Une histoire qui facilite l'estimation de la surface habitable à l'aide d'Elasticsearch et de Python
Aperçu
En enregistrant les informations de localisation de l'historique des actions dans Elasticsearch, je parlerai de la manière dont elles peuvent être utilisées de manière agréable et également visualisées de manière agréable.
Connaissances préalables

J'utiliserai la recherche élastique cette fois, je vais donc la présenter brièvement. Elasticsearch est l'un des moteurs de recherche en texte intégral souvent comparé à Apache Solr. Il est sans schéma et toutes les entrées et sorties sont REST et JSON. Il est également implémenté en Java.
- Pour plus de détails, Introduction et fonctionnalités d'Elasticsearch
L'installation est facile avec miam ou infusion. Veuillez vérifier en fonction de l'environnement que vous souhaitez utiliser. En passant, elasticsearch-head, un plug-in d'interface graphique pour Elasticsearch, est pratique, c'est donc une bonne idée de l'inclure également.
Paramètres d'Elasticsearch
Après avoir démarré Elasticsearch, définissez l'index à utiliser (comme une table dans la base de données). Pour cela, créez d'abord une méthode de mappage d'index avec json. Cette fois, on suppose qu'il existe un journal de l'ensemble de données suivant.
sample_log
{
"id":1,
"uuid":"7ef82126c32c55f7272d5ca5dd5e40c6",
"time":"2015-12-03T04:21:01.641Z",
"lat":35.658546,
"lng":139.729281,
"accuracy":47.126048
}
Définissez le type de chaque champ afin qu'un tel ensemble de données puisse être correctement mappé. Cette fois, j'ai défini le mappage suivant. C'est une image que la cartographie du type d'ensemble de données appelé géo est définie.
geo_mapping.json
{
"geo" : {
"properties" : {
"id" : {
"type" : "integer"
},
"uuid" : {
"type" : "string",
"index" : "not_analyzed"
},
"time" : {
"type" : "date",
"format" : "date_time"
},
"location" : {
"type" : "geo_point"
},
"accuracy" : {
"type" : "double"
}
}
}
}
Pour expliquer un peu, le champ uuid est défini sur `` not_analyzed '' car c'est une valeur unique et vous ne souhaitez pas l'analyser morphologiquement. Le type de champ de localisation est également important cette fois. geo_point est un type fourni par Elasticsearch, et la longitude et la latitude sont enregistrées comme un ensemble. Vous pouvez l'utiliser en faisant. En définissant le type de ce champ, vous pouvez rechercher facilement. Plus à ce sujet plus tard.
Une fois que vous avez créé les paramètres de mappage, utilisez-les pour créer l'index. Le nom de l'index est cette fois `` test_geo ''. Si vous lancez la boucle suivante pendant qu'Elasticsearch est en cours d'exécution, la création est terminée.
Créer un index
curl -XPOST 'localhost:9200/test_geo' -d @geo_mapping.json
Enregistrement des données
En supposant que vous disposez des données sous forme de fichier journal, enregistrez les données dans l'index créé à partir du fichier journal. Il y a un client python officiel cette fois, alors utilisons-le.
--Official: [elasticsearch-py] (https://www.elastic.co/guide/en/elasticsearch/client/python-api/current/index.html)
C'est facile à installer avec pip.
Installation
pip install elasticsearch
Le programme à enregistrer à l'aide de celui-ci est le suivant.
regist_es.py
import json
import sys
from elasticsearch import Elasticsearch
es = Elasticsearch()
index = "test_geo"
doc_type = "geo"
f = open('var/logs.json', 'r')
_line = f.readline()
while _line:
data = json.loads(_line)
_line = f.readline()
f.close()
for value in data:
lat = value['lat']
lon = value['lng']
del value['lat']
del value['lng']
value.update({
"location" : {
"lat" : lat,
"lon" : lon
}
})
es.index(index=index, doc_type=doc_type, body=value, id=value['id'])
Le point à noter est que lat et `` lon sont combinés en location afin de le rendre approprié pour `` `` geo_point. ..
Si vous exécutez ce programme, les informations d'historique des actions dans logs.json seront enregistrées dans Elasticsearch. C'est très facile.
Visualisé avec Kibana
Maintenant que les données ont été enregistrées, il est temps de faire bouillir ou cuire au four. Kibana est un outil de visualisation officiel qui visualise les données enregistrées dans Elasticsearch. Kibana4 est maintenant disponible, donc je pense que c'est une bonne idée d'obtenir la dernière version. Une fois que vous l'avez, exécutez simplement ``. / Bin / kibana``` et le serveur HTTP démarrera sur le port 5601. Méthode de paramétrage détaillée, etc.. Après l'avoir démarré, vous pouvez configurer le tableau de bord en y accédant avec un navigateur approprié. En jouant avec, vous pouvez facilement créer une carte thermique comme celle ci-dessous.
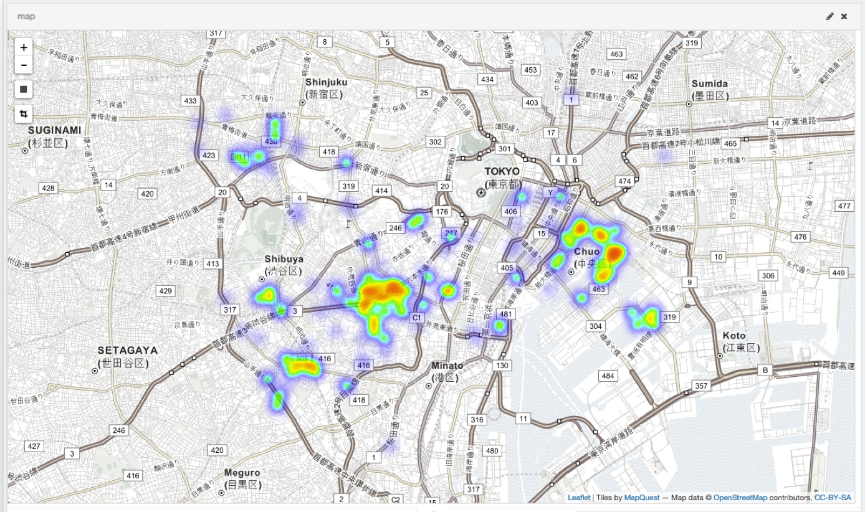

Estimation de la surface habitable
Puisque j'ai enregistré les données avec beaucoup d'efforts, je vais essayer de les utiliser. Cette fois, dans cet article (Système de recommandation d'information utilisant les informations de localisation pour les terminaux mobiles) Je vais essayer d'estimer la surface habitable. Puisque les informations de localisation sont enregistrées avec `` geo_type '', la requête suivante telle que l'acquisition de données à quelques kilomètres d'un emplacement spécifique peut être lancée.
python
query = {
"from":0,
"query": {
"filtered" : {
"query" : {
"simple_query_string" : {
"query" : uuid,
"fields" : ["uuid"],
}
},
"filter" : {
"geo_distance" : {
"distance" : 10 + 'km',
"geo.location" : {
"lat" : lat,
"lon" : lon
}
}
}
}
}
}
Les résultats de l'estimation de la surface habitable à l'aide de cette méthode sont les suivants.
Exemple de résultat
Stage1
35.653945 , 139.716692
rayon(km): 5.90
Stage2
35.647367 , 139.709346
rayon(km): 1.61
Lors de l'utilisation du centre de gravité
35.691165 , 139.709840
rayon(km): 8.22
Le midi: (104)
35.696822 , 139.708228
rayon(km): 9.61
Nuit: (97)
35.685100 , 139.711568
rayon(km): 6.77
Station la plus proche(Le midi):Higashi Shinjuku
Station la plus proche(Nuit):Shinjuku Gyoenmae
Impressions
Elasticsearch est très simple à mettre en place et à utiliser. Elasticsearch est incroyable. Kibana est incroyable. De plus, il semble y avoir un nouveau produit (Beats). Cela dépend de la quantité de données, mais il est pratique de s'inscrire auprès d'Elasticsearch pour le moment. Les journaux peuvent être automatiquement enregistrés avec fluentd, il semble donc que vous puissiez faire diverses choses en les combinant.
_ Difficile d'écrire des articles ... _