupby(param).size()
ser_fpts.name = u'prize>=%d_pts' % prize_filter
ser_fper = (df[df[prize]>=prize_filter].groupby(param).size()/df.groupby(param).size()).map(lambda x: float(x)*100)
ser_fper.name = u'prize>=%d_pts / prize>=0_pts [%%]' % prize_filter
result = pd.concat([ser_ave, ser_std, ser_pts, ser_fave, ser_fstd, ser_fpts, ser_fper],axis=1)
result.index.name = '%s_%s' % (param, prize)
result = np.round(result.sort_values(by=ser_fper.name, ascending=0),2)
result[result[ser_fpts.name] >= pts_filter][:10]
Dans chaque colonne, le prix est égal ou supérieur à 0, c'est-à-dire la valeur moyenne, la dispersion, le score lorsque tous les chevaux sont la population, Valeur moyenne, variance, score, lorsque le prix est de 10 millions de chevaux ou plus en tant que population Il montre également le pourcentage de chevaux avec des prix de 10 millions ou plus.
sexe
Le résultat était l'avantage de Senma, mais il n'est pas certain qu'il ait été Senma pendant la période POG. Au moins, le cheval femelle se révèle être désavantagé.

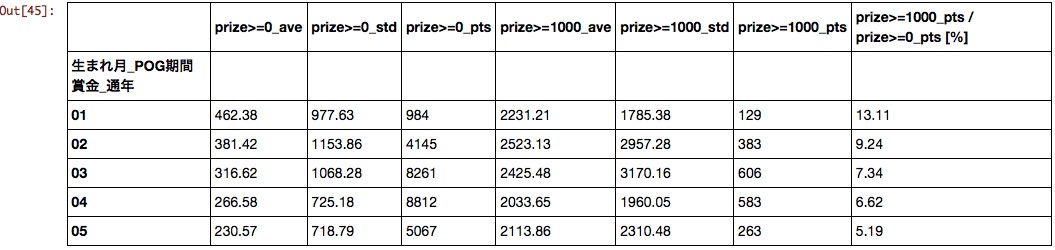
Le mois de naissance
Le plus tôt vous êtes né, mieux c'est.
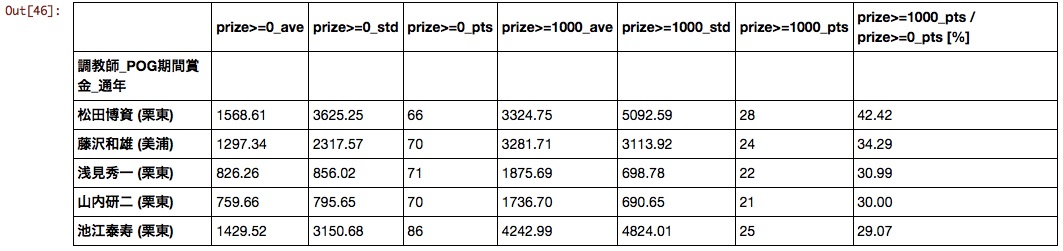
Entraîneur
Je pense que le classement changera autant que possible en fonction du réglage du filtre de prix, mais lorsqu'il est trié à un taux de 10 millions ou plus, les résultats suivants ont été obtenus.
Il est dommage que les écuries Matsupaku, qui devraient prendre leur retraite en février 2016, se soient classées premières.
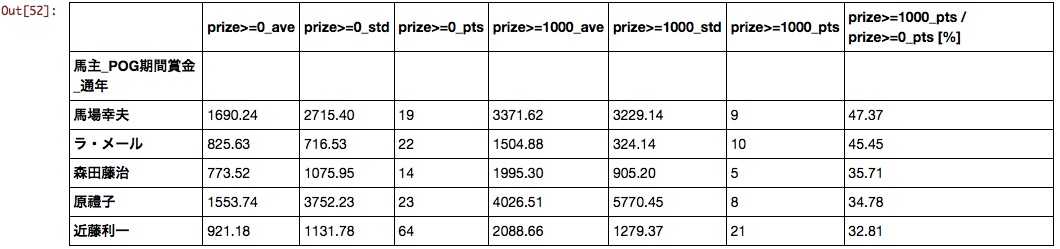
Propriétaire de cheval
Étonnamment, les clubs qui produisent des chevaux actifs en G1 ne sont pas arrivés au sommet. Y a-t-il une grande différence entre les coups et les ratés pour les chevaux de club?
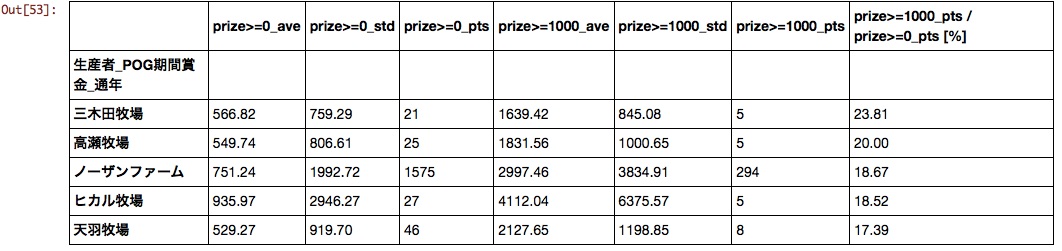
Producteur
Jusqu'à présent, j'avais choisi des chevaux avec l'idée de «ferme nordique pour le moment si je me perdais», mais j'ai obtenu des données qui confirment que c'est une idée raisonnablement raisonnable.
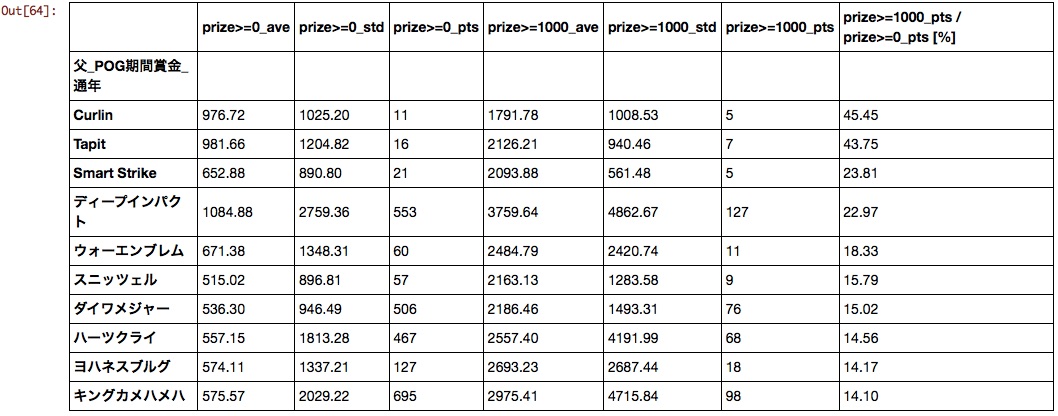
père
Des chevaux étrangers inconnus sont arrivés au sommet. Compte tenu de la population et des valeurs moyennes, on peut dire que Deep, Da Major, Hearts et Kinkame sont pour POG.
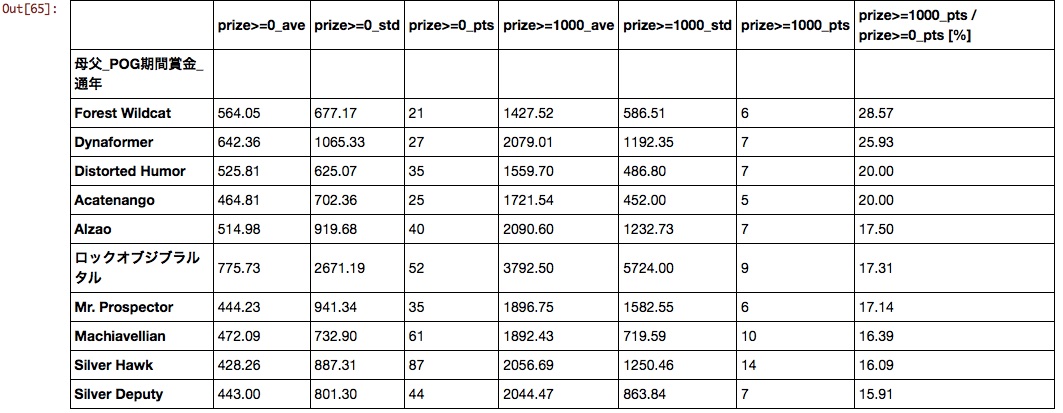
Mère père
Je ne sais plus ce que c'est. Ces dernières années, il semble nécessaire de réévaluer la combinaison du père et de la mère, car les bons résultats des chevaux nés de la combinaison de "Stay Gold" x "Mejiro McQueen" et "Deep Impact" x "Storm Cat" sont devenus un sujet brûlant.
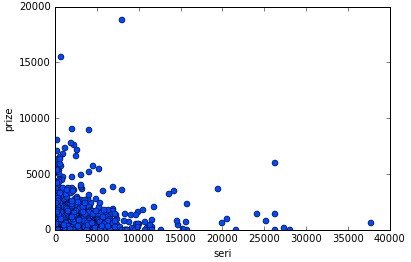
Prix de transaction Seri
Axe horizontal: prix de la transaction Seri, axe vertical: un diagramme de dispersion des prix de la période POG a été créé. Il semble qu'il n'y ait pas lieu de s'inquiéter du prix de la transaction seri dans POG, car aucune corrélation significative ne peut être trouvée.
AnalyseUmaData_160105.ipynb
%matplotlib inline
import matplotlib.pyplot as plt
#Variable explicative
param = u'Prix de transaction Seri'
#Variable objectif
prize_l = [u'Prix de la période POG_demi-période',u'Prix de la période POG_Toute l'année']
prize = prize_l[1]
#Nuage de points
x = df[df[param]>0][param]
y = df[df[param]>0][prize]
plt.plot(x, y, linestyle='None', marker='o')
plt.xlabel('seri')
plt.ylabel('prize')
plt.show()
Ce résumé
Pour résumer les résultats obtenus dans cette analyse, si vous sélectionnez un cheval qui est un étalon précoce et qui est une pièce de production de Deep Impact, Daiwa Major, Hearts Cry ou King Kamehameha et appartient à un propriétaire individuel, vous pouvez sélectionner un cheval qui gagnera avec une probabilité raisonnable. Il s'avère que c'est le cas.
Cependant, dans cette analyse, il y a encore place à l'amélioration, comme le fait que le seuil de prix a été fixé à 10 millions et que l'effet de la combinaison de chaque facteur n'a pas pu être vérifié, il n'est donc pas possible de tirer facilement une conclusion. Sur la base de ce résultat, il semble nécessaire de revoir la méthode d'analyse elle-même.
à partir de maintenant
Travail sur la visualisation de données, l'analyse de régression multiple, l'apprentissage automatique, etc.
Recommended Posts